[論文レビュー] Learning Generalized Zero-Shot Learners for Open-Domain Image Geolocalization
StreetCLIPは、オープンドメインの画像地理位置推定の汎化ゼロショット学習を改善するために、合成キャプションに基づくドメイン特化の事前学習を利用し、ファインチューニングなしで最先端のゼロショット成果を達成します。
Image geolocalization is the challenging task of predicting the geographic coordinates of origin for a given photo. It is an unsolved problem relying on the ability to combine visual clues with general knowledge about the world to make accurate predictions across geographies. We present $\href{https://huggingface.co/geolocal/StreetCLIP}{ ext{StreetCLIP}}$, a robust, publicly available foundation model not only achieving state-of-the-art performance on multiple open-domain image geolocalization benchmarks but also doing so in a zero-shot setting, outperforming supervised models trained on more than 4 million images. Our method introduces a meta-learning approach for generalized zero-shot learning by pretraining CLIP from synthetic captions, grounding CLIP in a domain of choice. We show that our method effectively transfers CLIP's generalized zero-shot capabilities to the domain of image geolocalization, improving in-domain generalized zero-shot performance without finetuning StreetCLIP on a fixed set of classes.
研究の動機と目的
- オープンドメインの画像地理位置推定と地理を超えた一般化の課題を動機づける。
- CLIPを地理位置推定の合成キャプションで基づけるドメイン特化の事前学習法を導入する。
- StreetCLIPを開発し、ゼロショットの惑星規模推論を可能にする階層的リニアプロービング戦略を導入する。
- 合成キャプションの事前学習が、ゼロショットCLIPより汎化ゼロショット性能を向上させることを示す。
- より広い研究を可能にするため、公開可能なStreetCLIPモデルとデータセットを提供する。
提案手法
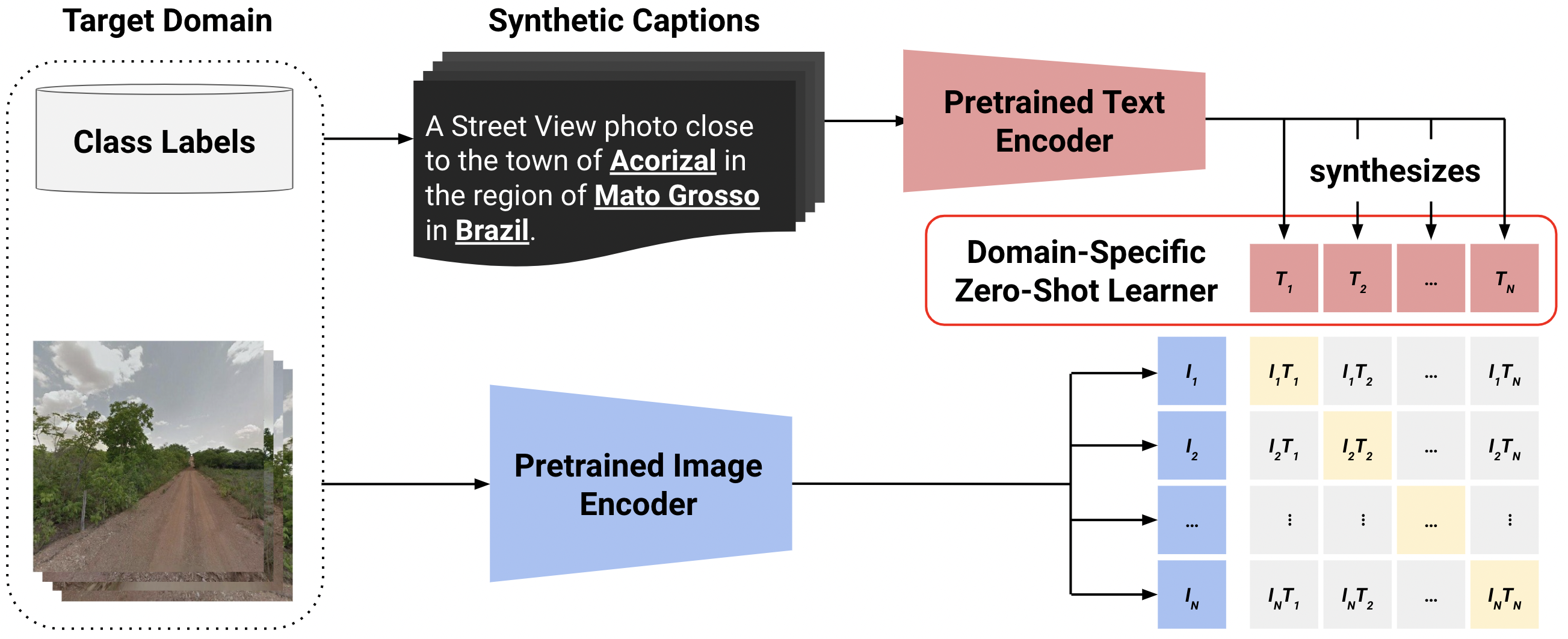
- 地理位置テンプレートから派生した合成キャプションを用いてCLIPを事前学習し、各トレーニングバッチでドメイン特化の汎化ゼロショット学習器を作成する。
- CLIPの損失を generalized-zero-shot loss (GZSL) と vision-representation alignment の組み合わせとして定式化し、GZSLのメタ学習を可能にする。
- 1.1MのStreet View画像データセットを都市/地域/国レベルのラベルでさらに事前学習させることでStreetCLIPを作成する。
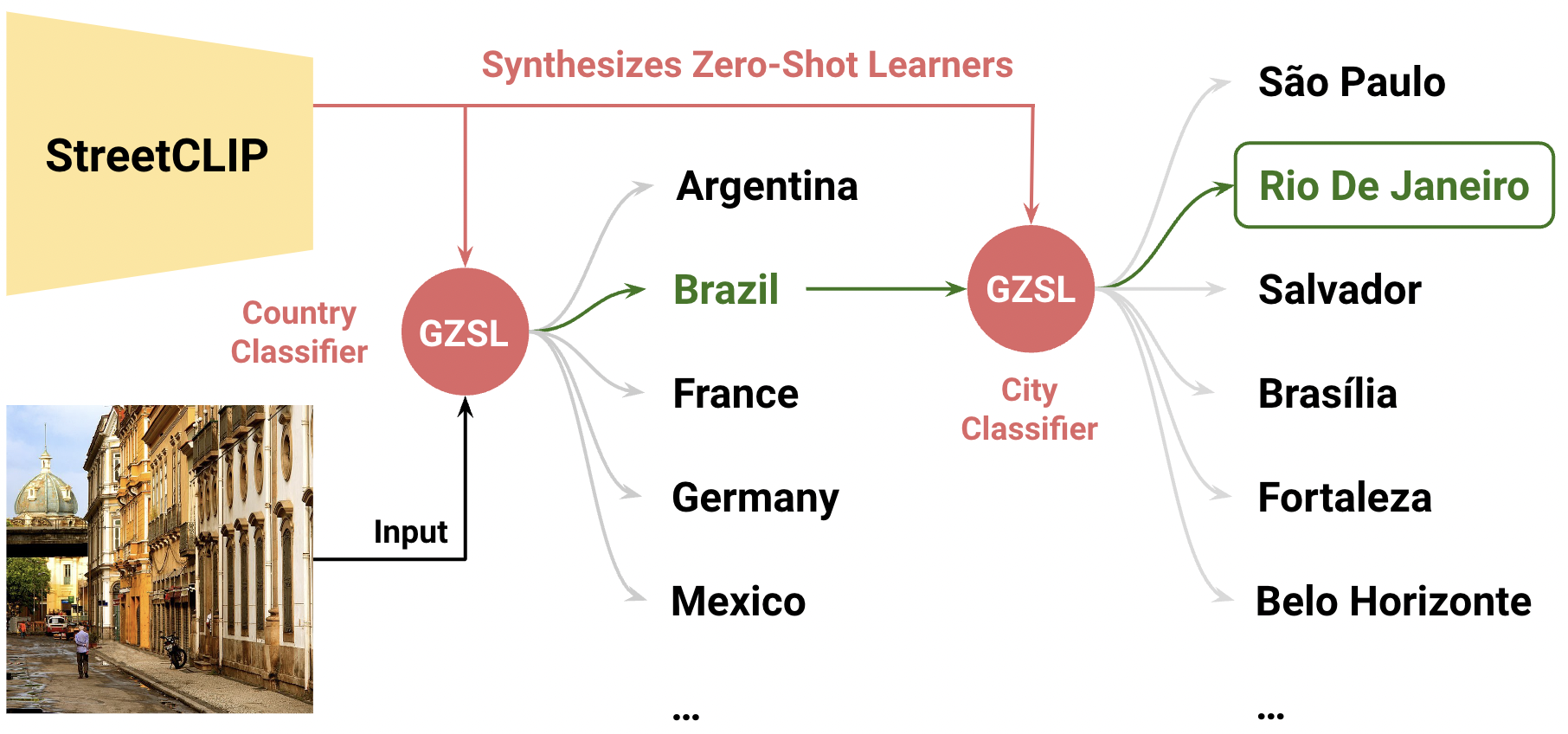
- 推論時に階層的リニアプロービングを適用し、まず国を予測し、各国の上位30都市内で市を精緻化する。
- 地理的知識に基づくよう、ドメイン特化のプロンプトを用いて標準のCLIPバックボーンを用いる。
実験結果
リサーチクエスチョン
- RQ1タスク固有のファインチューニングを用いずに、オープンドメインの画像地理位置推定における汎化ゼロショット学習をどう改善できるか?
- RQ2ドメイン特化の合成キャプションはCLIPを地理位置推定タスクへゼロショット機能の転移を実現できるか?
- RQ3階層的プロービングは、オープンドメイン地理位置推定で推論を高速化し、精度を保つまたは向上させるか?
- RQ4ODIGベンチマークで、合成キャプションを用いたドメイン特化の事前学習が、素のCLIPに対してどの程度性能向上をもたらすか?
主な発見
| ベンチマーク | モデル | 都市 | 地域 | 国 | 大陸 |
|---|---|---|---|---|---|
| IM2GPS | PlaNet Weyand et al. (2016) | 24.5 | 37.6 | 53.6 | 71.3 |
| IM2GPS | ISNs Müller-Budack et al. (2018) | 43.0 | 51.9 | 66.7 | 80.2 |
| IM2GPS | TransLocator Pramanick et al. (2022) | 48.1 | 64.6 | 75.6 | 86.7 |
| IM2GPS | Zero-Shot CLIP (ours) | 27.0 | 42.2 | 71.7 | 86.9 |
| IM2GPS | Zero-Shot StreetCLIP (ours) | 28.3 | 45.1 | 74.7 | 88.2 |
| IM2GPS | Δ StreetCLIP - CLIP | +1.3 | +2.9 | +3.0 | +1.3 |
| IM2GPS3K | PlaNet Weyand et al. (2016) | 24.8 | 34.3 | 48.4 | 64.6 |
| IM2GPS3K | ISNs Müller-Budack et al. (2018) | 28.0 | 36.6 | 49.7 | 66.0 |
| IM2GPS3K | TransLocator Pramanick et al. (2022) | 31.1 | 46.7 | 58.9 | 80.1 |
| IM2GPS3K | Zero-Shot CLIP (ours) | 19.5 | 34.0 | 60.0 | 78.1 |
| IM2GPS3K | Zero-Shot StreetCLIP (ours) | 22.4 | 37.4 | 61.3 | 80.4 |
| IM2GPS3K | Δ StreetCLIP - CLIP | +2.9 | +3.4 | +1.3 | +2.3 |
- StreetCLIPは、ゼロショット推論下でIM2GPSおよびIM2GPS3Kのオープンドメイン地理位置推定ベンチマークで最先端の性能を達成します。
- 合成キャプションのドメイン特化事前学習は、距離閾値を超えた場合で、ゼロショットCLIPと比べて1.3〜3.4ポイントの利得をもたらします。
- StreetCLIPは、特定の閾値で、400万枚超の画像で学習した教師付きモデルを上回ります。
- 階層的プロービングは、大きな距離閾値で特に効率と精度を向上させます。
- StreetCLIPは、ドメイン特化のグラウンドを活用しつつゼロショット機能を維持しており、他のドメインへ広く適用できることを示唆します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。