[論文レビュー] Learning Interactive Real-World Simulators
この論文は、多様なインターネットデータセットを組み合わせて現実世界の相互作用を模擬し、リアルデータの追加トレーニングなしで転移する視覚-言語および強化学習ポリシーを訓練する普遍的なアクション条件付きビデオ拡散モデル UniSim を提案します。
Generative models trained on internet data have revolutionized how text, image, and video content can be created. Perhaps the next milestone for generative models is to simulate realistic experience in response to actions taken by humans, robots, and other interactive agents. Applications of a real-world simulator range from controllable content creation in games and movies, to training embodied agents purely in simulation that can be directly deployed in the real world. We explore the possibility of learning a universal simulator (UniSim) of real-world interaction through generative modeling. We first make the important observation that natural datasets available for learning a real-world simulator are often rich along different dimensions (e.g., abundant objects in image data, densely sampled actions in robotics data, and diverse movements in navigation data). With careful orchestration of diverse datasets, each providing a different aspect of the overall experience, we can simulate the visual outcome of both high-level instructions such as "open the drawer" and low-level controls from otherwise static scenes and objects. We use the simulator to train both high-level vision-language policies and low-level reinforcement learning policies, each of which can be deployed in the real world in zero shot after training purely in simulation. We also show that other types of intelligence such as video captioning models can benefit from training with simulated experience, opening up even wider applications. Video demos can be found at https://universal-simulator.github.io.
研究の動機と目的
- 多様なデータソースを融合できる普遍的なアクション条件付き実世界シミュレータの必要性を動機づける。
- 予測観察モデルを学習する統一的なアクション-in-ビデオ-out フレームワークを提案する。
- 長時間・多模態のシミュレーションが現実のロボットへ転用可能な高レベルおよび低レベルのポリシーを訓練できることを示す。
- シミュレートデータで動画キャプション作成や広範な視覚言語モデルなどの追加アプリケーションを示す。
提案手法
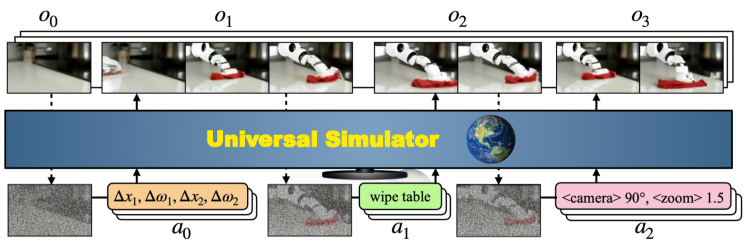
- テキスト、言語記述、モータ制御を連続埋め込みに変換して統一的なアクション空間を定式化する。
- ノイズ除去ネットワーク ε_θ を持つビデオ拡散モデルを用いて観測予測モデル p(o_t|h_{t-1},a_{t-1}) として UniSim を訓練する。
- 最近の履歴フレームで拡張条件付けを行い自己回帰的長距離ビデオ生成を可能にする。
- 拡張プロセスにアクション条件を組み込むために分類子なしガイダンスを使用する。
- 将来のステップに条件付けフレームを複製し、時間的・空間的注意機構を交互に持つビデオ U-Net アーキテクチャを適用する。
- 実ロボット、ヒューマンアクティビティ、パノラマ、インターネット画像-テキストデータセットの組み合わせで訓練し、ドメイン識別子を低データドメインの助けとする。

実験結果
リサーチクエスチョン
- RQ1アクション条件付きの単一のビデオ拡散モデルは多様なデータセットを統合して現実世界の相互作用を現実的に模倣できるか?
- RQ2長距離シミュレーションは現実のタスクへ転用可能な高レベルの視覚言語ポリシーと低レベルの強化学習コントローラの効果的な訓練を可能にするか?
- RQ3シミュレートデータは動画キャプション作成や広範な視覚言語モデルのような非搭載タスクを改善できるか?
- RQ4現在の普遍的シミュレータのメモリ、アクションのリアリズム、領域外一般化などの限界は何か?
主な発見
- UniSim は操作の豊富な長期シミュレーションを任意の操作と組み合わせて実現できる。
- 自己回帰拡散に基づく観測予測は、アクションに条件付けられた時間的一貫性のあるビデオ列を生成する。
- 視覚言語ポリシーと強化学習コントローラを完全にシミュレーションで訓練して、ゼロショット展開で現実のロボットへ転送できる。
- シミュレートデータは動画キャプションモデルを改善し、長距離タスクのためのシミュレートした hindsight データの価値を高める。
- 履歴フレームの条件付けは生成品質を向上させるが、遠すぎる履歴は性能を低下させることがある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。