[論文レビュー] Learning Mask-aware CLIP Representations for Zero-Shot Segmentation
本研究は、マスク提案を識別可能にするCLIPのマスク認識型微調整フレームワーク MAFT を提案し、ゼロショットセグメンテーションを改善しつつ移植性を保つ。
Recently, pre-trained vision-language models have been increasingly used to tackle the challenging zero-shot segmentation task. Typical solutions follow the paradigm of first generating mask proposals and then adopting CLIP to classify them. To maintain the CLIP's zero-shot transferability, previous practices favour to freeze CLIP during training. However, in the paper, we reveal that CLIP is insensitive to different mask proposals and tends to produce similar predictions for various mask proposals of the same image. This insensitivity results in numerous false positives when classifying mask proposals. This issue mainly relates to the fact that CLIP is trained with image-level supervision. To alleviate this issue, we propose a simple yet effective method, named Mask-aware Fine-tuning (MAFT). Specifically, Image-Proposals CLIP Encoder (IP-CLIP Encoder) is proposed to handle arbitrary numbers of image and mask proposals simultaneously. Then, mask-aware loss and self-distillation loss are designed to fine-tune IP-CLIP Encoder, ensuring CLIP is responsive to different mask proposals while not sacrificing transferability. In this way, mask-aware representations can be easily learned to make the true positives stand out. Notably, our solution can seamlessly plug into most existing methods without introducing any new parameters during the fine-tuning process. We conduct extensive experiments on the popular zero-shot benchmarks. With MAFT, the performance of the state-of-the-art methods is promoted by a large margin: 50.4% (+ 8.2%) on COCO, 81.8% (+ 3.2%) on Pascal-VOC, and 8.7% (+4.3%) on ADE20K in terms of mIoU for unseen classes. The code is available at https://github.com/jiaosiyu1999/MAFT.git.
研究の動機と目的
- 凍結された CLIP がゼロショットセグメンテーションにおいて異なるマスク提案に対して鈍感である問題に対処する。
- CLIP の転送性を保持するマスク認識型微調整法を開発する。
- 既存の凍結 CLIP セグメンテーションパイプラインへの MAFT の効率的なプラグアンドプレー統合を可能にする。
提案手法
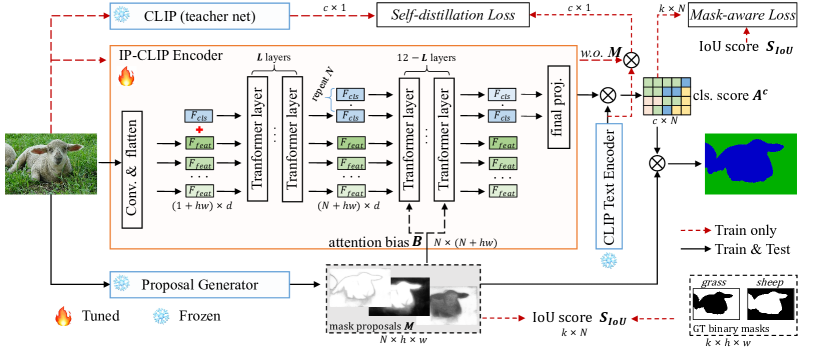
- Masked multi-head attention によって任意の画像数とマスク提案を処理する Image-Proposals CLIP Encoder (IP-CLIP Encoder) を導入する。
- CLIP が予測する提案スコアを IoU ベースの品質信号と一致させるようマスク認識型損失を設計する。
- 凍結された CLIP 教師と IP-CLIP の出力を整合させることで CLIP のゼロショット転送性を維持する自己蒸留損失を導入する。
- 軽量な MAFT プロセスで IP-CLIP Encoder のみを微調整する(Proposal Generator と CLIP Text Encoder は凍結のまま)。
- 既存の凍結 CLIP ゼロショットセグメンテーション手法に追加できるプラグアンドプレー方式を提供する。
- 異なるバックボーンとオープンボキャブラリ設定に対する堅牢性を示す。

実験結果
リサーチクエスチョン
- RQ1CLIP のマスク提案に対する感度はゼロショットセグメンテーションの性能にどのように影響するか?
- RQ2転送性を損なうことなく提案分類を改善するマスク認識型微調整 regime は可能か?
- RQ3IP-CLIP Encoder は任意の数の提案を効率的に処理できるか?
- RQ4MAFT は標準的なゼロショットセグメンテーションのベンチマークとオープンボキャブラリ設定全体で性能を向上させるか?
主な発見
- MAFT は既存の手法に組み込むと unseen-class の mIoU を標準ベンチマークで大幅に改善する。
- IP-CLIP Encoder が、マスク認識型訓練を備えることで CLIP を様々な提案に対して異なる反応をさせ、false positives を減らす。
- 自己蒸留は転送性を維持しつつマスク認識型微調整を可能にする。
- MAFT は複数の CLIP バックボーンに対応し、オープンボキャブラリセグメンテーションへ拡張して有意な利得を得られる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。