[論文レビュー] Learning to Tokenize for Generative Retrieval
GenRet は離散オートエンコーディングを介して意味的なドキュメント識別子(docids)を学習し、エンドツーエンドの生成的検索を可能にし、NQ320Kで最先端を達成し、MS MARCOとBEIRで強い結果を出す。
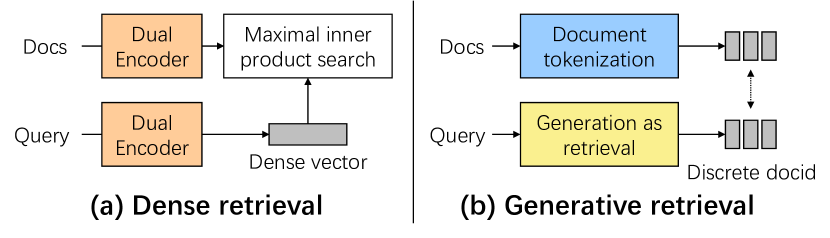
Conventional document retrieval techniques are mainly based on the index-retrieve paradigm. It is challenging to optimize pipelines based on this paradigm in an end-to-end manner. As an alternative, generative retrieval represents documents as identifiers (docid) and retrieves documents by generating docids, enabling end-to-end modeling of document retrieval tasks. However, it is an open question how one should define the document identifiers. Current approaches to the task of defining document identifiers rely on fixed rule-based docids, such as the title of a document or the result of clustering BERT embeddings, which often fail to capture the complete semantic information of a document. We propose GenRet, a document tokenization learning method to address the challenge of defining document identifiers for generative retrieval. GenRet learns to tokenize documents into short discrete representations (i.e., docids) via a discrete auto-encoding approach. Three components are included in GenRet: (i) a tokenization model that produces docids for documents; (ii) a reconstruction model that learns to reconstruct a document based on a docid; and (iii) a sequence-to-sequence retrieval model that generates relevant document identifiers directly for a designated query. By using an auto-encoding framework, GenRet learns semantic docids in a fully end-to-end manner. We also develop a progressive training scheme to capture the autoregressive nature of docids and to stabilize training. We conduct experiments on the NQ320K, MS MARCO, and BEIR datasets to assess the effectiveness of GenRet. GenRet establishes the new state-of-the-art on the NQ320K dataset. Especially, compared to generative retrieval baselines, GenRet can achieve significant improvements on the unseen documents. GenRet also outperforms comparable baselines on MS MARCO and BEIR, demonstrating the method's generalizability.
研究の動機と目的
- 従来の index-retrieve パイプラインを超えるエンドツーエンドの文書検索を動機づける。
- 生成的検索のための固定ルールベースのトークナイザを超えた文書識別子の定義という課題に対処する。
- 文書の意味を保持する離散オートエンコーディングトークナイズフレームワークを提案する。
- トークナイズ、再構築、検索コンポーネントのエンドツーエンド最適化を可能にする。
- NQ320K、MS MARCO、BEIR など多様なデータセットでの一般化性を示す。
提案手法
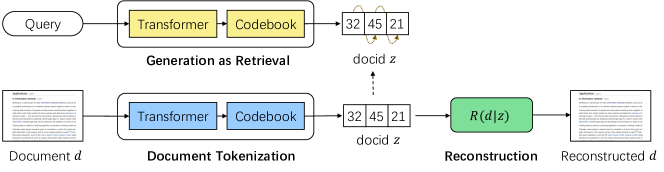
- 文書を docids にマッピングするトークナイゼーションモデル Q、docids から元の文書を再生成する再構築モデル R、クエリから docids を生成する検索モデル P の3つの構成要素を備えた GenRet を導入する。
- トークナイゼーションと検索のために共有された T5 ベースのアーキテクチャを使用し、時刻ごとにサイズ K の離散潜在コードブックを用いる(K=512)。
- 再構成損失、コミットメント損失、検索損失を含むオートエンコoding objective で docids を文書意味とクエリベースの検索に整合させる。
- 前方の prefix を固定して学習を安定化させつつ、docids を自己回帰的に最適化する段階的訓練手法を採用する。
- コードブックの初期化と Sinkhorn-Knopp による docid の再割り当てなど、多様なクラスタリング手法を取り入れ、docid の多様性と意味空間のバランスの取れた分割を促進する。
- 制約付きデコードを適用して生成される docids がコーパス内で有効であることを保証し、検索にはビーム探索を用いる。
実験結果
リサーチクエスチョン
- RQ1生成的検索のための固定ルールベースのトークンよりも、学習済みの離散トークン化(docids)が意味情報をより効果的に捉えることができるのか?
- RQ2トークナイゼーション、再構築、検索をエンドツーエンドで訓練すると、特に未知の文書で検索性能が向上するのか?
- RQ3自己回帰的 docid 生成を安定させ、精度を犠牲にせず docid 割り当ての多様性を促進するにはどうすればよいのか?
- RQ4GenRet の学習済み docids は学習分布外のデータセット(MS MARCO および BEIR など)へ一般化できるのか?
主な発見
- GenRet は NQ320K で新しい最先端を達成し、未知のテストデータでの相対的な改善が大きい(R@1 の最良の生成基線より +14% の相対改善)。
- GenRet は MS MARCO および BEIR で既存の生成的検索のベースラインを上回り、強い一般化性を示す。
- オートエンコーディング・トークナイゼーションフレームワークは、訓練時に見られなかった文書を再構成できる意味的に意味ある docids を生成し、検索精度を向上させる。
- 段階的訓練と多様な docid クラスタリングは訓練を安定化させ、docid の多様性を高め、自己回帰的学習とトークン割り当ての課題に対処する。
- ルールベースのトークナイザと比較して、GenRet は未知の文書をより良く表現・検索でき、分布外データに対するロバスト性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。