[論文レビュー] Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
本論文は回帰ベースのデバイアス除去手法を提示し、AlpacaEval の長さバイアスを除去して AlpacaEval-LC を作成する。これにより人間のランキングとの整合性が高まり、冗長性の指標に対する頑健性が向上する。
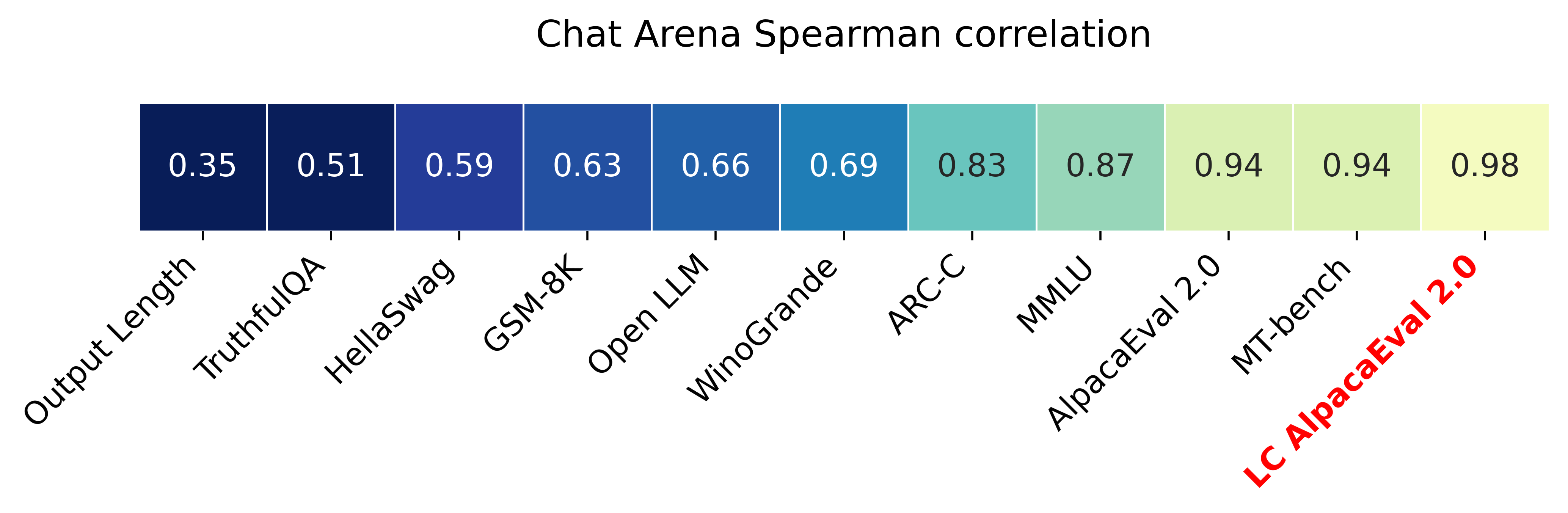
LLM-based auto-annotators have become a key component of the LLM development process due to their cost-effectiveness and scalability compared to human-based evaluation. However, these auto-annotators can introduce biases that are hard to remove. Even simple, known confounders such as preference for longer outputs remain in existing automated evaluation metrics. We propose a simple regression analysis approach for controlling biases in auto-evaluations. As a real case study, we focus on reducing the length bias of AlpacaEval, a fast and affordable benchmark for instruction-tuned LLMs that uses LLMs to estimate response quality. Despite being highly correlated with human preferences, AlpacaEval is known to favor models that generate longer outputs. We introduce a length-controlled AlpacaEval that aims to answer the counterfactual question: "What would the preference be if the model's and baseline's output had the same length?" To achieve this, we first fit a generalized linear model to predict the biased auto-annotator's preferences based on the mediators we want to control for (length difference) and other relevant features. We then obtain length-controlled preferences by predicting preferences while conditioning the GLM with a zero difference in lengths. Length-controlling not only improves the robustness of the metric to manipulations in model verbosity, but we also find that it increases the Spearman correlation with LMSYS Chatbot Arena from 0.94 to 0.98.
研究の動機と目的
- チャット LLM の自動評価における不必要な長さに基づくバイアスを削減する。
- AlpacaEval の望ましい特性を保ちながら、シンプルで解釈可能なデバイアッシング手法を提供する。
- 人間の判断(Chatbot Arena)との相関を改善し、冗長性の変更によるゲーム性への頑健性を高める。
- リーダーボードや RLHF コンテキストで利用可能なデバイアスを取り除いた、アクセスしやすい評価フレームワークを提供する。
提案手法
- 出力のモデル識別子、出力長、指示難易度という3つの要素を用いて自動評価者の嗜好を予測する一般化線形モデルを適合させる。
- 規格化された長さの差の tanh によってモデル化された長さ項を用いたロジスティック回帰を用い、逓減効果を捉える。
- 長さ項を除去して長さ制御済みの勝率を得る。これにより出力が等長となるような反事実推定を得る。
- 新しいモデルを追加する際の頑健性を確保するため、交差検証付きの L2 正則化適合と、モデル固有の係数を別個に学習する。
- 長さ結合項に対する緩やかな正則化を組み込み、敵対的な切り捨て攻撃に対抗する。
- LC 勝率を直感的な反事実的枠組みを用いた標準的な勝率として解釈し、リーダーボード上の任意の2つのモデル間での対ペア予測を可能にする。
実験結果
リサーチクエスチョン
- RQ1出力長が AlpacaEval の判断をどれだけ混乱させる(混同させる)か。
- RQ2長さ関連の分散を除去しつつ、モデル識別性とタスク難易度の効果を保持する回帰ベースのデバイアッシング手法は可能か。
- RQ3長さ制御された AlpacaEval(AlpacaEval-LC)は、元の指標よりも人間の評価(Chatbot Arena)との相関が高くなるか。
- RQ4AlpacaEval-LC は出力切り捨てなどの単純な敵対的ゲームに頑健か。
主な発見
- AlpacaEval-LC は元の AlpacaEval と比較して長さベースのゲーム性への感度を低減する。
- AlpacaEval-LC は Chatbot Arena とのスピアマン相関を 0.94 から 0.98 に向上させる。
- 長さ制御は、短くなりがちな商用モデルのリーダーボード順位を改善し、オープンソースモデルは相対的に不利になる。
- GLM ベースのデバイアシングは勝率として解釈可能なままで、リーダーボードベースライン間の対ペア予測が可能である。
- 正則化は敵対的な切り捨て攻撃を低減しつつ、標準モデルでの性能を維持する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。