[論文レビュー] Lessons from the Trenches on Reproducible Evaluation of Language Models
堅牢で再現性の高い言語モデル評価のベストプラクティスを提供し、Language Model Evaluation Harness (lm-eval) を導入して、タスクとモデル全体にわたるLM評価をオーケストレーション、再現、拡張する。
Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
研究の動機と目的
- 大規模言語モデルの評価における共通の課題を特定する(精度と意味的同等性、ベンチマークの妥当性、実装の再現性)。
- LM評価の厳密さと透明性を高めるためのベストプラクティスの提案(プロンプト、出力、不確実性、定性的分析)。
- Language Model Evaluation Harness (lm-eval) の設計と機能を説明し、再現性が高く拡張可能な評価を可能にする。
提案手法
- 主要な問題の概説:意味的同等性と統語的変動の対立、および人間評価と自動評価の限界。
- 評価報告のベストプラクティスを議論。正確なプロンプトの共有、他論文の結果のコピーを避ける、モデル出力の提供、定性的分析、不確実性の測定を含む。
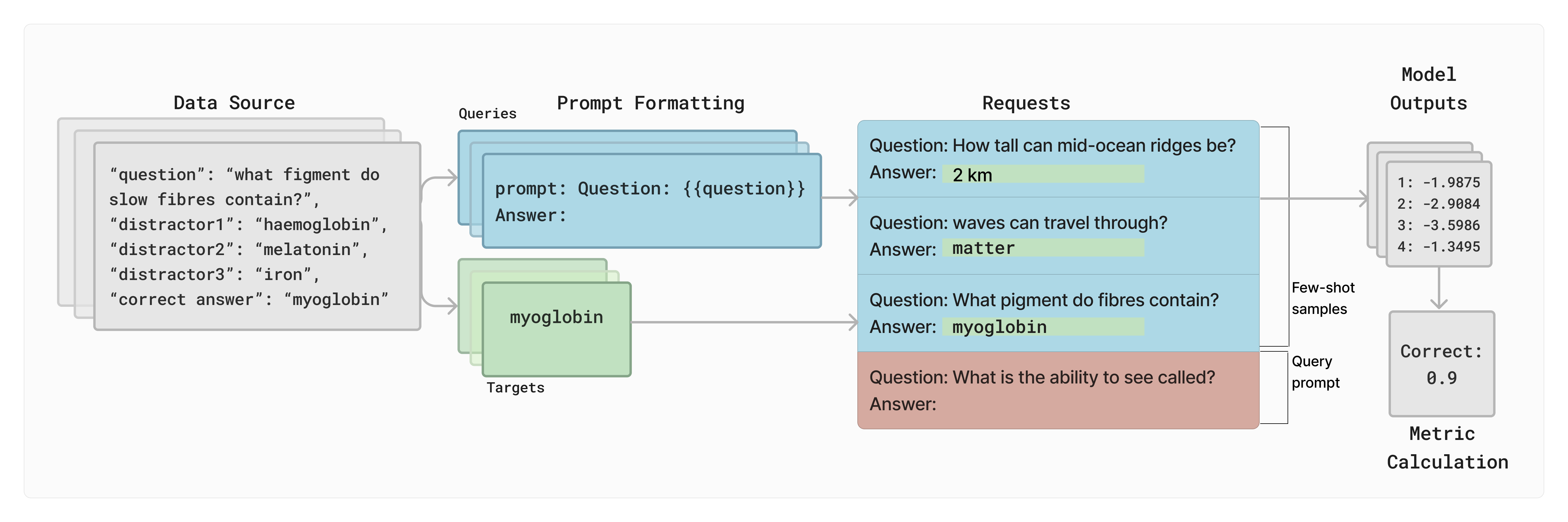
- lm-eval のアーキテクチャとインターフェースを提示。Task クラス、LM API、3つの主要なリクエストタイプ(条件付き対数尤度、困惑度、生成)を含む。
- versioned tasks と標準化された評価ワークフローを通じて再現性をどのように保証するかを説明。
- 事例研究を提供(BigScience のプロンプト分布;評価設定の感度)により、lm-eval が評価の頑健性と prompting 効果を明らかにする能力を示す。
実験結果
リサーチクエスチョン
- RQ1評価設定の選択はベンチマーク全体での言語モデルの性能指標にどのように影響するか?
- RQ2評価バイアスを軽減し、LMベンチマークの再現性を高めるためのベストプラクティスは何か?
- RQ3lm-eval のようなオーケストレーションライブラリは、モデルとタスクを横断した公正で拡張性が高く透明な評価をどのように合理化できるか?
主な発見
| Model | ARC Cloze (0-shot) | ARC MMLU-style (0-shot) | MMLU-style (0-shot) | Hybrid (MMLU-style prompts with answer strings) |
|---|---|---|---|---|
| GPT-NeoX-20B | 38.0±2.78% | 26.6±2.53% | 24.5±0.71% | 27.6±0.74% |
| Llama-2-7B | 43.5±2.84% | 42.8±2.83% | 41.3±0.80% | 39.8±0.79% |
| Falcon-7B | 40.2±2.81% | 25.9±2.51% | 25.4±0.72% | 29.1±0.75% |
| Mistral-7B | 50.1±2.86% | 72.4±2.56% | 58.6±0.77% | 48.3±0.80% |
| Mixtral-8x7B | 56.7±2.84% | 81.3±2.23% | 67.1±0.72% | 59.7±0.77% |
- 評価結果はプロンプトと評価設定に高度に敏感であり、標準化された再現性のあるツールが必要。
- 正確なプロンプト、コード、およびモデル出力の共有は再現性を大幅に改善し、公正な比較を可能にする。
- lm-eval は、タスクの抽象化と単純な LM インターフェースを備えたモジュラーで拡張可能なフレームワークを提供し、ベンチマーク全体の評価を統一する。
- 定性的分析と不確実性の報告(標準誤差、ブートストラッピング)を促進することで、スコアの解釈性が向上する。
- ケーススタディは、プロンプト分布と評価方法論が報告結果に大きく影響することを示し、堅牢な評価エコシステムの必要性を強調する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。