[論文レビュー] LEVER: Learning to Verify Language-to-Code Generation with Execution
Leverは、LLMが生成したコードを実行結果を用いて評価する verifier を訓練し、結合確率による候補の再ランキングを行うことで、タスク特化モデルを用いずに複数データセットにおける language-to-code 生成を改善します。
The advent of large language models trained on code (code LLMs) has led to significant progress in language-to-code generation. State-of-the-art approaches in this area combine LLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the LLMs is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the LLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base code LLMs(4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
研究の動機と目的
- コールコード LLM のパラメトリックなファインチューニングを行わずに language-to-code 生成を改善する動機づけ。
- NL の説明、候補プログラム、実行結果を用いて正確性を評価する verifier を提案する。
- 生成器の確率と verifier の Confidence を結合し、実行結果ごとに集約する再ランキング機構を開発する。
- table QA、math QA、基本的な Python プログラミングベンチマークでの利得を示す。
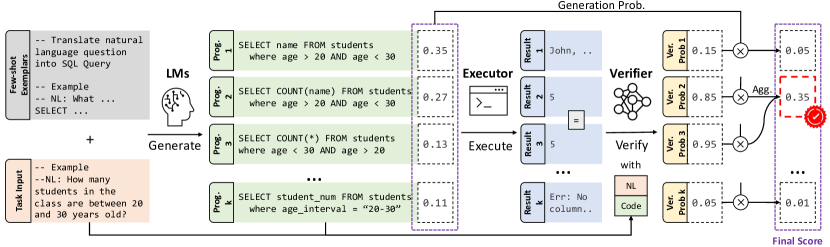
提案手法
- 入力 x と few-shot 例示を与えられたコード LLM から複数の候補プログラムをサンプルする。
- 各候補を実行して、実行結果を executor E(y) を介して取得する。
- プログラムの正確性を予測する二値 verifier P_theta(v|x, y, E(y)) を訓練する。
- 再ランキング得点を P_LM(y|x) * P_theta(v=1|x, y, E(y)) として計算し、同一の実行結果を持つプログラム間で集約する。
- 実行結果が同一の場合はランダムに結びつけを破って、最も高い総再ランキング得点を持つプログラムを選んで最終出力を推定する。
- 完全監視および弱監視の設定の両方で、ゴールド出力またはゴールド実行結果に対して候補をラベル付けすることで verifier を訓練する。
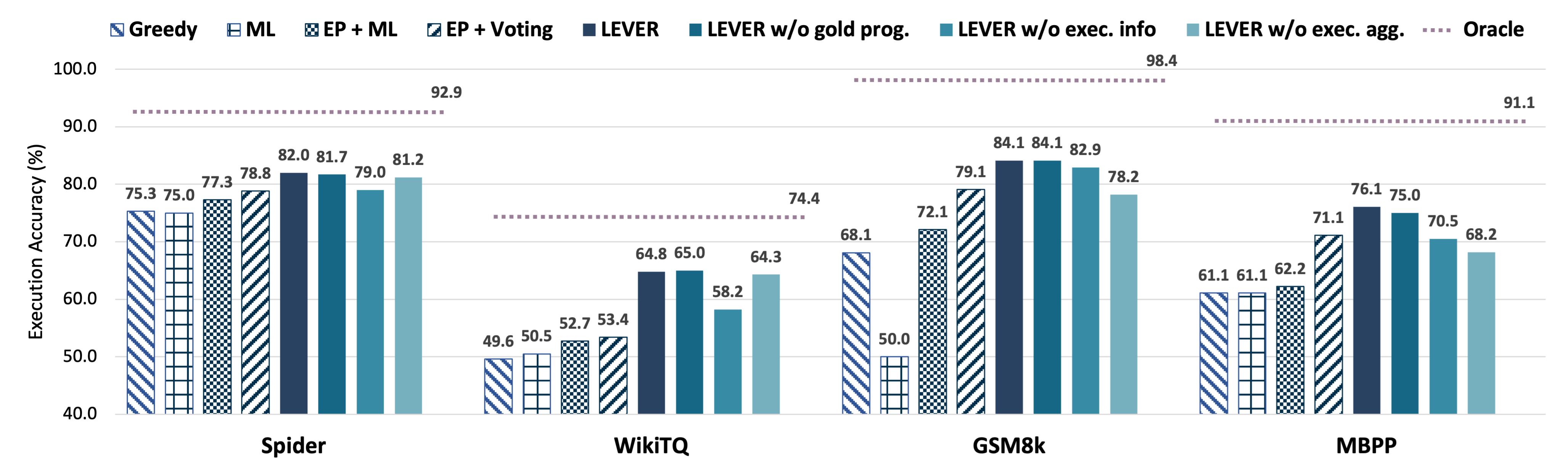
実験結果
リサーチクエスチョン
- RQ1実行結果を用いた学習済み verifier は、標準的なサンプリングおよびプリューニングベースラインより、language-to-code 生成を改善できるか?
- RQ2Lever は、多様なドメイン(table QA、math QA、Python プログラミング)および異なる code LLM バックボーンでどう性能を示すか?
- RQ3実行結果の含有と執行意味論による集約が再ランキング性能に与える影響は何か?
- RQ4低リソースまたは弱い監視設定下での Lever の性能はどうか?
主な発見
- Lever は Codex-Davinci、InCoder、CodeGen を用いた場合、4つのベンチマークすべてで実行正確性を一貫して改善する。
- Codex-Davinci-002 では、Lever は base baseline (EP+ML) に対してデータセット全体で 4.6% から 10.9% の改善を達成。
- Lever は Spider、WikiTQ、GSM8k、MBPP で、タスク特化型アーキテクチャやプロンプティング手法を用いず、新しい最先端結果を達成。
- アブレーションは、実行結果が検証にとって不可欠であることを示し、InCoder/CodeGen のような弱いモデルでも Lever が EP+ML を上回る。
- 実行結果によるプログラムの集約は Python ベースの出力には有効だが、SQL タスクには効果が混在し、データセット固有のダイナミクスを際立たせる。
- 弱監視設定でもほとんどの利得を維持し、いくつかのケースで最大で絶対値 1.1% の低下。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。