[論文レビュー] LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
LIBEROは、4つのタスクリストで130タスクを用い、知識移転、アーキテクチャ、アルゴリズム、事前学習を評価する、ロボット操作の終身学習のためのスケーラブルで手続き的に生成されるベンチマークを導入する。
Lifelong learning offers a promising paradigm of building a generalist agent that learns and adapts over its lifespan. Unlike traditional lifelong learning problems in image and text domains, which primarily involve the transfer of declarative knowledge of entities and concepts, lifelong learning in decision-making (LLDM) also necessitates the transfer of procedural knowledge, such as actions and behaviors. To advance research in LLDM, we introduce LIBERO, a novel benchmark of lifelong learning for robot manipulation. Specifically, LIBERO highlights five key research topics in LLDM: 1) how to efficiently transfer declarative knowledge, procedural knowledge, or the mixture of both; 2) how to design effective policy architectures and 3) effective algorithms for LLDM; 4) the robustness of a lifelong learner with respect to task ordering; and 5) the effect of model pretraining for LLDM. We develop an extendible procedural generation pipeline that can in principle generate infinitely many tasks. For benchmarking purpose, we create four task suites (130 tasks in total) that we use to investigate the above-mentioned research topics. To support sample-efficient learning, we provide high-quality human-teleoperated demonstration data for all tasks. Our extensive experiments present several insightful or even unexpected discoveries: sequential finetuning outperforms existing lifelong learning methods in forward transfer, no single visual encoder architecture excels at all types of knowledge transfer, and naive supervised pretraining can hinder agents' performance in the subsequent LLDM. Check the website at https://libero-project.github.io for the code and the datasets.
研究の動機と目的
- 意思決定における終身学習を動機づける:宣言的知識と手続き的知識の両方が移転される必要がある。
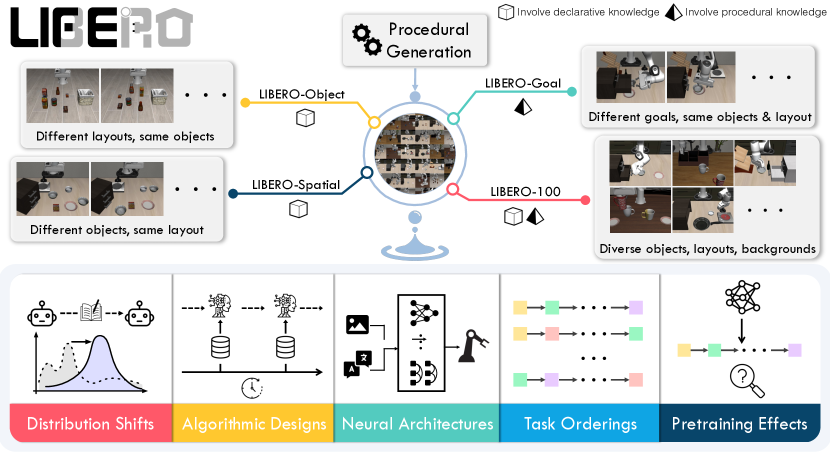
- 多様で言語条件付のロボット操作タスクを生成するスケーラブルなタスク生成パイプラインを提供する。
- 方針アーキテクチャ、終身学習アルゴリズム、事前学習の転送前後効果を体系的に評価する。
- タスク順序へのロバスト性とLLDM性能における言語埋め込みの役割を分析する。
提案手法
- Ego4Dの言語アノテーションから挙動テンプレートを抽出し、それをPDDLに符号化して無限のロボット操作タスクを手続き的に生成する。
- ビデオに基づく言語条件付きタスク指示をシーン配置と初期物体配置と組み合わせる。
- 4つのタスクスイート(LIBERO-Spatial、LIBERO-Object、LIBERO-Goal、LIBERO-100)と130タスクを複数のポリシーとLLアルゴリズムで評価する。
- テレオペレーションから収集したデモンストレーションでポリシーを訓練することで、サンプル効率の良いベンチマークを実現する。
- 新しいタスクを学習する際には以前のタスクへのアクセスを排除し、終身学習の制約を模擬する。
実験結果
リサーチクエスチョン
- RQ1さまざまな分布シフトの下で、異なるニューラルアーキテクチャと終身学習アルゴリズムはどう性能を発揮するか?
- RQ2特に空間・物体・目標知識におけるアーキテクチャの選択がLLDMの知識移転に与える影響はどうなるか?
- RQ3監視付き文献の既存の終身学習手法は、ロボティクスのLLDMに効果的に翻訳されるか?
- RQ4言語埋め込みの質やタスク識別子のエンコードはLLDMの性能に影響を与えるか?
- RQ5異なるタスク順序やLLDMにおける事前学習に対して、LLDM手法はどれだけロバストか?
主な発見
- 逐次微調整(SeqL)は、タスクスイートを横断して最良の前向き転移を達成し、前向き転移において専用のLLアルゴリズムを上回ることが多い。
- ER(リハーサル)はタスクスイートをまたいで堅牢であり、以前に学習したタスクの性能を一般的に保持し、いくつかの設定で他を上回る。
- PackNet(動的アーキテクチャ)はLIBERO-X(物体/空間の多様性)で優れるが、容量制約のためLIBERO-Longでは劣る。
- ViT系アーキテクチャ(ViT-T)と時系列処理のトランスフォーマーは、多くのタスクでResNet-RNNを上回る傾向があり、アーキテクチャ効果はLLアルゴリズムによって異なる。
- 言語埋め込み(BERT、CLIP、GPT-2、Task-ID)はLIBERO-Longで統計的有意差を生まない。現行の埋め込みはタスク識別子の語彙リストのように機能している。
- 基本的な监督付き事前学習は下流のLLDM性能を損なう可能性があることが示されており、より慎重な事前学習戦略が必要である。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。