[論文レビュー] Liger Kernel: Efficient Triton Kernels for LLM Training
Liger-Kernelは、LLMトレーニング用のTritonカーネルのオープンソースライブラリで、カーネル融合と入力チャンク化を用いてスループットを向上させ、HuggingFace実装と比較してGPUメモリ使用量を削減します。モジュラーなAPI、フレームワークとの容易な統合、複数モデルにわたるベンチマークを提供します。
Training Large Language Models (LLMs) efficiently at scale presents a formidable challenge, driven by their ever-increasing computational demands and the need for enhanced performance. In this work, we introduce Liger-Kernel, an open-sourced set of Triton kernels developed specifically for LLM training. With kernel optimization techniques like kernel operation fusing and input chunking, our kernels achieve on average a 20% increase in training throughput and a 60% reduction in GPU memory usage for popular LLMs compared to HuggingFace implementations. In addition, Liger-Kernel is designed with modularity, accessibility, and adaptability in mind, catering to both casual and expert users. Comprehensive benchmarks and integration tests are built in to ensure compatibility, performance, correctness, and convergence across diverse computing environments and model architectures. The source code is available under a permissive license at: github.com/linkedin/Liger-Kernel.
研究の動機と目的
- LLMトレーニングの効率を改善するためのカーネルレベルの最適化の必要性を喚起する。
- LLMsのためのモジュラーで使いやすいTritonカーネルライブラリとしてLiger-Kernelを紹介する。
- カーネル融合と入力チャンク化がメモリ削減とスループット向上につながることを示す。
- 人気のあるフレームワークとデプロイメント環境との互換性を示す。
- 正確性と収束性を保証するためのベンチマークと統合テストを提供する。
提案手法
- 共通操作の融合を重視したLLMトレーニング向けTritonカーネルのライブラリを提案する。
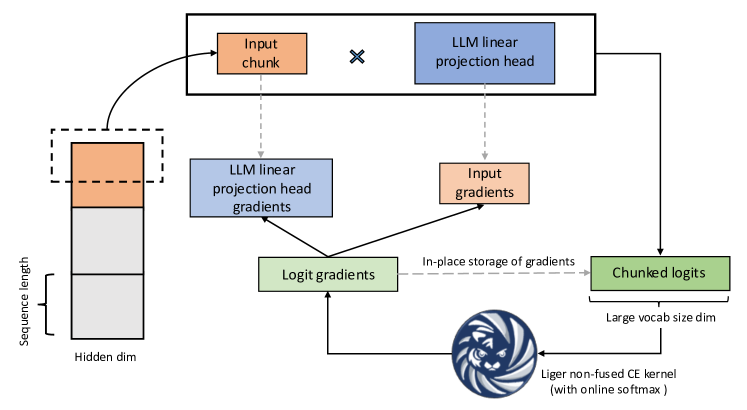
- RMSNorm、LayerNorm、RoPE、SwiGLU、GeGLU、CrossEntropy、および fused Linear+CrossEntropy (FLCE) アプローチのカーネル設計を説明する。
- AutoLigerKernelForCausalLM、モデル固有のパッチAPI、カスタムカーネルの組み合わせをサポートするAPI設計を説明する。
- 大規模語彙のロジットを計算する際のメモリ削減のためのチャンク化FLCEアプローチを提示する。
- 正確性、性能、収束性のためのテストのベストプラクティスを詳述し、連続性と大次元の処理を含む。
- Hugging Faceや他のフレームワークとのエンドツーエンドのベンチマーク設定と統合を要約する。
実験結果
リサーチクエスチョン
- RQ1Liger-Kernelのカーネルは、ベースラインのHuggingFace実装と比較してトレーニングのスループットを向上させ、GPUメモリを削減できますか?
- RQ2カーネル融合と入力チャンク化は、一般的なLLM操作のメモリ使用量と速度にどう影響しますか?
- RQ3PyTorch FSDP、DeepSpeed ZeRO、ZeRO++との統合は、Ligerカーネルを使用した場合に収束性と正確性を維持しますか?
- RQ4Liger-KernelのAPI設計は、初心者と上級者の両方にとって使いやすく、かつ高度に構成可能ですか?
- RQ5標準的なベンチマークで、複数のLLM(例:LLaMA、Qwen、Gemma、Mistral、Phi3)に対するエンドツーエンドの性能向上はどの程度ですか?
主な発見
- Liger-Kernelは、HuggingFace実装と比較して平均約20%のトレーニングスループット向上と60%のGPUメモリ削減を達成します。
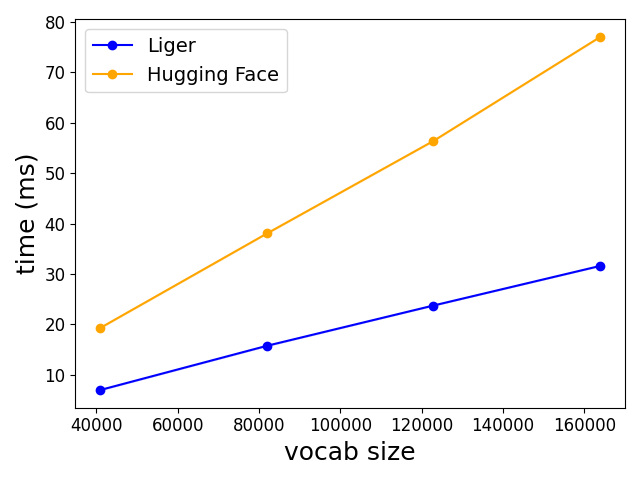
- CrossEntropyカーネルはオンラインソフトマックスとインプレース勾配置換を用いた場合、大規模語彙サイズで約3倍のスピードアップと約5倍のメモリ削減をもたらします。
- RMSNormとLayerNormカーネルは、正規化をスケーリングとキャッシュと統合して、計算時間を最大約7倍、メモリ影響は控えめに30%程度削減します。
- RoPEカーネルは、平坦化された繰り返しブロック回転行列を使用して効率を高め、大規模隠れ層サイズで約8倍のスピードアップと約3倍のメモリ節約を達成します。
- GeGLUと SwiGLUカーネルは、ベースラインと同等の速度を維持しつつ、長いシーケンスでピークメモリを約1.6倍削減します。
- エンドツーエンドのベンチマークは、モデル全体で顕著な改善を示します:LLaMA 3-8B スループット +42.8% および メモリ -54.8%;Qwen2 スループット +25.5% および メモリ -56.8%;Gemma スループット +11.9% および メモリ -51.8%;Mistral スループット +27% および メモリ -21%;Phi3 スループット +17% および メモリ -13%。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。