[論文レビュー] Lite Transformer with Long-Short Range Attention
Lite Transformerは二つの分岐Long-Short Range Attention (LSRA)を導入し、局所およびグローバル文脈を別々にモデル化します。制約のある計算資源の下でTransformerよりBLEUスコアを向上させ、モバイル対応のNLPを実現します。また、モデルサイズの大幅な削減を可能にし、heavy design costsなしにAutoML検索ベースのベースラインを上回ります。
Transformer has become ubiquitous in natural language processing (e.g., machine translation, question answering); however, it requires enormous amount of computations to achieve high performance, which makes it not suitable for mobile applications that are tightly constrained by the hardware resources and battery. In this paper, we present an efficient mobile NLP architecture, Lite Transformer to facilitate deploying mobile NLP applications on edge devices. The key primitive is the Long-Short Range Attention (LSRA), where one group of heads specializes in the local context modeling (by convolution) while another group specializes in the long-distance relationship modeling (by attention). Such specialization brings consistent improvement over the vanilla transformer on three well-established language tasks: machine translation, abstractive summarization, and language modeling. Under constrained resources (500M/100M MACs), Lite Transformer outperforms transformer on WMT'14 English-French by 1.2/1.7 BLEU, respectively. Lite Transformer reduces the computation of transformer base model by 2.5x with 0.3 BLEU score degradation. Combining with pruning and quantization, we further compressed the model size of Lite Transformer by 18.2x. For language modeling, Lite Transformer achieves 1.8 lower perplexity than the transformer at around 500M MACs. Notably, Lite Transformer outperforms the AutoML-based Evolved Transformer by 0.5 higher BLEU for the mobile NLP setting without the costly architecture search that requires more than 250 GPU years. Code has been made available at https://github.com/mit-han-lab/lite-transformer.
研究の動機と目的
- 厳しい計算制約下でエッジデバイス上の効率的なNLP推論を促進する。
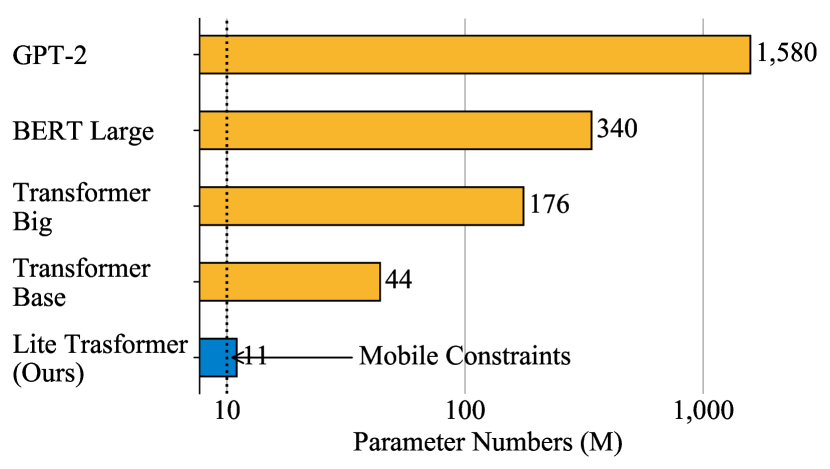
- 500M Mult-Adds以下で性能を維持または向上させる軽量なトランスフォーマーアーキテクチャを設計する。
- LSRAを導入してボトルネック注意機構を局所およびグローバル分岐に特化した構成へ置換する。
- LSRAが圧縮(プルーニング/量子化)を可能にし、顕著なサイズ削減をもたらすことを示す。
- モバイル設定下でAutoMLベースのベースライン(Evolved Transformer)と性能およびコストを比較する。
提案手法
- 二つの並列ブランチを持つLong-Short Range Attention (LSRA)を提案する:グローバルアテンションブランチとローカル畳み込みブランチ。
- 入力チャネルを分割して二つのブランチへ供給し、FFNで結合して、各ブランチの計算を実質的に半減させる。
- Transformerブロックの従来のボトルネックを、チャネル次元を平坦化して注意機構をモデル容量内で強調する形に置換する。
- ローカルブランチには軽量な畳み込みモジュールを用いて局所的な文脈を捉える(深さ方向的、パラメータ効率的)。
- MT (IWSLT, WMT) および追加タスク(要約、言語モデル)に対してモバイル制約予算(≤500M Mult-Adds)でLite Transformerを訓練・評価する。
- TransformerベースラインおよびEvolved Transformerと比較し、プルーニングと量子化による圧縮を分析する。
実験結果
リサーチクエスチョン
- RQ1LSRAはモバイル資源制約下で、MTおよび言語タスクの性能を損なうことなく、トランスフォーマーベースのモデルの効率を改善できますか?
- RQ2同様の計算予算下で、MT、要約、および言語モデリングにおけるLite Transformerの性能は、標準のTransformerおよびAutoMLベースのベースラインと比較してどうですか?
- RQ3Lite Transformerを標準的な圧縮技術(プルーニング、量子化)と組み合わせた場合、モデルサイズと性能にどのような影響がありますか?
主な発見
- Lite Transformerはモバイル設定下で主要なMTベンチマークにおいてTransformerよりBLEUを向上:WMT En-Deで500M Mult-Adds時に+1.2 BLEU、100M Mult-Adds時に+1.7 BLEU、WMT En-Frで100M Mult-Adds時に+1.7 BLEU、500M Mult-Adds時に+1.2 BLEU。
- IWSLT De-Enでは、Lite Transformerは約100M Mult-AddsでTransformerベースラインを約1.6 BLEU上回る。
- Lite TransformerはCNN-DailyMail要約で計算を最大約2.4x削減し、約500M Mult-Addsで言語モデリングの困難さ(perplexity)を約1.8x削減。
- プルーニングと8ビット量子化と組み合わせた場合、WMT En-FrでBLEUの劣化をほとんど生じさせずにモデルサイズを最大18.2x圧縮可能。
- AutoMLベースのEvolved Transformerに対して、モバイル設定下のWMT En-Deで0.5 BLEU高を達成。大規模な探索コスト(GPU年数とCO2排出)を伴わない。
- 全体として、LSRAのグローバルおよびローカル文脈への特化は、モバイルNLPの効率と拡張性を向上させ、ベースライン性能を維持または上回る。
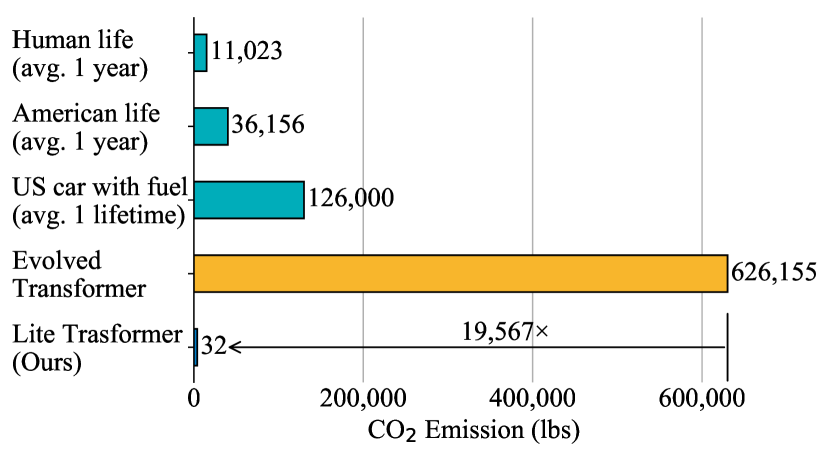
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。