[論文レビュー] Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama Guardは、Llama2-7bベースのモデルで、人間-AIの会話における入力と出力の安全性分類のファインチューニングを行い、安全性分類法(安全性タキソノミー)を備え、ゼロショット/ Few-shot適応性を持ち、モデルウェイトを公開する。
We introduce Llama Guard, an LLM-based input-output safeguard model geared towards Human-AI conversation use cases. Our model incorporates a safety risk taxonomy, a valuable tool for categorizing a specific set of safety risks found in LLM prompts (i.e., prompt classification). This taxonomy is also instrumental in classifying the responses generated by LLMs to these prompts, a process we refer to as response classification. For the purpose of both prompt and response classification, we have meticulously gathered a dataset of high quality. Llama Guard, a Llama2-7b model that is instruction-tuned on our collected dataset, albeit low in volume, demonstrates strong performance on existing benchmarks such as the OpenAI Moderation Evaluation dataset and ToxicChat, where its performance matches or exceeds that of currently available content moderation tools. Llama Guard functions as a language model, carrying out multi-class classification and generating binary decision scores. Furthermore, the instruction fine-tuning of Llama Guard allows for the customization of tasks and the adaptation of output formats. This feature enhances the model's capabilities, such as enabling the adjustment of taxonomy categories to align with specific use cases, and facilitating zero-shot or few-shot prompting with diverse taxonomies at the input. We are making Llama Guard model weights available and we encourage researchers to further develop and adapt them to meet the evolving needs of the community for AI safety.
研究の動機と目的
- 法的リスクやポリシー上のリスクを含む、人間-AIの相互作用に関する安全性リスクタキソノミーを定義する。
- 会話におけるプロンプトと応答の分類のための、Llama2-7b指示に調整されたLlama Guardを開発する。
- 再学習なしで新しいタキソノミーへのゼロショットおよび Few-shot 適応を可能にする。
- コミュニティ研究とカスタマイズを促進するために、モデルウェイトを公開する。
提案手法
- 暴力と憎悪、性的コンテンツ、銃器と違法武器、規制物質、自殺と自傷、犯罪計画などのカテゴリを含む安全性リスクタキソノミーを提案する。
- タキソノミーに従ってラベル付けされたデータセット上でLlama2-7bをファインチューニングし、指示に従うプロンプトを用いて入力(プロンプト)と出力(応答)の分類を実行する。
- データ拡張を用いてタキソノミーサブセットの認識を促進し、カテゴリシャッフリングでフォーマットの記憶化を防ぐよう訓練する。
- 同一ドメイン内およびクロスタキソノミー設定でゼロショット、Few-shot、ファインチューニング適応を用いて評価し、OpenAI Moderation API、Perspective API、Azure Content Safety、GPT-4と比較する。

実験結果
リサーチクエスチョン
- RQ1複数のリスクカテゴリーにわたって、人間-AIの会話におけるユーザーのプロンプトとAIの応答を安全性のために正確に分類するLLMベースのシステムは可能か。
- RQ2広範な再学習なしに、 prompting とファインチューニングを通じて新しい安全性タキソノミーへどの程度適応できるか。
- RQ3標準ベンチマーク(例:ToxicChat、OpenAI Moderation)およびカテゴリ全体で、従来のモデレーションツールに対してLlama Guardはどの程度の性能を示すか。
- RQ4クロスドメインの安全性分類性能におけるタキソノミー適応(ゼロショット vs Few-shot vs ファインチューニング)の影響は何か。
主な発見
- Llama Guardは、プロンプト分類と応答分類の両方において、自社の内部テストセットで高いAUPRCを達成する。
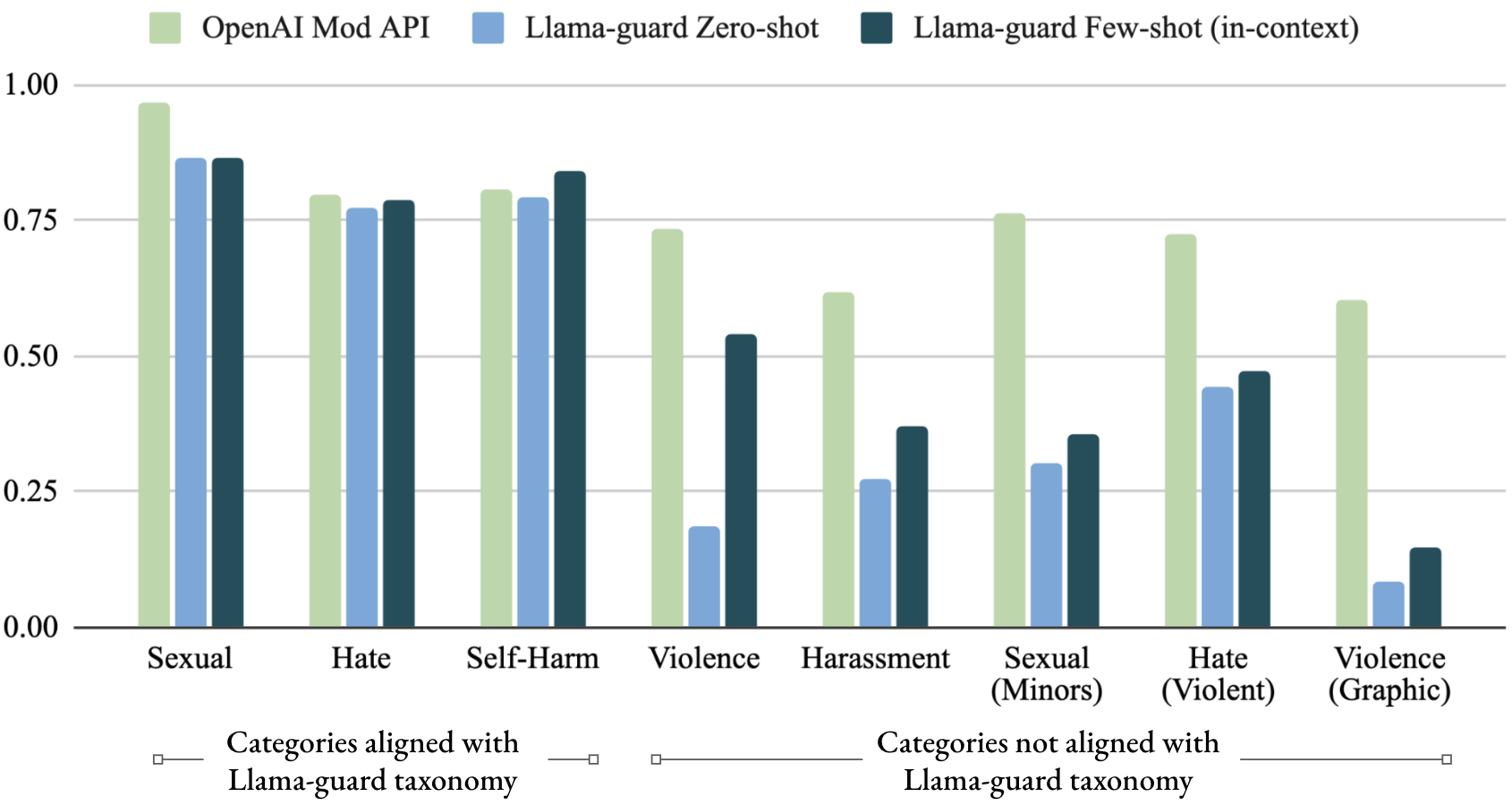
- ターゲットタキソノミーでのゼロショット展開では、Llama Guardは複数のベンチマークでベースラインと同等かそれを上回り、OpenAI ModデータセットではOpenAI Moderation APIにほぼ接近する。
- Llama Guardは ToxicChatデータセットで他のベースラインより優れている。
- prompting を通じた新しいタキソノミーへの適応(特に few-shot prompting)は整合性を改善し、時には専用モデレーションAPIを自データセット上で凌駕する。
- 別のタキソノミーでファインチューニングすることで迅速な適応を可能にし、ゼロからの再学習より少ないデータで競合的または優れた性能を達成することが多い。
- 推論時に出力形式とタキソノミーのカスタマイズをサポートし、新しいユースケースに対してゼロショットまたはFew-shot適応を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。