QUICK REVIEW
[論文レビュー] LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril|arXiv (Cornell University)|Feb 27, 2023
Natural Language Processing Techniques被引用数 3,849
ひとこと要約
LLaMAは公開データで訓練された7B〜65Bパラメータのオープン基盤言語モデルを提供し、より大きなクローズドモデルと競争力のある性能を達成し、控えめなハードウェアで推論を可能にします。
ABSTRACT
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
研究の動機と目的
- 公開データのみを用いてLLM研究へのアクセスを民主化する。
- 訓練/推論予算の範囲で小さなモデルが大きなモデルを上回ることを示す。
- 標準ベンチマークで13B–65Bモデルの競争力を示す。
- 研究者にとって訓練/推論の効率性と実用的なデプロイメントの考慮点を強調する。
提案手法
- プレ正規化、SwiGLU活性化、RoPEロータリ embeddingsを用いたトランスフォーマーアーキテクチャを利用する。
- ~1.0–1.4Tトークンで7B、13B、33B、65Bの複数モデルサイズを訓練し、コサイン学習率スケジュールとAdamWオプティマイザを用いる。
- 大規模GPUで訓練を高速化するため、メモリ効率の良い因果的アテンション実装とチェックポイントを使用する。
- 公的に入手可能なデータセット(CommonCrawl、C4、GitHub、Wikipedia、Books、ArXiv、Stack Exchange)を組み合わせ、重複排除と言語フィルタリングを慎重に実施して事前訓練を行う。
- SentencePieceによるBPEでトークン化し、Digit-splittingとUTF-8フォールバックを含めて広範なカバレッジを提供する。
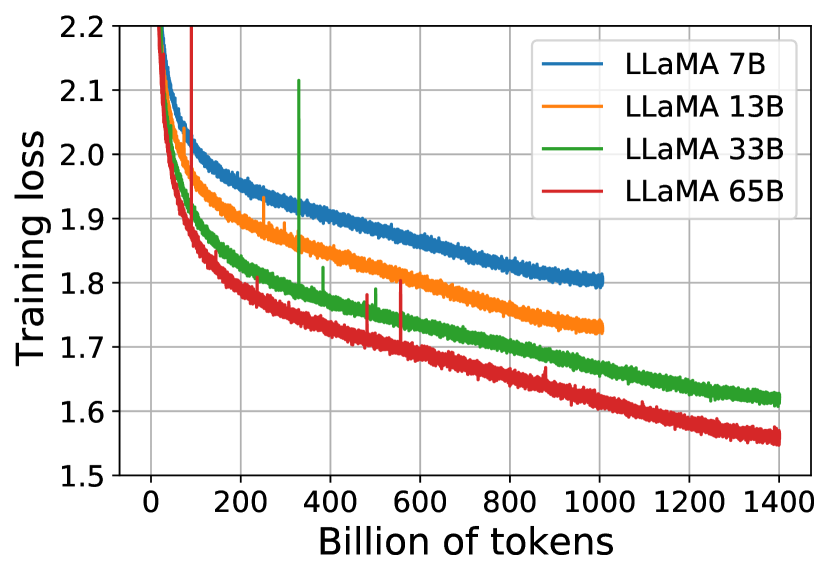
実験結果
リサーチクエスチョン
- RQ1オープンで公開ソースのデータだけで、7B–65Bの複数スケールにわたる高品質な基盤モデルの訓練は可能か。
- RQ2標準ベンチマークにおける推論予算の変化下で、小規模なオープンモデルは大規模な独自モデルに対してどのように性能を発揮するか。
- RQ3大規模言語モデルの強力な性能と実用的な推論効率を達成するためのアーキテクチャおよび訓練の最適化は何か。
- RQ4 Extensive dataを用いずに指示ファインチューニングはオープンモデルのタスク性能をどれほど向上させることができるか。
- RQ5公開データで訓練されたオープン基盤モデルの偏見、毒性、カーボンフットプリントの影響はどの程度か。
主な発見
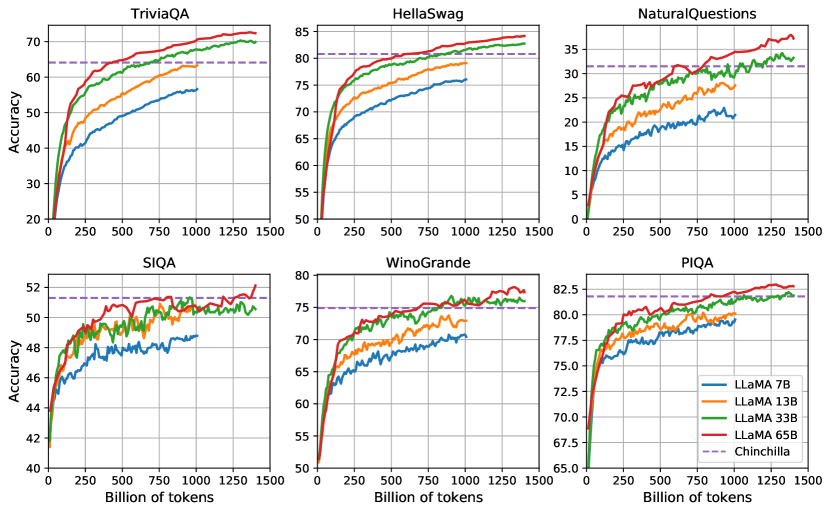
- LLaMA-13BはほとんどのベンチマークでGPT-3(175B)を上回り、サイズは10分の1程度であるにもかかわらず優れた性能を示している。
- LLaMA-65Bは複数の評価でトップモデル(Chinchilla-70B、PaLM-540B)と対等に競合している。
- LLaMA-65BはZero-shot/ Few-shot設定でNatural QuestionsやTriviaQAで強力な性能を示し、いくつかのタスクで65Bが最先端に近い結果を達成している。
- コード生成能力(HumanEval、MBPP)は、コードチューニングを行っていないベースラインよりLLaMAが優位であり、パラメータ数が多いほど大きな利得がある。
- 指示ファインチューニング(LLaMA-I)はMMLUの性能を向上させ、65Bで68.9%に達し、同程度のサイズの他の指示ファインチューニングモデルを上回っている。
- 本研究はバイアスと毒性パターン(RealToxicityPrompts、CrowS-Pairs、WinoGender)を記録し、GPT-3やOPTと比較し、サイズに関連する傾向と領域特有のバイアスを指摘している。
- 共通のデータセンター文脈でのトレーニングにおける炭素フットプリントの詳細な分析を行い、エネルギー使用量が大幅であることを示し、今後の排出削減のための公開性の意図を説明している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。