[論文レビュー] LLaVA-MoLE: Sparse Mixture of LoRA Experts for Mitigating Data Conflicts in Instruction Finetuning MLLMs
混在ドメインの指示データでの微調整時のデータ衝突を緩和するため、LoRA専門家の疎結合混成 MoLE を導入し、同程度のコストで通常の LoRA よりも性能向上を達成。
Instruction finetuning on a variety of image-text instruction data is the key to obtaining a versatile Multimodal Large Language Model (MLLM), and different configurations of the instruction data can lead to finetuned models with different capabilities. However, we have discovered that data conflicts are inevitable when mixing instruction data from distinct domains, which can result in performance drops for tasks of a specific domain. To address this issue, we propose to apply an efficient Mixture of Experts (MoE) design, which is a sparse Mixture of LoRA Experts (MoLE) for instruction finetuning MLLMs. Within the Transformer layers, we extend the popular Low-Rank Adaption (LoRA) method by creating a set of LoRA experts specifically for the MLP layer, and route each token to the top-1 expert based on a routing function, allowing adaptive choices for tokens from different domains. Since the LoRA experts are sparsely activated, the training and inference cost are kept roughly constant compared to the original LoRA method. By replacing the plain-LoRA of LLaVA-1.5 with our MoE design, our final model is named LLaVA-MoLE. Extensive experiments proved that LLaVA-MoLE effectively mitigates the data conflict issue when mixing multiple distinct instruction datasets with various configurations, and achieves consistent performance gains over the strong plain-LoRA baselines. Most importantly, on the mixed datasets, LLaVA-MoLE can even outperform the plain-LoRA baseline trained with twice the samples.
研究の動機と目的
- Identify data conflict issues when instruction finetuning MLLMs on mixtures of diverse domain datasets.
- Propose Sparse Mixture of LoRA Experts (MoLE) to route tokens to domain-specific LoRA experts.
- Demonstrate that MoLE mitigates conflicts and maintains similar computational cost to plain LoRA.
- Show that MoLE can outperform plain LoRA baselines even when the latter uses more data or training time.
提案手法
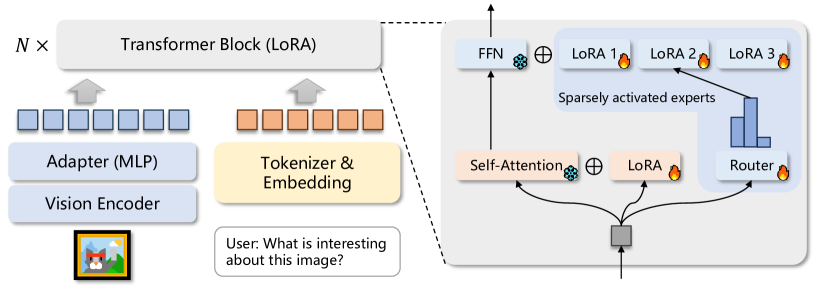
- LoRA を Transformer ブロックの各 FFN 層に複数の LoRA 専門家を追加して拡張する。
- 埋め込みに基づいて各トークンを 1 名の専門家へ割り当てるトップ-1 ルータを使用し、専門家の出力を FFN に加算する。
- 同一のルータを FFN 層全体で共有し、特定のトークンに対してすべての層が同じ専門家選択を使用する。
- 負荷分散損失を組み込み、専門家の均等な利用を奨励し idle 容量を防ぐ。
- スパース MoLE を、密な MoE および通常の LoRA と、複数のデータ構成とベンチマークで比較する。
実験結果
リサーチクエスチョン
- RQ1 sparse MoE の LoRA 専門家ルーティングは、MLLMs におけるドメイン分化指示データの混合時の性能低下を減少させるか?
- RQ2MoLE はさまざまなデータ構成において、性能と計算効率の点で通常の LoRA や密な MoE とどう比較されるか?
- RQ3データ衝突の下で、専門家の数と LoRA ランクが MoLE の有効性に与える影響は?
- RQ4 ドメイン間のデータサンプリング比を調整した場合、MoLE はタスク特定の性能をより改善できるか?
主な発見
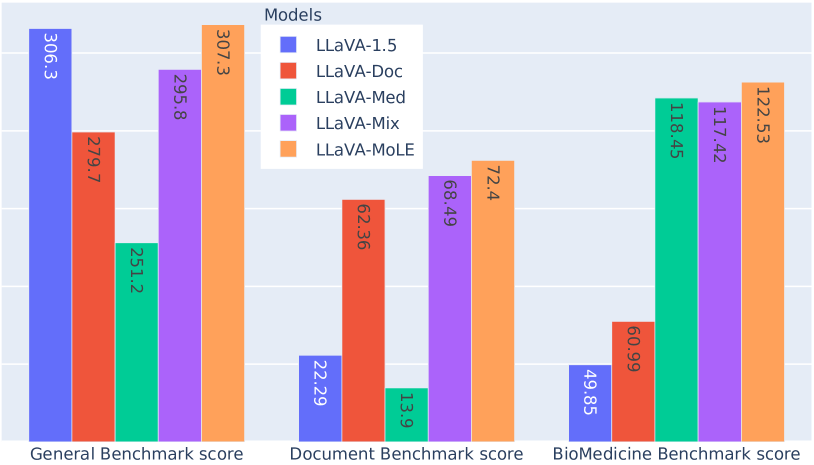
- MoLE は、一般・文書・バイオメディシン指示データを混在させた場合に、常に通常の LoRA よりも改善する。
- データ衝突の下で、MoLE はベースライン性能を維持または上回り、通常の LoRA と同程度の学習コストである。
- MoLE は混合データセットで、サンプル数を二倍で学習した Mix ベースラインを上回ることがある。
- 専門家の数を増やすほど性能は向上し、設定によっては 5–3 の専門家が強い結果を示す。
- Sparse MoLE は、密な MoE に匹敵する改善を、はるかに少ない GPU メモリで達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。