[論文レビュー] LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
本論文は LLM-Adapters を紹介する。PEFT アダプターをオープンソースの LLM に統合するフレームワークであり、数学と常識推論タスクにおけるアダプターの種類、配置、ハイパーパラメータの実証的研究を提供し、アダプターを備えた小型モデルが特定の設定で大規模モデルに匹敵または上回ることを示している。
The success of large language models (LLMs), like GPT-4 and ChatGPT, has led to the development of numerous cost-effective and accessible alternatives that are created by finetuning open-access LLMs with task-specific data (e.g., ChatDoctor) or instruction data (e.g., Alpaca). Among the various fine-tuning methods, adapter-based parameter-efficient fine-tuning (PEFT) is undoubtedly one of the most attractive topics, as it only requires fine-tuning a few external parameters instead of the entire LLMs while achieving comparable or even better performance. To enable further research on PEFT methods of LLMs, this paper presents LLM-Adapters, an easy-to-use framework that integrates various adapters into LLMs and can execute these adapter-based PEFT methods of LLMs for different tasks. The framework includes state-of-the-art open-access LLMs such as LLaMA, BLOOM, and GPT-J, as well as widely used adapters such as Series adapters, Parallel adapter, Prompt-based learning and Reparametrization-based methods. Moreover, we conduct extensive empirical studies on the impact of adapter types, placement locations, and hyper-parameters to the best design for each adapter-based methods. We evaluate the effectiveness of the adapters on fourteen datasets from two different reasoning tasks, Arithmetic Reasoning and Commonsense Reasoning. The results demonstrate that using adapter-based PEFT in smaller-scale LLMs (7B) with few extra trainable parameters yields comparable, and in some cases superior, performance to powerful LLMs (175B) in zero-shot inference on both reasoning tasks.
研究の動機と目的
- 多様なアダプターを統一フレームワークに統合して、LLM における PEFT を動機づけ・有効化する。
- タスクやモデル間で最適なアダプターの配置と設定を調査する。
- オープンソースの LLM を用いて、数学的推論と常識推論を含むデータセットに対するアダプター ベースの PEFT を評価する。
提案手法
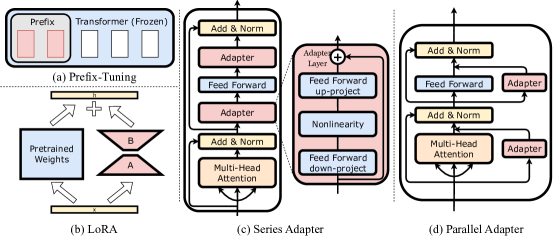
- Prefix-Tuning、Series Adapter、LoRA、Parallel Adapter を LLM に統合する LLM-Adapter フレームワークを開発する。
- Series、Parallel、LoRA アダプターの最適配置を特定するための配置実験を実施する。
- ハイパーパラメータを調整する(Prefix-Tuning の vt、Series/Parallel アダプターの bn、LoRA の r)最適な設定を見つける。
- 教師作成の推論根拠とタスクテンプレを用いて Math10K および Commonsense170K のファインチューニングデータセットを作成する。
- 選択した PEFT 手法で 7B/13B のオープン LLM(LLaMA、BLOOMz、GPT-J)をファインチューニングし、算数推論と常識推論を含む 14 データセットで評価する。
- GPT-3.5(175B)および ChatGPT を含むベースラインと PEFT の結果を比較する。
実験結果
リサーチクエスチョン
- RQ1異なる PEFT 手法の最適な配置と設定は何か?
- RQ2異なるアダプターは下流タスクでどのように性能を発揮するか?
- RQ3PEFT 手法の分布内・分布外シナリオの性能差は何か?
主な発見
- 最適な配置: Series Adapter はMLP層の後、Parallel Adapter はMLP層内、LoRA は Attention と ML P 層の両方の後。
- PEFT を備えた小型 LLM は、単純な数学タスクで大規模モデルを上回ることがある(例:LoRA を用いた LLaMA-13B が MultiArith、AddSub、SingleEq で GPT-3.5 を上回る)。
- LoRA を用いた LLaMA-13B は六つの数学データセットで平均 65.4% を達成し、これらのタスクで GPT-3.5 の性能に近づく(約 92.8% of GPT-3.5) 。
- 常識推論では、Series/Parallel/LoRA アダプタを用いた LLaMA-13B がベースラインを上回り、Parallel が平均 81.5% を達成し、ChatGPT を約 4.5 ポイント上回る。
- LLaMA-13B の3つのアダプターすべてが Commonsense170K で強力な結果を出し、3つのうち Parallel Adapter が最高の平均(81.5%)を達成。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。