[論文レビュー] LLM and Simulation as Bilevel Optimizers: A New Paradigm to Advance Physical Scientific Discovery
本論文は、Scientific Generative Agent (SGA) を提案する。これは、LLMが離散的な仮説(式)を生成し、微分可能なシミュレータが連続パラメータを最適化する、階層二重の枠組みであり、構成定律の発見と分子設計を可能にする。
Large Language Models have recently gained significant attention in scientific discovery for their extensive knowledge and advanced reasoning capabilities. However, they encounter challenges in effectively simulating observational feedback and grounding it with language to propel advancements in physical scientific discovery. Conversely, human scientists undertake scientific discovery by formulating hypotheses, conducting experiments, and revising theories through observational analysis. Inspired by this, we propose to enhance the knowledge-driven, abstract reasoning abilities of LLMs with the computational strength of simulations. We introduce Scientific Generative Agent (SGA), a bilevel optimization framework: LLMs act as knowledgeable and versatile thinkers, proposing scientific hypotheses and reason about discrete components, such as physics equations or molecule structures; meanwhile, simulations function as experimental platforms, providing observational feedback and optimizing via differentiability for continuous parts, such as physical parameters. We conduct extensive experiments to demonstrate our framework's efficacy in constitutive law discovery and molecular design, unveiling novel solutions that differ from conventional human expectations yet remain coherent upon analysis.
研究の動機と目的
- 領域特定の手法を超えた、統一された知識主導の物理科学的発見アプローチを動機づける。
- 離散的仮説を探索し連続パラメータを最適化するため、二レベル最適化でLLMsと微分可能なシミュレーションを組み合わせる。
- 構成定律の発見と分子設計への適用を通じて、斬新で一貫した解を見いだす。
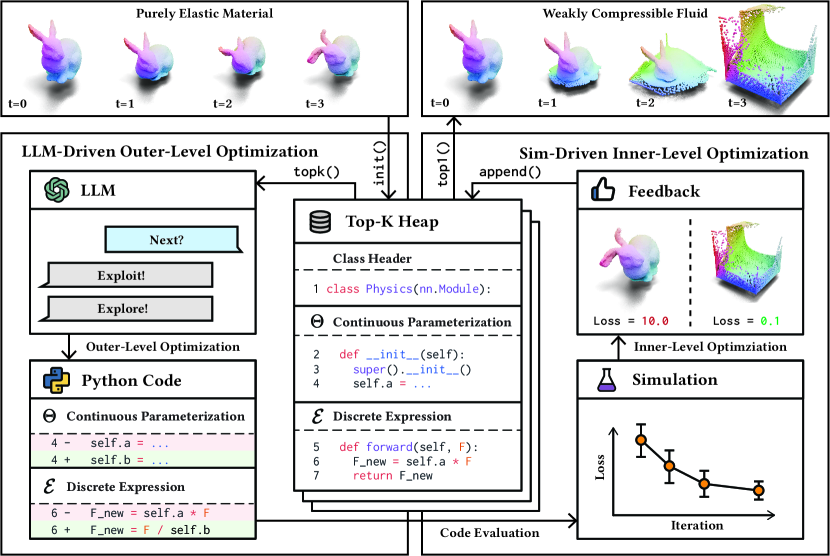
提案手法
- 外部レベルの探索: 過去のシミュレーション結果に基づいてLLMが離散的表現(E)と連続パラメータ空間(Theta)を提案; 内部レベルの最適化: 微分可能なシミュレーションがTheta内の連続パラメータ(theta)を最適化してEを評価。
- 二レベル最適化を定式化: G(E, Theta; Phi) ≤ 0 によるシミュレーションの妥当性を満たしつつ、 theta_hat = argmin_theta L(y(theta; Phi, E)) を満たすよう L(y(E, Theta, theta_hat; Phi)) を最小化。
- 活用と探索の戦略: 既知の良い解の活用と新しい仮説の探索をバランスさせるために、LLM生成温度を調整する。
- 2つの相互作用モード: 方程式探索(LLM が方程式と Theta を提案)とエンティティ探索(LLM が Theta を定数とする構造を提案)。
- 微分可能な内部最適化: θ に関する Phi からの勾配が内部最適化を導き、LLM へのフィードバック o を生成する。
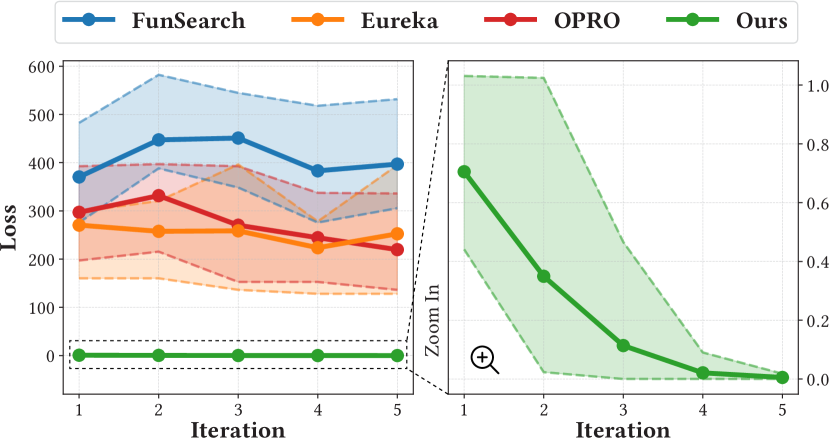
実験結果
リサーチクエスチョン
- RQ1運動データから構成定律を効果的に発見するために、LLMsと微分可能なシミュレーションを組み合わせた二レベルの枠組みは有効か。
- RQ2離散構造と連続座標を共同で最適化して、目標とする量子特性を持つ分子を設計できるか。
- RQ3活用-探索のバランスが、物理科学における発見の効率と解の品質にどのように影響するか。
- RQ4最小限のプロンプト変更で、構成定律の発見と分子設計という異なる領域においてLLMsは一般化できるか。
主な発見
| 方法 | #反復 | #履歴 | #活用/#探索 | 二レベル | 構成定律探索 (a-d) | 分子設計 (e-h) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CoT | 1 | 5 | N/A | ✗ | 298.5 | 1462.3 | 150.0 | 384.1 | 3.0 | 32.1 | 18.6 | 6.0 |
| FunSearch | 20 | 2 | 0 / 4 | ✗ | 210.3 | 872.2 | 82.8 | 139.5 | 1.1 | 7.1 | 8.3 | 1.1 |
| Eureka | 5 | 1 | 0 / 16 | ✗ | 128.0 | 531.0 | 101.7 | 150.1 | 4.3 | 9.8 | 3.3 | 9.7e-1 |
| OPRO | 5 | 5 | 0 / 16 | ✗ | 136.2 | 508.3 | 99.2 | 128.8 | 2.4 | 9.4 | 3.1 | 1.3 |
| Ours (no bilevel) | 5 | 5 | 4 / 12 | ✗ | 3.0e-3 | 3.9e-1 | 6.6e-2 | 1.4e-12 | 4.0e-4 | 1.5e-1 | 6.1e-1 | 2.8e-5 |
| Ours (no exploit) | 5 | 5 | 0 / 16 | ✓ | 1.3e-4 | 2.1e-1 | 6.0e-2 | 1.4e-12 | 1.3e-4 | 1.1e-1 | 5.4e-1 | 3.6e-5 |
| Ours | 5 | 5 | 4 / 12 | ✓ | 5.2e-5 | 2.1e-1 | 6.0e-2 | 1.4e-12 | 1.3e-4 | 1.1e-1 | 5.4e-1 | 3.6e-5 |
- 本手法は、構成定律の発見と分子設計のタスクの複数のベースラインを上回る。
- 二レベル最適化が鍵: 二レベルを除去すると性能が低下し、探索を伴って保持すると結果が改善する。
- 活用-探索のバランスは成功と品質を向上させ、難しいタスクでは1:3の活用:探索比がより良い結果をもたらす。
- 本手法は、専門家による検証で首尾一貫した新規で高性能な構成定律と分子設計を発見する。
- GPT-4は一般に他のバックボーンより優れているが、特定の分子設計タスクでは一部のオープンソースLLMが優れる。
- アブレーション分析により、LLMとシミュレーションの共同相互作用が反復的により良い提案を生むことが示された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。