[論文レビュー] LLM Discussion: Enhancing the Creativity of Large Language Models via Discussion Framework and Role-Play
この研究は LLM Discussion を提案する。複数の LLM のロールプレイを含む3段階のディスカッション・フレームワークで創造性を高め、LLM および人間の評価者の両方を用いて AUT、Instances、Similarities、および Scientific Creativity のベースラインを上回る。
Large language models (LLMs) have shown exceptional proficiency in natural language processing but often fall short of generating creative and original responses to open-ended questions. To enhance LLM creativity, our key insight is to emulate the human process of inducing collective creativity through engaging discussions with participants from diverse backgrounds and perspectives. To this end, we propose LLM Discussion, a three-phase discussion framework that facilitates vigorous and diverging idea exchanges and ensures convergence to creative answers. Moreover, we adopt a role-playing technique by assigning distinct roles to LLMs to combat the homogeneity of LLMs. We evaluate the efficacy of the proposed framework with the Alternative Uses Test, Similarities Test, Instances Test, and Scientific Creativity Test through both LLM evaluation and human study. The results show that our proposed framework outperforms single-LLM approaches and existing multi-LLM frameworks across various creativity metrics. The code is available at https://github.com/lawraa/LLM-Discussion.
研究の動機と目的
- 協調的なマルチエージェント・ディスカッションを通じて LLM の創造性を高めるアプローチの動機づけ。
- マルチターン・エンゲージメントと同質的思考における LLM の限界への対処。
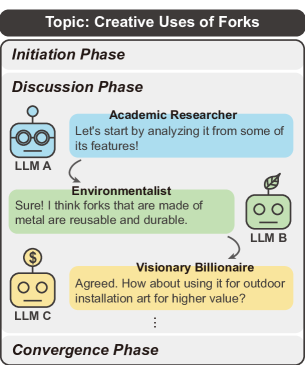
- 分岐思考と収束思考を促す initiation, discussion, and convergence の3段階フレームワークを設計。
- 多様な LLM の役割と Six Thinking Hats を取り入れて視点の多様性を高める。
- Wallach-Kogan Creativity Tests と Scientific Creativity Test を用い、LLM と人間の評価の両方で評価。
提案手法
- 分岐思考と収束思考を導く initiation, discussion, and convergence のプロンプトを備えた3段階のディスカッション・フレームワーク。
- 役割生成を通じて多様な LLM の役割と視点を作り出し、Six Thinking Hats を活用してさまざまな観点を得る。
- ロールプレイ統合:LLM に固定された役割を割り当て、各ラウンドで役割を思い出させる。
- 創造性ベンチマーク:Alternative Uses Task (AUT), Instances, Similarities, および Scientific Creativity Test。
- TTCTベースの指標による評価:Originality と Elaboration(主要)、加えて Fluency と Flexibility。
- ベースラインには Single Agent prompting、Brainstorm-then-Select (BTS)、および LLM Debate を含む。
実験結果
リサーチクエスチョン
- RQ1多人数の LLM によるロールプレイ付きディスカッションは、既存のベースラインと比較して創造性指標を改善するか?
- RQ2プロンプト設計、ディスカッション回数、参加する LLM の数などの要因は創造性の結果にどのように影響するか?
- RQ3LLM ベースの創造性評価と人間の判断との間に相関はあるか?
- RQ4提案されたフレームワークはラウンド間で分岐思考を維持し、高品質な創造的結論へ収束できるか?
主な発見
| ベンチマーク | 手法 | オリジナリティ | 展開 | 流暢さ | 柔軟性 |
|---|---|---|---|---|---|
| AUT | Single Agent | 3.47 | 0.38 | 8.99 | 1.10 |
| AUT | Brainstorm, then Select | 3.84 | 0.61 | 3.32 | 0.65 |
| AUT | LLM Debate | 3.73 | 0.47 | 3.78 | 0.47 |
| AUT | LLM Discussion | 4.44 | 0.30 | 4.22 | 0.27 |
| Instances | Single Agent | 2.46 | 0.33 | 14.32 | 4.52 |
| Instances | LLM Debate | 2.61 | 0.32 | 26.21 | 6.73 |
| Instances | LLM Discussion | 3.65 | 0.34 | 16.88 | 10.04 |
| Similarities | Single Agent | 2.66 | 0.39 | 7.00 | 1.76 |
| Similarities | LLM Debate | 2.81 | 0.21 | 2.61 | 2.34 |
| Similarities | LLM Discussion | 3.29 | 0.30 | 2.52 | 0.54 |
| Scientific | Single Agent | 3.18 | 0.38 | 6.37 | 2.35 |
| Scientific | LLM Debate | 3.52 | 0.38 | 6.91 | 3.35 |
| Scientific | LLM Discussion | 3.95 | 0.25 | 5.58 | 2.61 |
- LLM Discussion は AUT、Instances、Similarities、および Scientific Creativity テスト全体で Originality と Elaboration のベースラインを上回る。
- ロールプレイと3段階のディスカッション・フレームワークは協調的なダイナミクスを促進し、LLM 間の同質的思考を減少させる。
- 4 LLM による5つのディスカッション・ラウンドが全体的な最良のパフォーマンスをもたらす。
- 人間の評価は Originality と Elaboration で LLM の評価と一致し、いくつかの指標について人間の平均評価との強い相関を示す。
- Kendall の τ は Originality、Fluency、Flexibility に対して LLM の評価と平均人間評価の強い相関を示し、Elaboration には中程度の相関を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。