[論文レビュー] LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
SelfExtendは、推論時にファインチューニングなしで、離れたトークンにはグループ化されたアテンション、近くのトークンには標準の隣接アテンションを組み合わせ、floorベースの relpos マッピングを用いて、LLMのコンテキストウィンドウを拡張する。
It is well known that LLMs cannot generalize well to long contexts whose lengths are larger than the training sequence length. This poses challenges when employing LLMs for processing long input sequences during inference. In this work, we argue that LLMs themselves have inherent capabilities to handle long contexts without fine-tuning. To achieve this goal, we propose SelfExtend to extend the context window of LLMs by constructing bi-level attention information: the grouped attention and the neighbor attention. The grouped attention captures the dependencies among tokens that are far apart, while neighbor attention captures dependencies among adjacent tokens within a specified range. The two-level attentions are computed based on the original model's self-attention mechanism during inference. With minor code modification, our SelfExtend can effortlessly extend existing LLMs' context window without any fine-tuning. We conduct comprehensive experiments on multiple benchmarks and the results show that our SelfExtend can effectively extend existing LLMs' context window length. The code can be found at \url{https://github.com/datamllab/LongLM}.
研究の動機と目的
- LLMには事前学習の制限にもかかわらず、固有の長文脈能力があることを動機づける.
- 長文脈推論中の相対位置エンコーディングにおける分布外の位置問題に対処する.
- 推論時に文脈長を拡張するチューニング不要の機構を提案する.
- 言語モデリング、合成長文脈、実世界の長文脈タスクを横断するSelfExtendを評価する.
提案手法
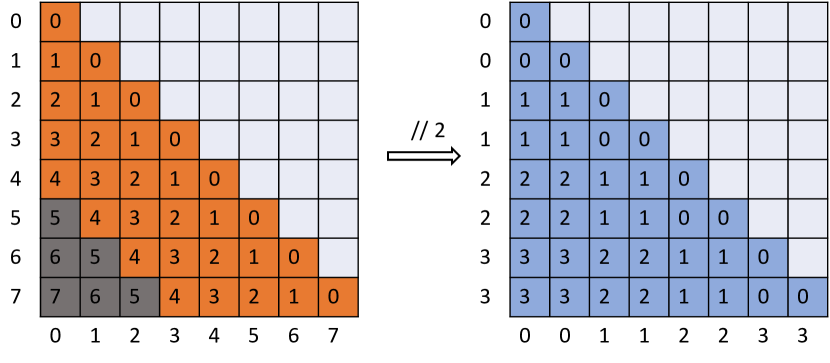
- 離れたトークンに floor-divided の位置マッピングを適用するグループ化アテンションを導入する。
- 定義されたウィンドウ内の隣接トークンには標準のアテンションを維持する。
- Softmaxの前に、グループ化アテンションと隣接アテンションを統合してSelfExtendアテンションを形成する。
- 微分計算を必要としない、ファインチューニング不要の推論時プラグイン変更を提供する。
- SelfExtendの下で実現可能な最大長を定量化する拡張されたコンテキスト長の式を導出する。
実験結果
リサーチクエスチョン
- RQ1LLMは事前学習を超えるより長い文脈を、本来の能力としてファインチューニングなしに扱えるのか?
- RQ2未見の大きな相対位置をどのように既知の位置へマッピングして一貫性を保つのか?
- RQ3SelfExtendは短い文脈性能を低下さることなく、複数モデルとタスクで長文脈の性能を向上させるのか?
主な発見
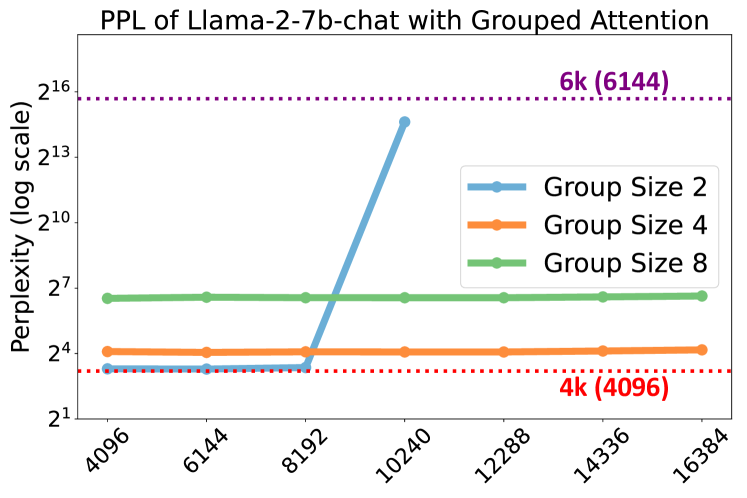
- SelfExtendは、グループ化アテンションを使用した場合、事前学習のコンテキストウィンドウを超えて低いパープレキシティを維持する。
- Passkeyリトリーブタスクは、深さと文脈を問わずSelfExtendで100%の精度を示し、真の長文脈アクセスを示唆している。
- 実世界の長文脁ベンチマークでは、自己拡張はファインチューニングベースの拡張と比較して競争力のある、あるいは優れた結果を達成する。
- SelfExtendは短文脈タスクの性能を維持しつつ長文脈能力を高め、トレーニングなしのプラグイン導入を可能にする。
- 多様なモデル(Llama-2、Mistral、SOLAR、Phi-2)を横断する実験で、本手法の適用範囲の広さを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。