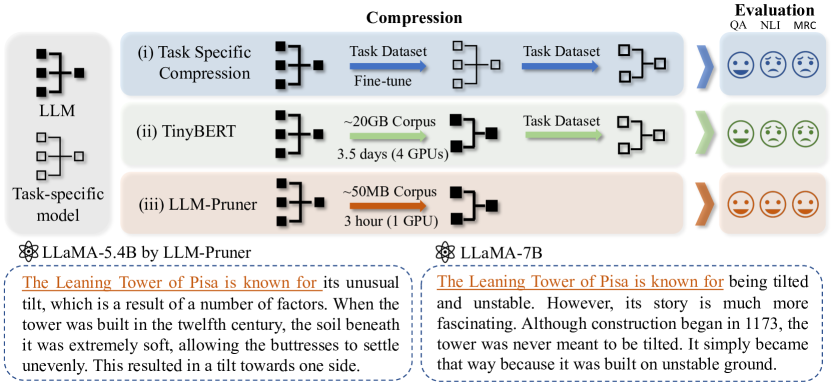
[論文レビュー] LLM-Pruner: On the Structural Pruning of Large Language Models
LLM-Pruner はタスク非依存で構造を考慮した大規模言語モデルの剪定を導入し、データ最小限で約3時間のポストトレーニングでLoRAを用いて大幅な圧縮を達成します。
Large language models (LLMs) have shown remarkable capabilities in language understanding and generation. However, such impressive capability typically comes with a substantial model size, which presents significant challenges in both the deployment, inference, and training stages. With LLM being a general-purpose task solver, we explore its compression in a task-agnostic manner, which aims to preserve the multi-task solving and language generation ability of the original LLM. One challenge to achieving this is the enormous size of the training corpus of LLM, which makes both data transfer and model post-training over-burdensome. Thus, we tackle the compression of LLMs within the bound of two constraints: being task-agnostic and minimizing the reliance on the original training dataset. Our method, named LLM-Pruner, adopts structural pruning that selectively removes non-critical coupled structures based on gradient information, maximally preserving the majority of the LLM's functionality. To this end, the performance of pruned models can be efficiently recovered through tuning techniques, LoRA, in merely 3 hours, requiring only 50K data. We validate the LLM-Pruner on three LLMs, including LLaMA, Vicuna, and ChatGLM, and demonstrate that the compressed models still exhibit satisfactory capabilities in zero-shot classification and generation. The code is available at: https://github.com/horseee/LLM-Pruner
研究の動機と目的
- マルチタスクの解決能力と生成能力を維持しつつ、LLMをタスク非依存の方法で圧縮することを目的とする。
- 圧縮中の元の訓練コーパスへの依存を最小化する。
- 剪定後の性能回復を迅速に行えるポストトレーニングを可能にする。
- 手動設計なしに、結合した構造グループを自動的に特定して剪定する。
提案手法
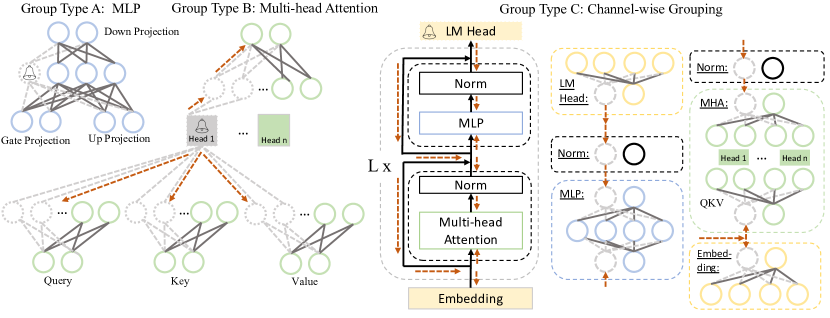
- LLM の結合構造を特定するための依存グラフを構築し、それらを一緒に剪定できるようにする。
- 小規模な公開データセットまたは合成データからの一次情報と(近似された)二次情報を用いてグループレベルの重要度を推定する。
- 定義された集約戦略(例:sum、product、max、last-only)に従って低重要度のグループを剪定する。
- 限定データ(約50k サンプル)と約3時間で単一GPU上のLoRAベースのポストトレーニングを用いて効率的に回復/剪定する。
実験結果
リサーチクエスチョン
- RQ1タスク非依存の構造的剪定は、LLaMA、Vicuna、ChatGLM の多様なタスクと生成能力を保持することができるか?
- RQ2依存性ベースの剪定はゼロショット分類および生成品質の点で、非依存剪定とどう比較されるか?
- RQ3剪定決定のための異なるグループ重要度集約戦略の有効性はどの程度か?
- RQ4LoRAポストトレーニングを用いて剪定されたLLMを回復するには、どれくらいのデータと時間が必要か?
主な発見
- パラメータの20%を剪定すると、LLaMA-7B で高速な LoRA 回復後に元のゼロショット性能のおよそ95%を保持できる。
- 5.4B パラメータの剪定済み LLM は、調整後にいくつかのデータセットで他の小型ベースモデルより優れることがある一方、50% の剪定は顕著な劣化を引き起こす。
- 依存性ベースの剪定は必須であり、依存性を削除すると微調整していてもゼロショット生成と分類に深刻な悪影響を及ぼす。
- 集約戦略の中で Sum は生成品質と分類性能の間で望ましいバランスを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。