[論文レビュー] Long-form factuality in large language models
この論文は、長形式の事実性ベンチマークのための LongFact、Google検索を用いた自動事実性評価ツール SAFE、長形式の事実性を F1@K 指標で評価する新しい指標、および 4 ファミリーにわたる 13 モデルを 38 トピックでベンチマークすることを紹介します。
Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
研究の動機と目的
- LongFact の提案、38 トピックにまたがる大規模な長形式の事実性プロンプトセット。
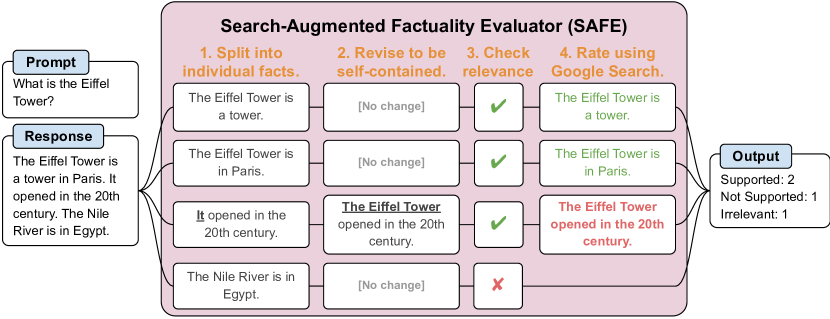
- SAFE の導入、回答を分解して事実を検証し、Google 検索を用いて自己完結的な事実を検証する LLM ベースの自動評価者。
- 長形式の事実性を測定するための F1@K の定義、長形式の事実性に対してリコールを考慮した集約指標。
- 4 ファミリー横断で 13 モデルをベンチマークし、事実性のスケーリング効果を評価。
提案手法
- LongFact プロンプトを GPT-4 を用いて作成し、38 トピックにわたる長形式の事実探索質問(LongFact-Concepts および LongFact-Objects)をカバー。
- SAFE を開発:自己完結的な事実に回答を分割し、関連性を評価し、Google 検索を用いた多段階推論で事実を正/不支持/関連なしとしてラベル付けする LLM エージェント。
- F1@K で事実性を集計する:長形式の事実性を正確度・再現率のハイブリッドで表し、再現率はユーザー指定の理想的な長さ K に結びつける。
- 固定のプロンプトセットを用いて SAFE で 13 モデル(Gemini、GPT、Claude、PaLM-2)をベンチマークし、K=64 および K=178 での F1@K を報告。
実験結果
リサーチクエスチョン
- RQ1長い形式のプロンプトセット(LongFact)は、さまざまなトピックにわたって長形式の事実性をどの程度検出できるのか。
- RQ2LLM ベースの自動評価者(SAFE)は、人間のアノテータと比較して長形式の回答の事実性を信頼性高く評価できるのか。
- RQ3モデルのサイズ/アーキテクチャは、Gemini、GPT、Claude、PaLM-2 の主要ファミリーにおける長形式の事実性にどのような影響を与えるのか。
- RQ4Recall 成分をハイパーパラメータ K を通じて組み込むことは、長形式の回答の事実性指標の有用性を向上させるのか。
主な発見
| モデル | S (サポート済み) | NS (サポートされていない) | I (関連なし) | 精度 | R64 | R178 | F1@64 | F1@178 |
|---|---|---|---|---|---|---|---|---|
| Gemini-Ultra | 83.4 | 13.1 | 7.6 | 86.2 | 98.3 | 46.9 | 91.7 | 60.3 |
| Gemini-Pro | 66.6 | 12.1 | 5.5 | 82.0 | 88.5 | 37.4 | 83.7 | 50.4 |
| GPT-4-Turbo | 93.6 | 8.3 | 6.1 | 91.7 | 99.0 | 52.6 | 95.0 | 66.4 |
| GPT-4 | 59.1 | 7.0 | 2.4 | 89.4 | 88.3 | 33.2 | 88.0 | 48.0 |
| GPT-3.5-Turbo | 46.9 | 4.5 | 1.2 | 90.8 | 72.4 | 26.4 | 79.6 | 40.5 |
| Claude-3-Opus | 63.8 | 8.1 | 2.8 | 88.5 | 91.4 | 35.9 | 89.3 | 50.6 |
| Claude-3-Sonnet | 65.4 | 8.4 | 2.6 | 88.5 | 91.4 | 36.7 | 89.4 | 51.4 |
| Claude-3-Haiku | 39.8 | 2.8 | 1.3 | 92.8 | 62.0 | 22.4 | 73.5 | 35.8 |
| Claude-2.1 | 38.3 | 6.5 | 1.9 | 84.8 | 59.8 | 21.5 | 67.9 | 33.7 |
| Claude-2.0 | 38.5 | 6.3 | 1.3 | 85.5 | 60.0 | 21.6 | 68.7 | 34.0 |
| Claude-Instant | 43.9 | 8.1 | 1.3 | 84.4 | 68.4 | 24.6 | 73.8 | 37.6 |
| PaLM-2-L-IT-RLHF | 72.9 | 8.7 | 4.3 | 89.1 | 94.0 | 41.0 | 91.0 | 55.3 |
| PaLM-2-L-IT | 13.2 | 1.8 | 0.1 | 88.8 | 20.6 | 7.4 | 31.1 | 13.2 |
- LongFact は 38 トピックにわたる広範な長形式の事実性ベンチマークを 2,280 プロンプトで提供する。
- SAFE は 個々の事実の 72% で人間の注釈と一致し、意見の相違があるケースでは人間の評価者よりも優れる(サンプルサブセットで正確性 76%)。
- SAFE は 1 回の回答あたりおよそ $0.19 のコストで、クラウドソーシングの人間注釈より約 20 倍安い。
- 13 モデル全体で、より大きなモデルは一般的に長形式の事実性が高く、固定の K 値でのランキングでは GPT-4-Turbo、Gemini-Ultra、PaLM-2-L-IT-RLHF が上位。
- F1@K 指標は、長形式の事実性を一貫して定量化するための、精度とリコール(人間が好む長さ K を介して)を捉える。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。