[論文レビュー] LoRA+: Efficient Low Rank Adaptation of Large Models
LoRA+ は、アダプタ行列の不均等な学習率を用いることで Low Rank Adaptation を改善し、1-2%の性能向上を達成し、追加計算コストなしでファインチューニングを最大で約2倍速くする。
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $\%$ improvements) and finetuning speed (up to $\sim$ 2X SpeedUp), at the same computational cost as LoRA.
研究の動機と目的
- 広範なモデルに対して A および B アダプタの学習率を等しく設定するとサブ最適なファインチューニングになるという問題を動機づけ、診断する。
- 無限幅スケーリング仮説に基づき、LoRA アダプタ A と B の固定比で principled な学習率スケーリングを提案する。
- 言語モデルとタスク全体でファインチューニング性能と速度の改善を実証する。
- 現実世界の設定で LoRA+ の比率と動作領域を選ぶための実用的なガイドラインを提供する。
提案手法
- 標準 LoRA と同様に W = W* + (alpha/r) B A として LoRA アダプタを導入し、無限幅極限での学習ダイナミクスを分析する。
- A と B に同じ学習率を用いるのは広いモデルに対してサブ最適であり、eta_A = Θ(n^{-1}) および eta_B = Θ(1) となる固定比を導出する。
- 安定で効率的な特徴学習を保証するためのネットワーク幅に基づく理論的スケーリング議論を展開する(Delta f_t = Θ(1))。
- toy linear および非線形モデルで理論を検証し、言語モデルのファインチューニングに関する広範な実験を行う。
- LoRA+ を標準 LoRA と比較し、同じ計算コストで性能が 1-2% 向上し、ファインチューニング速度が最大約2倍になることを報告する。
実験結果
リサーチクエスチョン
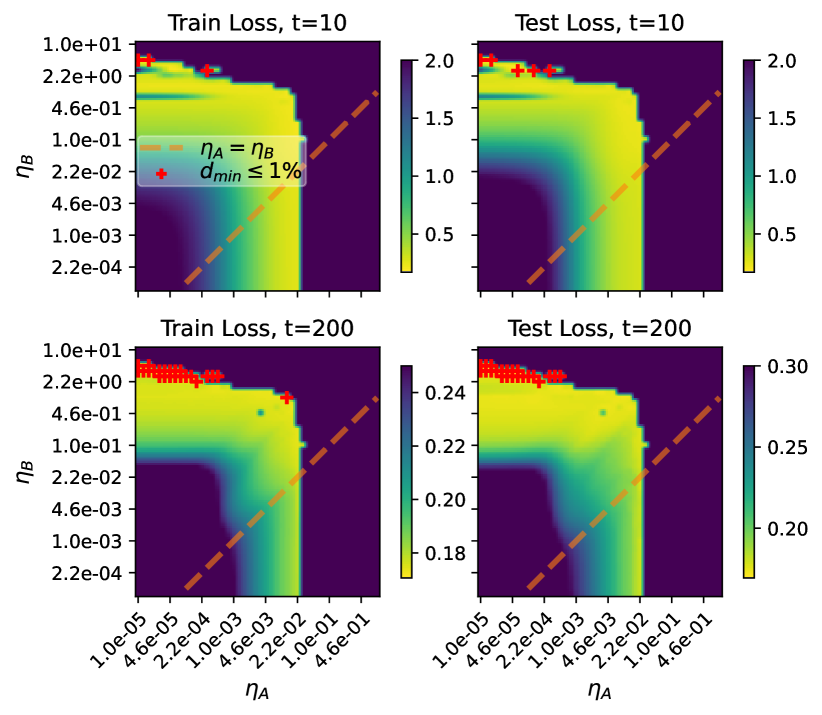
- RQ1LoRA アダプタ A と B の学習率が同じだと、モデル幅が大きくなると特徴学習が妨げられるのか。
- RQ2eta_A と eta_B の principled な比率は無限幅領域で効率的なファインチューニングを回復できるのか。
- RQ3提案されたスケーリング規則は言語モデルとタスク全体で実践的なファインチューニングの性能と速度を改善するのか。
- RQ4現実世界の設定で eta_B/eta_A の固定比を選ぶ際にどのような指針が得られるのか。
主な発見
- A と B に同じ学習率を用いる標準 LoRA は広いモデルで非効率的である。
- eta_A = Θ(n^{-1}) および eta_B = Θ(1) の principled な設定は安定して効率的な LoRA ファインチューニングを生む(Delta Z_B^t = Θ(1))。
- LoRA+ は 1-2% の性能向上と同じ計算コストで最大2x のファインチューニング速度向上を達成する。
- おもちゃ類とニューラルネットワークの実験から eta_B >> eta_A が一般的にほぼ最適な損失と安定した特徴学習をもたらすことを裏付ける。
- このアプローチは実世界の設定で効率を保ちつつハイパーパラメータチューニングを簡素化するための固定 eta_B/eta_A 比の選択指針を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。