[論文レビュー] Low-Resource Named Entity Recognition with Cross-Lingual, Character-Level Neural Conditional Random Fields
本論文は、関連する高資源言語から低資源言語へ知識を移行させる、文字レベルのクロスリンガルニューラルCRFをNERに提案し、転移設定でベースラインを特に上回るF1スコアを改善する。
Low-resource named entity recognition is still an open problem in NLP. Most state-of-the-art systems require tens of thousands of annotated sentences in order to obtain high performance. However, for most of the world's languages, it is unfeasible to obtain such annotation. In this paper, we present a transfer learning scheme, whereby we train character-level neural CRFs to predict named entities for both high-resource languages and low resource languages jointly. Learning character representations for multiple related languages allows transfer among the languages, improving F1 by up to 9.8 points over a loglinear CRF baseline.
研究の動機と目的
- NERにおける大規模データ要件の課題と、効果的な低資源手法の必要性を動機づける。
- 関連言語間の転移を可能にする共有文字レベル表現を備えたクロスリンガルニューラルCRFを提案する。
- 15言語で転移学習を評価し、低資源シナリオでの性能向上を検討する。
提案手法
- NERの9つのエンティティタグ(各タイプのb/iとo)を持つCRFベースの系列ラベリングモデルを定義する。
- 対数線形特徴量ベースのCRFと、文字レベルのLSTMと単語埋め込みを用いるニューラルCRFを比較する。
- 言語間で文字エンコーダを結び付け、言語特有の単語埋め込みを維持しつつ、クロスリンガル共有を導入する。
- 言語ID埋め込みと、共有遷移とtanhベースの相互作用によるニューラル潜在のクロス言語投影を組み込む。
- muが転移強度を制御する、ターゲット言語データとソース言語データの加重和を含む結合目的で訓練する。
- Pan et al. (2017) の15言語を対象とし、転移のための100-shot低資源と10k高資源の設定を用いて評価する。
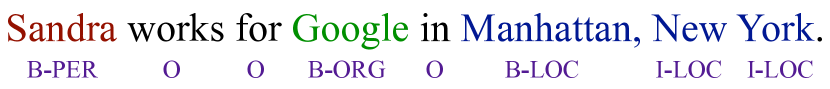
実験結果
リサーチクエスチョン
- RQ1文字レベルのニューラルCRFは、関連言語間で名前付きエンティティの表現を一般化できるか。
- RQ2クロスリンガル転移は低資源設定でNER性能を改善し、モノリンガルのベースラインと比較してどうか。
- RQ3単一ソース言語か複数ソース言語かが転移の有効性に与える影響は何か。
主な発見
- 高資源のモノリンガル設定では、ニューラルCRFが対数線形CRFより性能が高い。
- 低資源のモノリンガル設定では、対数線形CRFがニューラルCRFより性能が高い。
- クロスリンガル転移を用いると、ニューラルCRFは対数線形のベースラインよりF1を改善し、言語間の抽象化が優れていることを示唆する。
- ソース言語(例:スペイン語、カタルーニャ語、イタリア語)を含む転移は、低資源ターゲットにおけるニューラルCRFのF1を大幅に向上させる。
- 高資源ターゲット設定では、転移はほとんど/全く改善をもたらさない。
- 15言語を横断して、クロスリンガル転移を伴うニューラルCRFは高資源パフォーマンスへとギャップを縮小するが、改善余地が残る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。