[論文レビュー] Machine Learning with a Reject Option: A survey
本調査は拒否機能を伴う機械学習の包括的な概要を提供し、曖昧性と新規性の拒否の形式化、アーキテクチャ、評価手法、学習アプローチ、および関連分野との関連性を整理する。
Machine learning models always make a prediction, even when it is likely to be inaccurate. This behavior should be avoided in many decision support applications, where mistakes can have severe consequences. Albeit already studied in 1970, machine learning with rejection recently gained interest. This machine learning subfield enables machine learning models to abstain from making a prediction when likely to make a mistake. This survey aims to provide an overview on machine learning with rejection. We introduce the conditions leading to two types of rejection, ambiguity and novelty rejection, which we carefully formalize. Moreover, we review and categorize strategies to evaluate a model's predictive and rejective quality. Additionally, we define the existing architectures for models with rejection and describe the standard techniques for learning such models. Finally, we provide examples of relevant application domains and show how machine learning with rejection relates to other machine learning research areas.
研究の動機と目的
- 予測モデルにおける見合わせの条件を形式化する(曖昧性と新規性)。
- 拒否を実現するアーキテクチャと学習戦略を検討・分類する。
- 拒否機能を持つモデルの評価フレームワークとコストを概説する。
- 複数の拒否器の組み合わせ方法と、拒否と広範なMLトピックとの関連を説明する。
- 信頼性の高い機械学習および関連分野における応用と今後の方向性を強調する。
提案手法
- 拒否付き学習問題を定義し、出力空間を拒否記号を含むよう拡張する。
- 拒否を曖昧性拒否と新規性拒否に分類し、バイアス・分散およびデータ分布の解釈を用いる。
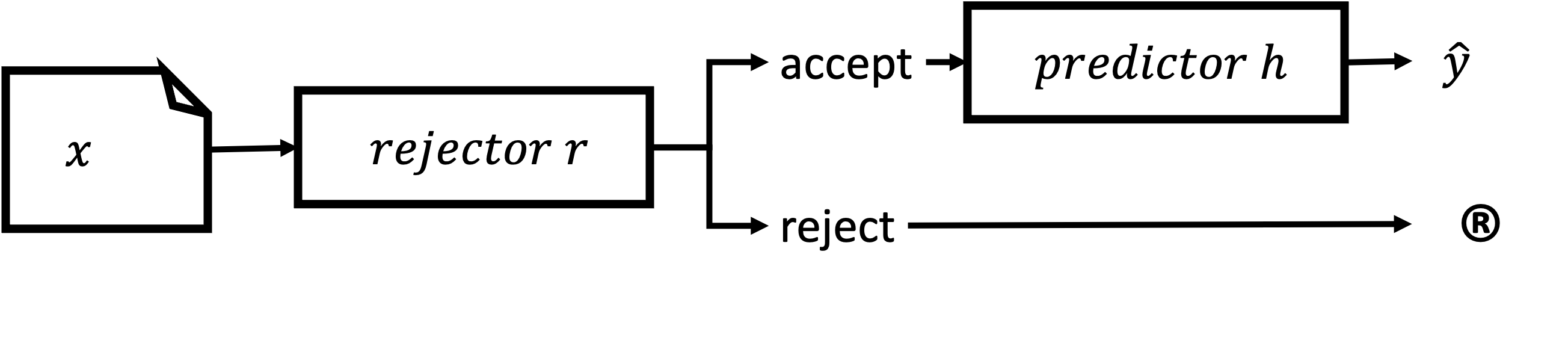
- アーキテクチャ(Separated、Dependent、Integrated)をレビューし、予測における拒否の実装方法を整理する。
- 評価手法の要約:固定拒否率、トレードオフ曲線(ARC/AURC)、コストベースの指標。
- 拒否器の学習戦略を説明する(密度推定、ワンクラス分類器、新規性スコア、信頼度関数)。
- 複数の拒否器の統合と組み合わせ、および不確実性定量化、アクティブラーニング、関連分野との結びつきを論じる。
実験結果
リサーチクエスチョン
- RQ1モデルが予測を見合わせるべき時をどう形式化するか(曖昧性 vs. 新規性)?
- RQ2予測品質と拒否品質をどう評価するか、トレードオフとコストを含めて。
- RQ3どのようなアーキテクチャが拒否を可能にするか、拒否を持つモデルをどう学習できるか。
- RQ4Separated、Dependent、Integrated rejectors の長所と短所は?
- RQ5複数の拒否器をどう組み合わせることができるか、他のML研究領域との関係は何か。
主な発見
- 曖昧性と新規性という拒否タイプの体系的分類と、Separated、Dependent、Integrated の三つのアーキテクチャ系を提供する。
- 固定拒否率、ARC/AURCのトレードオフ、コストベースの指標を含む包括的な評価フレームワークの概要。
- 拒否器の学習パラダイム(密度/確率推定、ワンクラス法、新規性スコア、信頼度関数)の詳細。
- デプロイ時に信頼性・安全性・公平性を向上させつつ、予測品質とカバレッジのバランスをとる方法を示す。
- 拒否を不確実性定量化、異常検知、アクティブラーニング、メタラーニング、関連分野と結びつける。
- アプリケーションにおける実用的な考慮事項を論じ、今後の研究方向を概説する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。