[論文レビュー] Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Magentic-Oneは、オーケストレーターが指揮する汎用的なマルチエージェント体系を提示し、専門エージェントへタスクを委任し、エラーから回復することでGAIA、AssistantBench、WebArenaのベンチマークで競争力のある性能を達成する。さらに厳密なエージェント評価のためのAutoGenBenchを導入する。
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
研究の動機と目的
- diverse な領域で複雑なタスクを解決できる汎用的なエージェント系システムの開発を促進する。
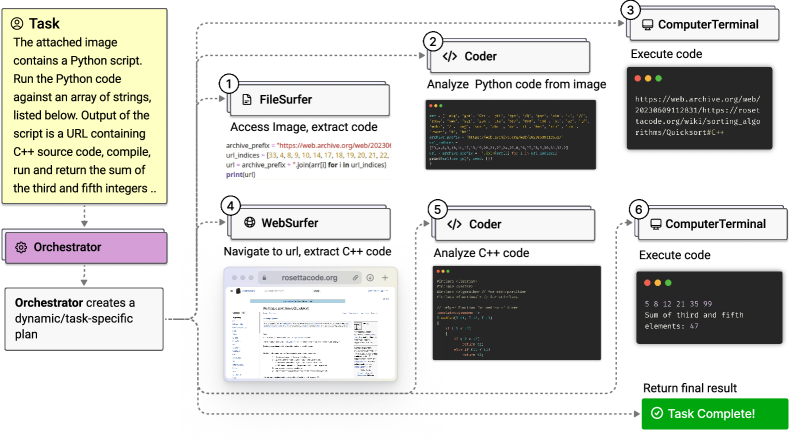
- オーケストレーターが専門エージェント(WebSurfer、FileSurfer、Coder、ComputerTerminal)を調整するモジュラーなマルチエージェントアーキテクチャを提案する。
- 状態を持つ環境でのエージェントシステムを厳密かつ再現性のある評価のためのAutoGenBenchを導入する。
- 変更せずともモジュール化されたマルチエージェント構成が複数のベンチマークで最先端と同等の性能を発揮できることを示す。
- エージェントの追加/削除の拡張性と将来のシナリオ適応の可能性を強調する。
提案手法
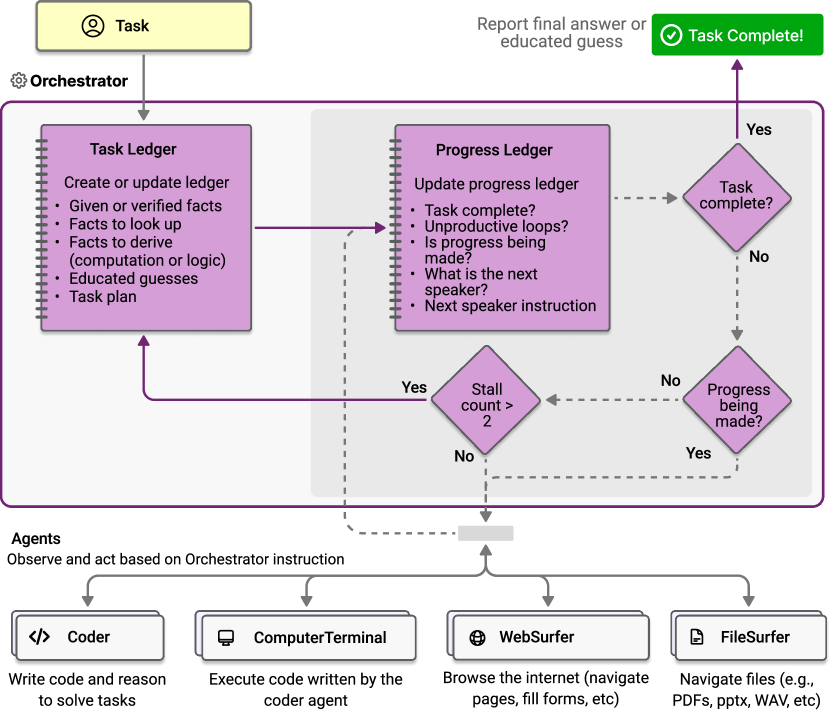
- 外部ループがタスク台帳(計画、事実、推定)を維持し、内部ループが進捗台帳(タスク割当と進捗追跡)を維持する、Magentic-Oneの二重ループオーケストレーションを提案する。
- オーケストレーターを用いて逐次計画を生成し、専門エージェントへサブタスクを割り当て、停滞やエラーから回復するためのリセット/再計画を行う。
- 共有制御フローの下で、ブラウザ/ウェブタスク用のWebSurfer、ファイル操作用のFileSurfer、コード/成果物作成用のCoder、コード実行用のComputerTerminalといった専門エージェントのチームを展開する。
- スタックに陥った場合の回復機構として、内部ループのカウンターと反省ステップを導入し、限定的なエラー回復を可能にする。
- AutoGenBenchを独立した統制評価フレームワークとして導入し、エージェントシステムの分離された反復可能なベンチマーキングを保証する。
- 三つのベンチマーク(GAIA、AssistantBench、WebArena)で、オープンソース実装とアブレーション分析を用いて評価する。
実験結果
リサーチクエスチョン
- RQ1Magnetic-Oneは、さまざまなエージェント系ベンチマーク(GAIA、AssistantBench、WebArena)で競争力のあるタスク完遂率や精度を達成できるか。
- RQ2モジュラーなマルチエージェント設計(オーケストレーターと専門エージェント)は、プロンプト訓練やコアアーキテクチャの変更なしに、性能と汎化に寄与するのか。
- RQ3評価フレームワーク(AutoGenBench)が、再現性・安全性・タスクのばらつきにどのような影響を与えるか。
- RQ4各エージェントの個別寄与と、主たる失敗モードはどこにあるか。
- RQ5基盤となるLLMを変化させた場合(例:GPT-4o vs o1-preview)にシステムは性能を維持できるか。
主な発見
| 方法 | GAIA | AssistantBench(EM) | AssistantBench(精度) | WebArena |
|---|---|---|---|---|
| ;; omne v0.1 (GPT-4o, o1) | 40.53 ± 5.6 | – | – | – |
| ;; Trase Agent v0.2 (GPT-4o, o1, Gemini) | 39.53 ± 5.5 | – | – | – |
| ;; Multi Agent (NA) | 38.87 ± 5.5 | – | – | – |
| ;; das agent v0.4 (GPT-4o) | 38.21 ± 5.5 | – | – | – |
| ;; Sibyl (GPT-4o) [56] | 34.55 ± 5.4 | – | – | – |
| ;; HF Agents (GPT-4o) | 33.33 ± 5.3 | – | – | – |
| ;; FRIDAY (GPT-4T) [61] | 24.25 ± 4.8 | – | – | – |
| ;; GPT-4 + plugins [29] | 14.60 ± 4.0 | – | – | – |
| ;; SPA -> CB (Claude) [71] | – | 13.8 ± 5.0 | 26.4 ± 6.4 | – |
| ;; SPA -> CB (GPT-4T) [71] | – | 9.9 ± 4.3 | 25.2 ± 6.3 | – |
| ;; Infogent (GPT-4o) | – | 5.5 ± 3.3 | 14.5 ± 5.1 | – |
| ;; Jace.AI (NA) | – | – | – | 57.1 ± 3.4 |
| ;; WebPilot (GPT-4o) [75] | – | – | – | 37.2 ± 3.3 |
| ;; AWM (GPT-4) [57] | – | – | – | 35.5 ± 3.3 |
| ;; SteP (GPT-4) [49] | – | – | – | 33.5 ± 3.2 |
| ;; BrowserGym (GPT-4o) [10] | – | – | – | 23.5 ± 2.9 |
| ;; GPT-4 | 6.67 ± 2.8 [29] | 6.1 ± 3.5 [71] | 16.5 ± 5.4 [71] | 14.9 ± 2.4 [79] |
| ;; Human | 92.00 ± 3.1 | – | – | 78.2 ± 2.8 |
| ;; Magentic-One (GPT-4o) | 32.33 ± 5.3 | 11.0 ± 4.6 | 25.3 ± 6.3 | 32.8 ± 3.2 |
| ;; Magentic-One (GPT-4o, o1) | 38.00 ± 5.5 | 13.3 ± 4.9 | 27.7 ± 6.5 | * |
- Magentic-OneはGAIAで38%、WebArenaで32.8%、AssistantBenchで27.7%のタスク完遂率を達成し、GPT-4oおよびo1構成でSOTAベースラインに対して統計的に競合する性能を示す。
- GPT-4o単独使用では、提案設定でGAIA 32.33%、AssistantBench EM 11.0%、AssistantBench 精度 25.3%、WebArena 32.8%を達成; GPT-4oとo1を組み合わせると、GAIAは38.00%、AssistantBench EM 13.3%、精度 27.7%に改善。
- アブレーション分析は、各エージェントの追加価値と明確なエラーモードを示し、改善の機会を示唆する。
- AutoGenBenchは、初期条件を固定し、実行間の分離を保証し、状態を持つタスクの安全な評価を通じて、制御された再現可能なベンチマーキングを可能にする。
- 結果は、ウェブとファイルベースのタスクをコア変更なしに運用できる汎用的なエージェント系システムの実現性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。