[論文レビュー] MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
MagicAnimateは、時系列モデリングと新規外観エンコーダを備えた拡散ベースのフレームワークを導入し、DensePoseのモーションに導かれた時系列的一貫性と高忠実度の人間画像アニメーションを生成します。TikTokおよびTEDトークスデータセットでベースラインを上回ります。
This paper studies the human image animation task, which aims to generate a video of a certain reference identity following a particular motion sequence. Existing animation works typically employ the frame-warping technique to animate the reference image towards the target motion. Despite achieving reasonable results, these approaches face challenges in maintaining temporal consistency throughout the animation due to the lack of temporal modeling and poor preservation of reference identity. In this work, we introduce MagicAnimate, a diffusion-based framework that aims at enhancing temporal consistency, preserving reference image faithfully, and improving animation fidelity. To achieve this, we first develop a video diffusion model to encode temporal information. Second, to maintain the appearance coherence across frames, we introduce a novel appearance encoder to retain the intricate details of the reference image. Leveraging these two innovations, we further employ a simple video fusion technique to encourage smooth transitions for long video animation. Empirical results demonstrate the superiority of our method over baseline approaches on two benchmarks. Notably, our approach outperforms the strongest baseline by over 38% in terms of video fidelity on the challenging TikTok dancing dataset. Code and model will be made available.
研究の動機と目的
- 人間画像アニメーションにおける時系列の不整合性と参照外観の忠実度を解決する。
- フレーム間で時系列情報をエンコードする動画拡散モデルを開発する。
- アイデンティティ、衣服、背景の詳細を保持する密度の高い外観エンコーダを導入する。
- 重複するセグメント間での単純な動画融合戦略を通じて長時間の動画アニメーションを可能にする。
- 画像-動画のジョイント訓練とセグメンテーション認識条件付けにより各フレームの忠実度を向上させる。
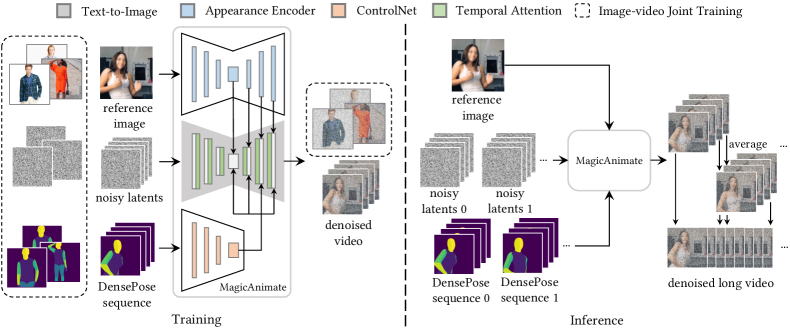
提案手法
- 拡散モデルを2D UNetを時系列注意ブロックで膨張させ、3D時系列UNetを形成して動画領域へ展開する。
- デノイジング中の空間自己注意に密な参照画像特徴を注入する外観エンコーダを導入し、アイデンティティと背景の保持を改善する。
- DensePoseシーケンスを姿勢ControlNetで条件付けし、モーション転送を駆動する。
- 長い動画をセグメントごとにスライディングウィンドウのオーバーラップで処理し、オーバーラップフレームを平均化して滑らかな遷移を確保する。
- 大規模な画像データセットから豊かな外観手掛かりを活用し、各フレームの忠実度を保つために画像-動画ジョイント戦略で訓練する。
- 推論時に単純な動画融合技法を用いてオーバーラップセグメントの出力をブレンドし、長時間のアニメーションを滑らかにする。

実験結果
リサーチクエスチョン
- RQ1拡散ベースのフレーム間法よりも人間画像アニメーションの時系列整合性を高められるか。
- RQ2専用の外観エンコーダはCLIPベースの外観条件付けよりアイデンティティ保持と背景忠実度を改善するか。
- RQ3時系列注意と画像-動画ジョイント訓練が各フレームの品質と動画忠実度にどのような影響を与えるか。
- RQ4推論時の簡易なオーバーラップベースの動画融合は長時間動画の滑らかさにどれほど効果的か。
- RQ5MagicAnimateは未知ドメインおよびマルチ人物シナリオへどの程度一般化するか。
主な発見
| Method | Image | Video | L1 | PSNR | SSIM | LPIPS | FID | FID-VID | FVD |
|---|---|---|---|---|---|---|---|---|---|
| TPS* | 3.23E-04 | 29.18 | 0.673 | 0.299 | 53.78 | 72.55 | 306.17 | ||
| MRAA* | 3.21E-04 | 29.39 | 0.672 | 0.296 | 54.47 | 66.36 | 284.82 | ||
| TPS | 6.17E-04 | 28.17 | 0.560 | 0.449 | 140.37 | 142.52 | 800.77 | ||
| MRAA | 4.61E-04 | 28.39 | 0.646 | 0.337 | 85.49 | 71.97 | 468.66 | ||
| IPA+CtrlN | 7.38E-04 | 28.03 | 0.459 | 0.481 | 69.83 | 113.31 | 802.44 | ||
| IPA+CtrlN-V | 6.99E-04 | 28.00 | 0.479 | 0.461 | 66.81 | 86.33 | 666.27 | ||
| DisCo | 3.78E-04 | 29.03 | 0.668 | 0.292 | 30.75 | 59.90 | 292.80 | ||
| MagicAnimate (Ours) | 3.13E-04 | 29.16 | 0.714 | 0.239 | 32.09 | 21.75 | 179.07 |
- MagicAnimateはTikTokおよびTEDトークスデータセットにおいて、画像および動画の忠実度指標で最先端の性能を達成した。
- TikTokでは、Video Qualityの指標(FVD)で最強のベースラインを38%以上上回り、FID-VIDでも38%を超える改善を達成した。
- TEDトークスではFID-VIDおよびFVDで最高値を達成し、ベースラインより顕著な改善を示した。
- アブレーション実験により、時系列モデリングと外観エンコーダがSSIMとLPIPSを大幅に改善し、画像-動画ジョイント訓練が全体の忠実度を向上させることを示した。
- 単純な動画融合戦略は長時間の動画で遷移を滑らかにし、時系列的一貫性を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。