[論文レビュー] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
Magpie は前問プリ templates のみで整列済み LLM を促すことにより、大規模で高品質な指示データを自動生成し、最大 4 million の指示を作成し、fine-tuning open-weight モデルのために 300K の高品質インスタンスを選択します。
High-quality instruction data is critical for aligning large language models (LLMs). Although some models, such as Llama-3-Instruct, have open weights, their alignment data remain private, which hinders the democratization of AI. High human labor costs and a limited, predefined scope for prompting prevent existing open-source data creation methods from scaling effectively, potentially limiting the diversity and quality of public alignment datasets. Is it possible to synthesize high-quality instruction data at scale by extracting it directly from an aligned LLM? We present a self-synthesis method for generating large-scale alignment data named Magpie. Our key observation is that aligned LLMs like Llama-3-Instruct can generate a user query when we input only the left-side templates up to the position reserved for user messages, thanks to their auto-regressive nature. We use this method to prompt Llama-3-Instruct and generate 4 million instructions along with their corresponding responses. We perform a comprehensive analysis of the extracted data and select 300K high-quality instances. To compare Magpie data with other public instruction datasets, we fine-tune Llama-3-8B-Base with each dataset and evaluate the performance of the fine-tuned models. Our results indicate that in some tasks, models fine-tuned with Magpie perform comparably to the official Llama-3-8B-Instruct, despite the latter being enhanced with 10 million data points through supervised fine-tuning (SFT) and subsequent feedback learning. We also show that using Magpie solely for SFT can surpass the performance of previous public datasets utilized for both SFT and preference optimization, such as direct preference optimization with UltraFeedback. This advantage is evident on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
研究の動機と目的
- 人間が執筆したデータやプロダクションモデルへの API アクセス依存を減らすことで LLM アラインメントデータの民主化を促進する。
- 前問テンプレートを用いて整列済み LLM から直接多様な指示を抽出する自己合成法を提案する。
- Seed プロンプトや seed なしで大規模な指示データセット(Magpie-Air および Magpie-Pro)とマルチターン variante を生成する。
- Magpie データでオープンウェイトモデルをファインチューンすることでベースラインを上回り、公式に整列済みモデルに近づくことを示す。
提案手法
- 事前問テンプレートのみで整列済み LLM をプロンプトして自律的な指示生成を促す(シード質問なし)。
- 整列済み LLM の自己回帰特性を利用して、end-of-sequence トークンが生成されるまで多様な指示を生成する。
- 生成された指示で同じ LLM を照会して指示-応答ペアを形成する。
- 人間の介入なしに Magpie データセット(Magpie-Air および Magpie-Pro)とマルチターン variant(Magpie-Air-MT、Magpie-Pro-MT)を作成する。
- ファインチューニング用の高品質インスタンスを選定するためのフィルタリングと分析を適用する(例:300K の高品質サブセット)。
- ファインチューニングの評価は、オープンウェイトモデル(Llama-3-8B-base、Qwen1.5-4B/7B)を用いて整列ベンチマークで評価する。
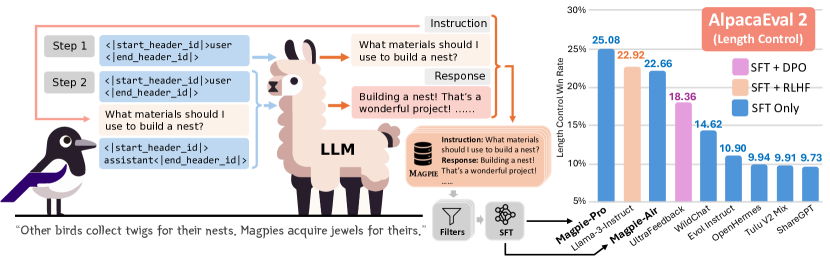
実験結果
リサーチクエスチョン
- RQ1Seed や seed エンジニアリングなしで、整列済み LLM から直接大規模に高品質の指示データを合成できるか。
- RQ2Magpie 生成データセットは、公開ベースラインや民間データで訓練されたモデルと同等またはそれを超える性能をオープンウェイトモデルに達成させるか。
- RQ3Magpie データの品質、カバレージ、および安全性の特徴は何で、それらが下流のファインチューニングにどう影響するか。
- RQ4Magpie は従来のデータ作成パイプラインと比べて費用対効果が高く、スケーラブルか。
主な発見
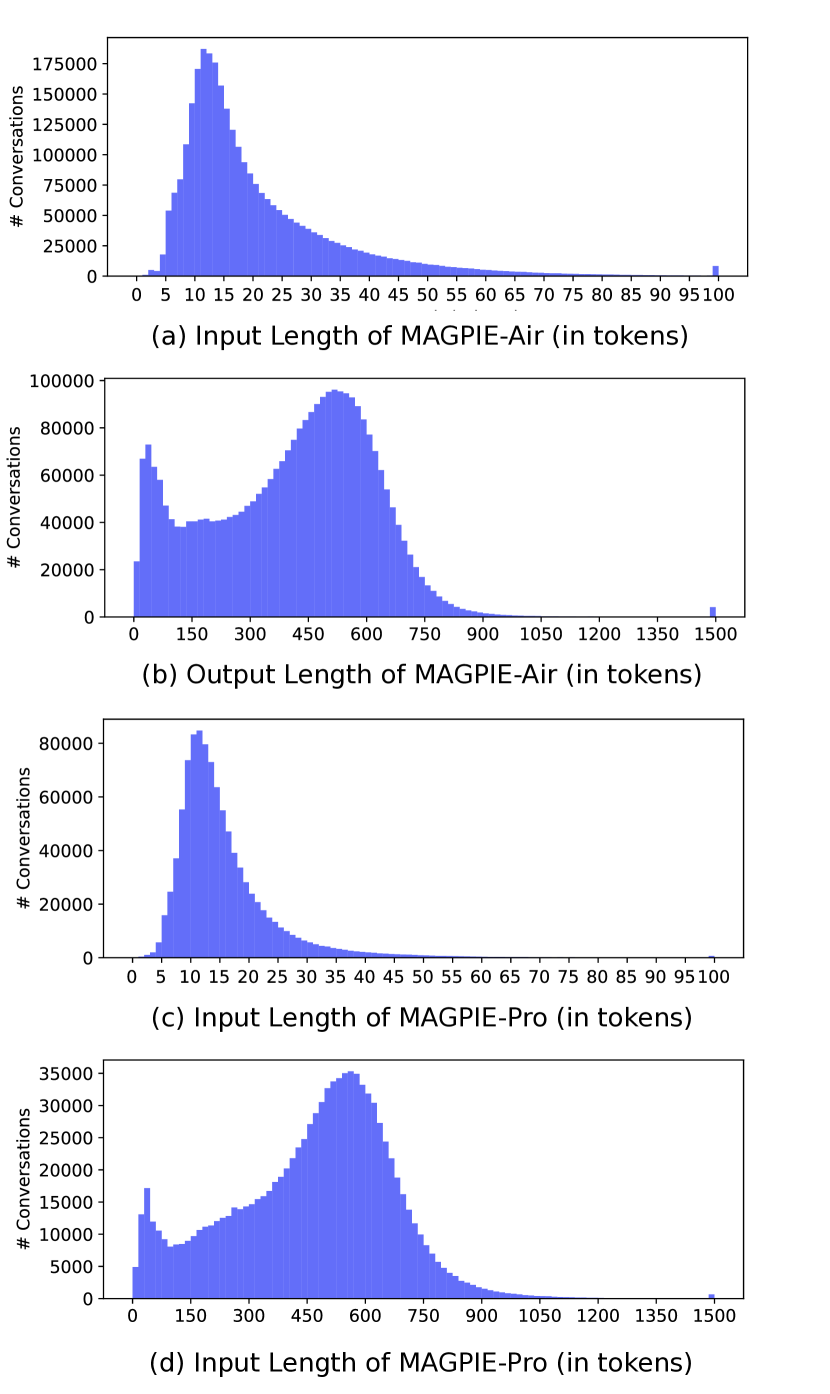
- Magpie は約 4 million の指示と応答を生成でき、フィルタリングされた高品質サブセットとして 300K を効果的な微調整に利用できる。
- Magpie データで Llama-3-8B-base をファインチューニングすると、同様のデータサイズを用いたモデルベースラインより AlpacaEval 2 および Arena-Hard の性能が向上する。
- Magpie データでファインチューニングしたモデルは、公式の Llama-3-8B-Instruct モデルと対等、あるいはそれに匹敵する水準に達する。後者は SFT と RLHF に 1000 万件超のデータを使用している。
- Magpie データは、いくつかの公開指示データセット(ShareGPT、Evol Instruct、UltraChat、OpenHermes、WildChat)および好み調整との組み合わせを用いた場合にもアラインメントベンチマークで優位性を示す。
- Magpie データは Qwen ベースモデルにも適用すると性能を改善し、公式の指示調整済み対モデルを凌ぐ場合がある。
- Magpie はフィルタリング後、広範なトピックをカバーし高品質な指示を提供し、安全性リスクは低い(有害な可能性があるのは <1%)ことを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。