[論文レビュー] MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
この論文は MambaMixer を導入し、デュアルトークンおよびチャネル選択型状態空間モデルブロックを提案し、Vision MambaMixer (ViM2) と Time Series MambaMixer (TSM2) を構築して、長いシーケンスに対して線形の複雑さで競争力のあるまたはそれを上回る性能を実現する。
Recent advances in deep learning have mainly relied on Transformers due to their data dependency and ability to learn at scale. The attention module in these architectures, however, exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are either data independent, or fail to allow inter- and intra-dimension communication. Recently, State Space Models (SSMs), and more specifically Selective State Space Models, with efficient hardware-aware implementation, have shown promising potential for long sequence modeling. Motivated by the success of SSMs, we present MambaMixer, a new architecture with data-dependent weights that uses a dual selection mechanism across tokens and channels, called Selective Token and Channel Mixer. MambaMixer connects selective mixers using a weighted averaging mechanism, allowing layers to have direct access to early features. As a proof of concept, we design Vision MambaMixer (ViM2) and Time Series MambaMixer (TSM2) architectures based on the MambaMixer block and explore their performance in various vision and time series forecasting tasks. Our results underline the importance of selective mixing across both tokens and channels. In ImageNet classification, object detection, and semantic segmentation tasks, ViM2 achieves competitive performance with well-established vision models and outperforms SSM-based vision models. In time series forecasting, TSM2 achieves outstanding performance compared to state-of-the-art methods while demonstrating significantly improved computational cost. These results show that while Transformers, cross-channel attention, and MLPs are sufficient for good performance in time series forecasting, neither is necessary.
研究の動機と目的
- 二次的な注意を超えるスケーラブルな長長序列モデリングの動機付け。
- 情報を効率的に統合するデュアル選択(トークンとチャネル)を備えた MambaMixer ブロックを提案する。
- 視覚タスクと時系列予測のための ViM2 および TSM2 アーキテクチャを紹介する。
- 時系列で計算コストを低く抑えつつ、競争力のある視覚結果と最新に類する性能を示す。
提案手法
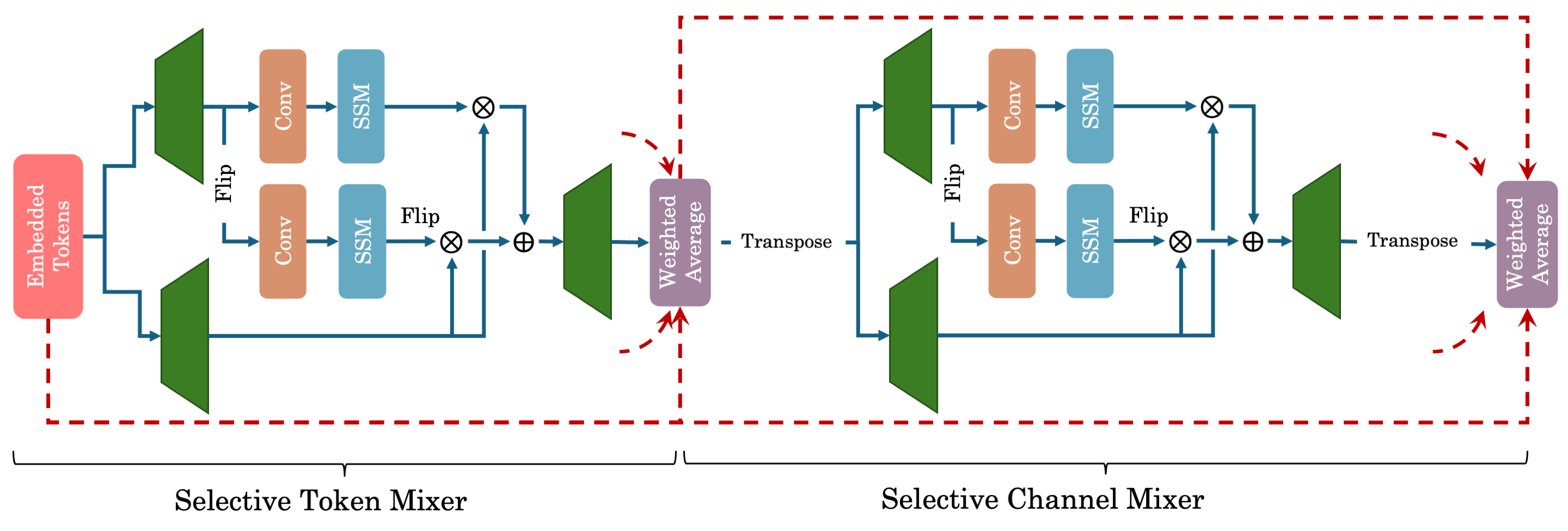
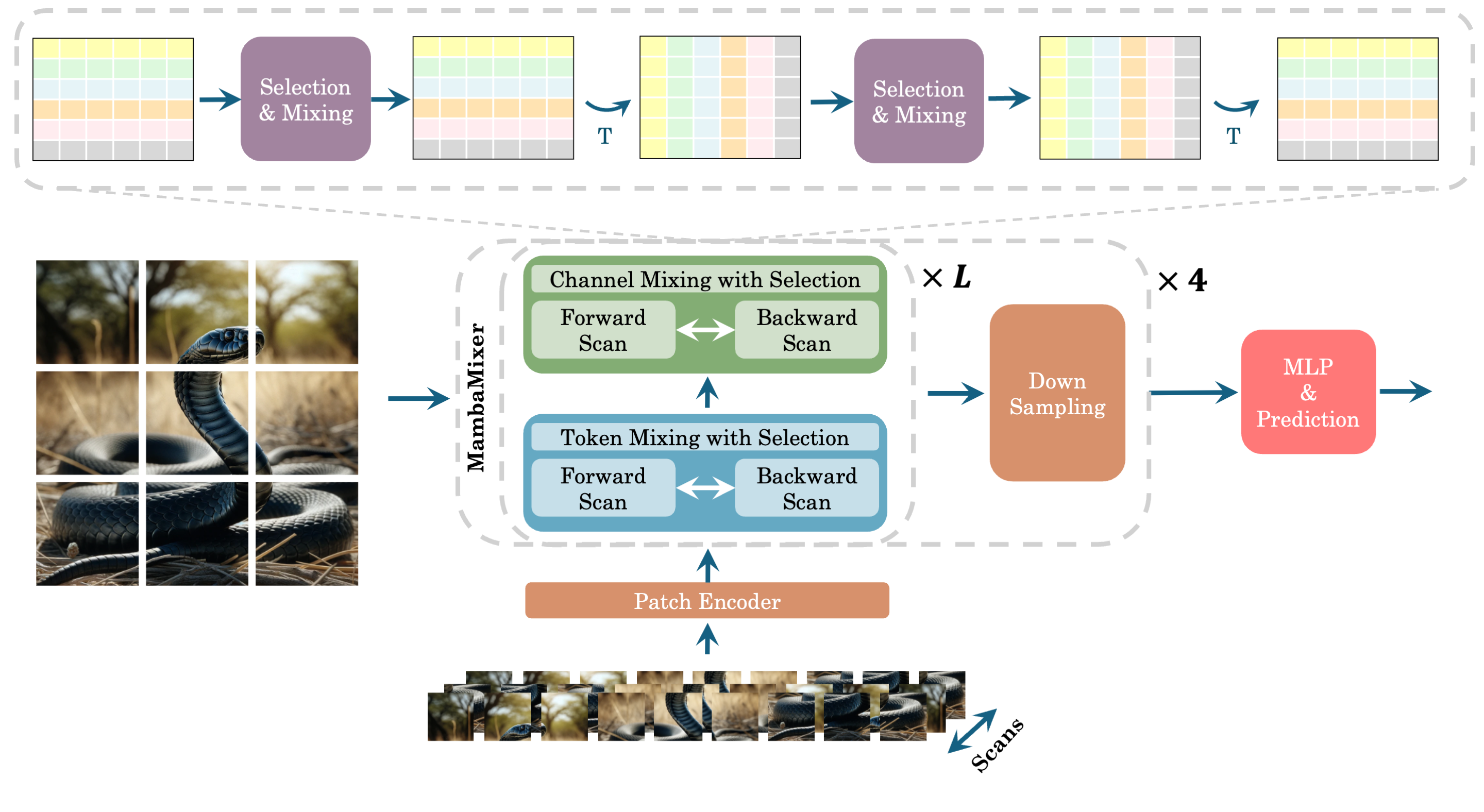
- データ依存の S6 ブロックに基づく Selective Token Mixer および Selective Channel Mixer モジュールを導入する。
- 視覚タスク向けに双方向チャネル混合とマルチスキャン方式を用いて多次元データへ拡張する。
- 層間の早期特徴を結ぶ重み付き平均化機構を組み込む(DenseNet/DenseFormerスタイル)。
- 画像に対して、深さ方向畳み込みとパッチベースの2D処理を用いた ViM2 でのクロススキャンを適用する。
- 2D 正規化と補助情報の取り扱いを伴う、TSM2 の一方向 Selective Token Mixer と双方向 Selective Channel Mixer を適用する。
- ViM2 が MLP-Mixer および VMamba を特殊ケースとして一般化することを示すアーキテクチャ的接続を提供する。
実験結果
リサーチクエスチョン
- RQ1デュアル(トークンとチャネル)選択混合は、単一次元の選択的 SSM よりも、クロストークンおよびクロスチャネルの依存関係のモデリングを改善するか。
- RQ2MambaMixer ベースの ViM2 および TSM2 が、線形の時間・空間計算量を維持しつつ、最先端の視覚モデルおよび時系列モデルと競争力のある結果を達成できるか。
- RQ3提案アーキテクチャは、視覚タスク(ImageNet、物体検出、セマンティックセグメンテーション)および時系列予測における精度と効率の点で、Transformerベースおよび既存のSSMベースモデルとどのように比較されるか。
- RQ4初期特徴の重み付き平均接続が、スケールアップ時のトレーニング安定性と性能に与える影響は何か。
主な発見
- ViM2 は ImageNet で ViT、MLP-Mixer、ConvMixer と競合する性能を達成し、SSM ベースの視覚モデルを上回る。
- TSM2 は多様な時系列データセットで卓越した性能を発揮するとともに、最先端手法と比較して計算コストを大幅に削減する。
- 両モダリティにおいて、トークンとチャネルの選択的混合は、チャネルのみ・トークンのみのアプローチを超える情報フローとモデリング能力を改善する。
- このアーキテクチャは、シーケンス長とチャネル数に関して線形時間・線形空間計算量を維持し、従来の注意機構のスケーラビリティの課題に対処する。
- このモデルは重み付き平均化機構を介して初期特徴への直接アクセスを可能にし、深い MambaMixer ベースのネットワークのトレーニング安定性を向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。