[論文レビュー] Many-Shot In-Context Learning
この論文は、文脈内の例の数が大規模言語モデルの性能にどのように影響するかを調査し、人間のデモンストレーションへの依存を減らすために Reinforced ICL と Unsupervised ICL を導入し、多-shot ICL が事前学習の偏りを克服し非自然言語タスクにも対処できることを示す。
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. We also find that inference cost increases linearly in the many-shot regime, and frontier LLMs benefit from many-shot ICL to varying degrees. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
研究の動機と目的
- イン-context の例(shots)の数を増やすことが、さまざまなタスクにおける LLM の性能にどう影響するかを評価する。
- many-shot ICL における人間生成の推論根拠への依存を減らす方法を開発する。
- ICL の学習動力学を分析し、偏見の覆い、非自然言語タスク、プロンプト順序効果を含めて検討する。
提案手法
- Gemini 1.5 Pro を用いて最大8192shots まで、タスク間で文脈内例を系統的にスケールさせる。
- MT、要約、計画、コード検証などのタスクで、few-shot と many-shot ICL を比較する。
- 回答の正確性でフィルタリングしたモデル生成推論を用いることで Reinforced ICL を導入する。
- 推論根拠なしで問題だけを提示する Unsupervised ICL を導入する。
- バイアスの克服、高次元数値タスク、NLL と ICL パフォーマンスの関係を含む ICL の挙動を分析する。
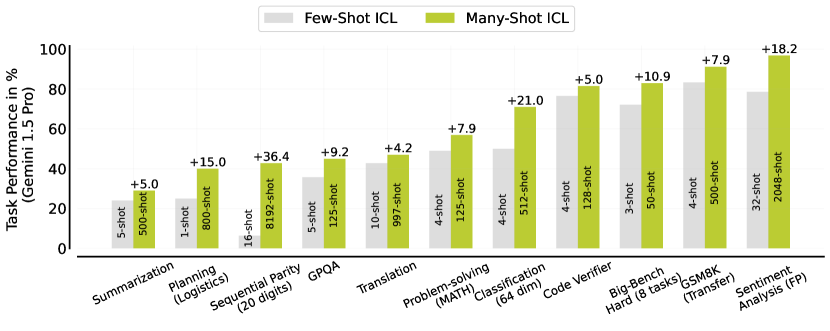
実験結果
リサーチクエスチョン
- RQ1many-shot ICL のパフォーマンスは、few-shot ICL と比較して広範なタスクセットでどのようにスケールするのか?
- RQ2モデル生成の推論根拠(Reinforced ICL)または問題のみのプロンプト(Unsupervised ICL)は、多-shot 設定で人間のデモンストレーションと同等かそれを上回ることができるのか?
- RQ3many-shot ICL は事前学習の偏りを克服し、非自然言語や数値タスクの学習を可能にするのか?
- RQ4次トークン予測損失を ICL の成功予測指標として用いることの限界は何か?
- RQ5many-shot ICL は例の順序や文脈長にどれだけ敏感か?
主な発見
- Many-shot ICL はタスク全体で顕著な性能向上をもたらし、しばしば shots が数百〜数千トークンに達する時にピークに達する。
- Reinforced ICL と Unsupervised ICL は多くの設定で人間が書いた推論根拠を上回るか同等に達することができ、特に複雑な推論タスクで顕著である。
- Many-shot ICL は事前学習の偏りを克服し、逐次的奇偶性や線形分類など高次元の数値タスクを学習できる。
- 文脈内の例の順序は、多-shot ICL においてもパフォーマンスに大きく影響する。
- 次トークン予測損失は、問題解決および推論タスクにおける下流の ICL 性能を信頼性高く予測しない可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。