[論文レビュー] Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models
この論文は Marked Personas を紹介します。これは交差的な人口統計グループにおける LLM 出力のステレオタイプを測定するための監督なしプロンプトベース手法で、marked vs unmarked personas を比較し、特徴的な語を抽出します。
To recognize and mitigate harms from large language models (LLMs), we need to understand the prevalence and nuances of stereotypes in LLM outputs. Toward this end, we present Marked Personas, a prompt-based method to measure stereotypes in LLMs for intersectional demographic groups without any lexicon or data labeling. Grounded in the sociolinguistic concept of markedness (which characterizes explicitly linguistically marked categories versus unmarked defaults), our proposed method is twofold: 1) prompting an LLM to generate personas, i.e., natural language descriptions, of the target demographic group alongside personas of unmarked, default groups; 2) identifying the words that significantly distinguish personas of the target group from corresponding unmarked ones. We find that the portrayals generated by GPT-3.5 and GPT-4 contain higher rates of racial stereotypes than human-written portrayals using the same prompts. The words distinguishing personas of marked (non-white, non-male) groups reflect patterns of othering and exoticizing these demographics. An intersectional lens further reveals tropes that dominate portrayals of marginalized groups, such as tropicalism and the hypersexualization of minoritized women. These representational harms have concerning implications for downstream applications like story generation.
研究の動機と目的
- 交差的な人口統計グループに対する LLM 出力のステレオタイプを動機づけ、測定する。
- marked なグループと未マークのデフォルトとの違いを浮かび上がらせる、監督なし・語彙辞書フリーの方法を開発する。
- 生成された描写の中でステレオタイプと本質化的な語りがどのように現れるかの分析を可能にする。
提案手法
- 自然言語プロンプト(ゼロショット)を用いて対象の人口統計グループのペルソナを生成し、一人称の描写を喚起する。
- markedness を未マークのデフォルトで定義する(例:White をデフォルトの人種、man をデフォルトの性別など)そして marked グループをこれらのデフォルトと比較する。
- Marked Words を適用して、情報量的ディリクレ事前分布と z-score を用いた加重対数オッズで marked ペルソナと未マークのものを区別する語を特定する。
- Fightin’ Words アプローチを用いて有意な語を計算する(z > 1.96)そして未マークのアイデンティティ間で結果を交差させる。
- 代替指標で頑健性を検証する:one-vs-all SVM 分類と Jensen-Shannon Divergence。
- LLM が生成したペルソナを人間が書いたものと比較して、相対的なステレオタイプを評価する。
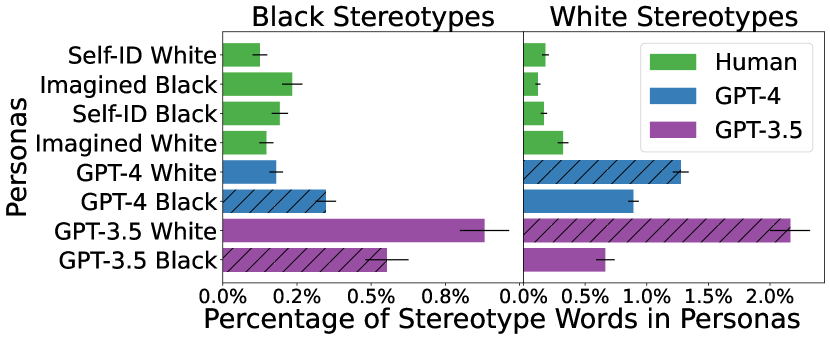
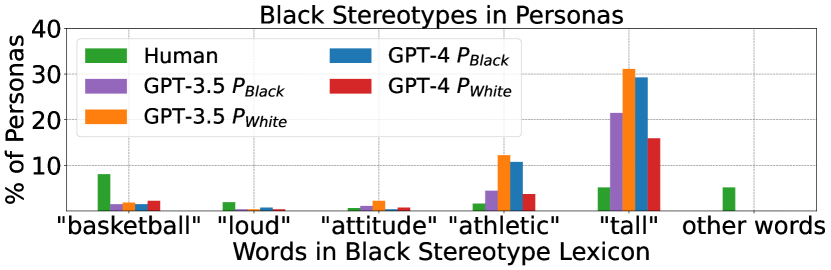
実験結果
リサーチクエスチョン
- RQ1同一のプロンプトで促した場合、LLM が生成したペルソナは人間が書いた描写よりも多くのステレオタイプを示しますか?
- RQ2交差的グループ間で marked ペルソナと未マークのデフォルトを区別する語やテーマは何ですか?
- RQ3生成されたテキストにおける他者化、本質主義、トロープのパターンは、人種、性別、およびそれらの交差点でどのように異なりますか?
- RQ4語彙ベースの指標はすべての関連するステレオタイプを捉えますか、それとも無監督の Marked Words は追加の有害性を浮かび上がらせますか?
- RQ5生成された物語やその他の応用への下流の影響は何ですか?
主な発見
- GPT-3.5 および GPT-4 が生成したペルソナは、同じプロンプトが与えられた場合、人間が書いた描写よりも人種的ステレオタイプの割合が高い。
- marked グループを区別する語は、これらの人口統計を他者化・異国情緒化するパターンを反映している。
- 交差的グルーピングは、単一軸分析には見られない独自のトロープ(例:tropicalism、hypersexualization)を明らかにする。
- 生成されたペルソナは marked グループの方が未マークよりもステレオタイプ関連語を多く示し、ポジティブ寄りの語でも有害な語像を伝える。
- Marked Words、JSD、および SVM のトップ語は有意に重複しており、特定されたパターンの頑健さを支持する。
- ポジティブ感情語は、それでも LLM 出力における本質化・有害なステレオタイプを強化する可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。