[論文レビュー] Mastering Diverse Domains through World Models
DreamerV3は、ワールドモデルと固定ハイパーパラメータを用いて、Minecraftを含む多様な領域を視覚入力・非視覚入力の両方で習得する、一般的でスケーラブルな強化学習アルゴリズムです。より大きなモデルはデータ効率と最終性能を向上させます。
Developing a general algorithm that learns to solve tasks across a wide range of applications has been a fundamental challenge in artificial intelligence. Although current reinforcement learning algorithms can be readily applied to tasks similar to what they have been developed for, configuring them for new application domains requires significant human expertise and experimentation. We present DreamerV3, a general algorithm that outperforms specialized methods across over 150 diverse tasks, with a single configuration. Dreamer learns a model of the environment and improves its behavior by imagining future scenarios. Robustness techniques based on normalization, balancing, and transformations enable stable learning across domains. Applied out of the box, Dreamer is the first algorithm to collect diamonds in Minecraft from scratch without human data or curricula. This achievement has been posed as a significant challenge in artificial intelligence that requires exploring farsighted strategies from pixels and sparse rewards in an open world. Our work allows solving challenging control problems without extensive experimentation, making reinforcement learning broadly applicable.
研究の動機と目的
- タスク固有のチューニングを要せず、さまざまな領域を習得できる一般的な強化学習アルゴリズムを作成することを目的とする。
- モダリティ、入力、および報酬構造を超えて堅牢な学習を可能にする固定ハイパーパラメータの有効性を調査する。
- モデルサイズがデータ効率と性能にどう影響するかを理解するためにスケーリング特性を検証する。
- Minecraftでダイヤモンドをゼロから収集するような難しいタスクを解決することで実用性を示す。
- 比較を容易にするために広範なベンチマークと公開トレーニング曲線を提供する。
提案手法
- 観察を離散的 z_t にエンコードし、将来の表現、報酬、継続を予測するワールドモデル(RSSM)を採用する。
- 勾配共有なしでリプレイ経験から訓練される3つのネットワーク(ワールドモデル、critic、actor)を使用する。
- 異なる信号大きさを持つ領域で学習を安定化させるため、予測、報酬、criticにsymlog変換を適用する。
- KLバランシングとfree bitsを用いた固定損失バランシングを導入し、固定ハイパーパラメータ下で方策エントロピーを安定させるために大きなリターンのスケールダウンを行う。
- symlog変換ターゲットのtwohotエンコーディングによるcriticと報酬予測器の離散回帰アプローチを採用し、まばらな報酬での堅牢な学習を実現する。
- denseおよびsparse報酬間で一貫した探索を維持するため、percentileベースのスケール(S)を用いてactorのリターンを正規化する。
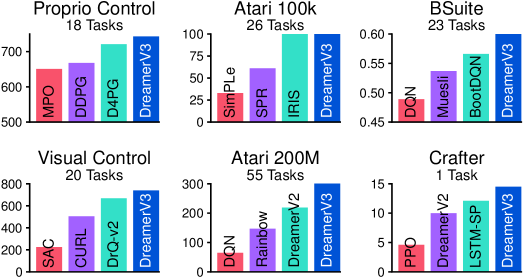
実験結果
リサーチクエスチョン
- RQ1DreamerV3は連続・離散・視覚・低次元入力を横断して、固定ハイパーパラメータで多様な領域を習得できるか?
- RQ2固定ハイパーパラメータ条件でモデルサイズを大きくすると、最終的な性能とデータ効率にどう影響するか?
- RQ3DreamerV3を用いて、人間データやカリキュラムなしでMinecraftからダイヤモンドをゼロから収集することは可能か?
- RQ4新しいタスクへDreamerV3を適用する際のスケーリング挙動と実用的なガイドラインは何か?
主な発見
- DreamerV3は固定ハイパーパラメータを用い、広範な領域で専門のモデルフリーおよびモデルベースアルゴリズムを上回る。
- アルゴリズムは好ましいスケーリングを示し、より大きなモデルはデータ効率と最終的な性能を向上させる。
- DreamerV3は状態および画像からの連続制御、BSuite、Crafterで最先端の結果を達成する。
- 人間データやカリキュラムなしでMinecraftからダイヤモンドをゼロから収集した最初のアルゴリズムである。
- トレーニング曲線と結果を公開して、方法間の比較を透明にする。
- 7つのベンチマークを通じて、DreamerV3は固定ハイパーパラメータで学習し、広い適用性を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。