[論文レビュー] Matching Networks for One Shot Learning
Matching Networksは、ニューラルネットワークを外部メモリとアテンションと組み合わせることで迅速なワンショット学習を実現し、新しいクラスへ微調整なしに予測を可能にします。Omniglotと Mini/ImageNet のタスクでワンショット精度の最先端を達成し、ワンショットの言語モデリングタスクにも拡張します。
Learning from a few examples remains a key challenge in machine learning. Despite recent advances in important domains such as vision and language, the standard supervised deep learning paradigm does not offer a satisfactory solution for learning new concepts rapidly from little data. In this work, we employ ideas from metric learning based on deep neural features and from recent advances that augment neural networks with external memories. Our framework learns a network that maps a small labelled support set and an unlabelled example to its label, obviating the need for fine-tuning to adapt to new class types. We then define one-shot learning problems on vision (using Omniglot, ImageNet) and language tasks. Our algorithm improves one-shot accuracy on ImageNet from 87.6% to 93.2% and from 88.0% to 93.8% on Omniglot compared to competing approaches. We also demonstrate the usefulness of the same model on language modeling by introducing a one-shot task on the Penn Treebank.
研究の動機と目的
- 新しいクラスに対してラベル付きの例がわずかしか用意できないワンショット学習設定の動機付け。
- ファインチューニングなしで、少量のラベル付きサポートセットを用いて未観測のテスト例を分類するニューラルアーキテクチャを提案する。
- 視覚と言語タスクにおけるワンショット学習を評価するための訓練手順とベンチマークを定義する。
- Omniglot、ImageNet、および Penn Treebank 言語タスクで最先端のワンショット性能を示す。
提案手法
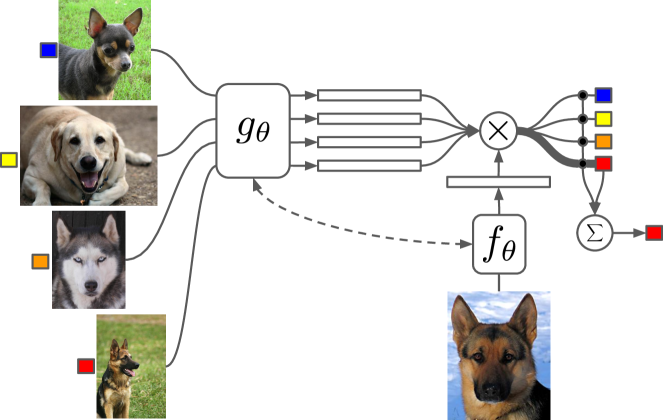
- サポートセット S を P(y|x,S) によってテスト入力の分類器 c_S に写像する Matching Networks を導入する。
- 埋め込み表現 f(x̂) と g(x_i) のコサイン類似度に基づくアテンション機構 a(x̂,x_i) を用いる。
- Bidirectional LSTMs を用いた Fully Conditional Embedding によって、サポート全体の S に基づいて x_i を条件付けし、埋め込みを文脈依存にする (g(x_i,S))。
- セットエンコードされたサポート上で attLSTM を用いて f(x̂,S) を計算し、メモリの多段読み出しを可能にする。
- エピソード型メタ学習で訓練する。各エピソードはラベル集合 L と対応するサポート S およびバッチ B をサンプルし、S に条件付けた B の予測を最適化する(新しいクラスのファインチューニングは行わない)。
- Full Context Embeddings (FCE) を探索し、埋め込みをサポート全体に条件付けることで性能を改善する。
実験結果
リサーチクエスチョン
- RQ1新しいクラスに対してラベル付きの例がわずかしか用意できない場合、ニューラルモデルは未観測のクラスをファインチューニングなしで分類できるか。
- RQ2アテンションと外部メモリ機構を統合して、視覚と言語のモダリティを横断してワンショット学習を実現できるか。
- RQ3エピソードベースのメタ学習を用いた訓練は、従来の教師あり訓練と比べて新規ラベル集合への一般化を改善するか。
- RQ4ImageNet のような大規模データセットおよび言語タスクで、Matching Networks の限界は何か。
主な発見
- Matching Networks は 1-shot Omniglot 評価で 93.8% の 5-way 精度を達成し(別の設定ではコサイン類似度を用いた 1-shot 5-way で 98.1%)、
- mini ImageNet では、コサイン設定で 41.2%(1-shot, 5-way)および 56.2%(5-shot, 5-way)精度でベースラインを上回し、FCE でさらに改善。
- 完全な ImageNet の 5-way 1-shot タスクでは、FCE を用いた Matching Networks は L_rand で 93.2%、≠L_rand で 97.0(特定のスプリット下で犬の変種で 58.8%/96.4%)に達する。
- Penn Treebank 言語ワンショットタスクでは、単純な Matching Networks エンコーディングが k=1,2,3 に対してそれぞれ 32.4%, 36.1%, 38.2% の精度を達成(LSTM-LM オラクルには到達しない)。
- FCE はいくつかの画像ベンチマークにおいて非 FCE バリアントより一貫して小幅な利得(おおよそ 2 ポイント程度)を提供します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。