[論文レビュー] Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
この論文は MathQuest を紹介します。NCERT 由来の高校数学データセットであり、NCERT スタイルの問題に対して fine-tuned LLMs(MAmmoTH、LLaMA-2、WizardMath)をベンチマークし、テスト対象モデルの中で最も良い成績を示したのは MAmmoTH-13B である。
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called "MathQuest" sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
研究の動機と目的
- 高校数学における算術と多段推論の評価を改善する動機づけ。
- 複数ドメインに及ぶ NCERT 派生の数学問題データセットである MathQuest の作成。
- 拡張された Math-401 データでのファインチューニングがデータセット間の性能に与える影響を評価。
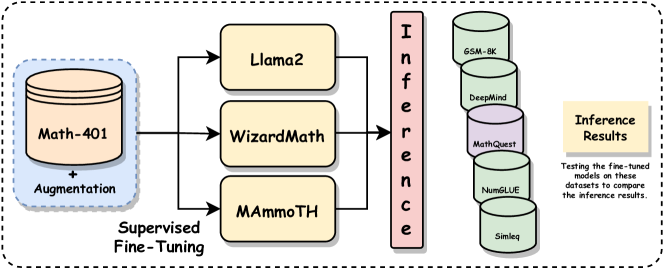
- MathQuest および他のベンチマークでの LLaMA-2、WizardMath、MAmmoTH の基準を設定し、モデルを比較。
提案手法
- 14 ドメインと 223 サンプルを含む NCERT ベースの数学問題コーパスとして MathQuest を組み立てる。
- Math-401 データセットを SymPy によって追加の算術問題で増強し、多様性を高める。
- QLora を用いた 4-bit 量子化と LoRA アダプタで、3 つの LLM ファミリー(LLaMA-2、WizardMath、MAmmoTH)をファインチューニング。
- 学習率 3e-4、AdamW、10 エポック、トレイン/バリデーション/テスト分割(241,600 / 30,200 / 30,200)で訓練。
- ファインチューニングの前後で GSM-8K、DeepMind、NumGLUE、SimulEq、Math-401*、MathQuest における正解一致度(exact-match accuracy)を評価。
- スケール効果を評価するために 7B および 13B の変種を比較。
実験結果
リサーチクエスチョン
- RQ1NCERT 派生の数学問題は現在のオープンソース LLMs(7B/13B)をどのように挑戦させるか。
- RQ2拡張された数学データセット(Math-401)を用いたファインチューニングが NCERT 風の問題に対してどの程度の改善をもたらすか。
- RQ3MathQuest および他のベンチマークで、どのモデルとサイズが高校レベルの数学的問題解決に最も適しているか。
主な発見
| Model | GSM-8K | DeepMind | NumGLUE | SimulEq | Math-401* | MathQuest |
|---|---|---|---|---|---|---|
| LLaMA-2 7B | 30.0 | 46.0 | 45.0 | 15.0 | 17.0 | 10.6 |
| LLaMA-2 13B | 42.0 | 51.0 | 54.0 | 16.0 | 24.0 | 20.3 |
| WizardMath 7B | 64.0 | 55.0 | 52.0 | 29.0 | 15.0 | 16.0 |
| WizardMath 13B | 68.0 | 56.0 | 70.0 | 38.0 | 10.0 | 20.1 |
| MAmmoTH 7B | 56.0 | 50.0 | 62.0 | 24.0 | 16.0 | 18.5 |
| MAmmoTH 13B | 67.0 | 51.0 | 64.0 | 34.0 | 18.0 | 24.0 |
- MAmmoTH-13B はファインチューニング後の MathQuest でテスト済みモデルの中で最高の正解率を達成(24.0%)。
- 13B モデルは、ファインチューニング後にベンチマーク全体で 7B の対となるモデルを一般的に上回る。
- MathQuest は他のデータセットより難易度が高く、ファインチューニング後の正解率は全体として低い。
- すべてのモデルはファインチューニング後に顕著な精度向上を示し、ファインチューニング後の結果は事前チューニングのベースラインから改善。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。