[論文レビュー] MedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records
MedAlign は 983 EHR ベースの指示の臨床医生成ベンチマークで、6 つの LLM を評価し、文脈長の影響と自動評価指標を研究します。
The ability of large language models (LLMs) to follow natural language instructions with human-level fluency suggests many opportunities in healthcare to reduce administrative burden and improve quality of care. However, evaluating LLMs on realistic text generation tasks for healthcare remains challenging. Existing question answering datasets for electronic health record (EHR) data fail to capture the complexity of information needs and documentation burdens experienced by clinicians. To address these challenges, we introduce MedAlign, a benchmark dataset of 983 natural language instructions for EHR data. MedAlign is curated by 15 clinicians (7 specialities), includes clinician-written reference responses for 303 instructions, and provides 276 longitudinal EHRs for grounding instruction-response pairs. We used MedAlign to evaluate 6 general domain LLMs, having clinicians rank the accuracy and quality of each LLM response. We found high error rates, ranging from 35% (GPT-4) to 68% (MPT-7B-Instruct), and an 8.3% drop in accuracy moving from 32k to 2k context lengths for GPT-4. Finally, we report correlations between clinician rankings and automated natural language generation metrics as a way to rank LLMs without human review. We make MedAlign available under a research data use agreement to enable LLM evaluations on tasks aligned with clinician needs and preferences.
研究の動機と目的
- 実際的な EHR 指示遵守ベンチマークが医師のタスクと負担を表す必要性を動機づける。
- MedAlign を作成: 複数の専門分野にわたる、臨床医生成の多様な EHR ベース指示集合。
- 現実的なタスクで LLM 評価を可能にする、EHR と臨床医作成の金回答の対を提供する。
- 臨床医の判断の代理として自動指標を調査し、スケーラブルな評価を可能にする。
提案手法
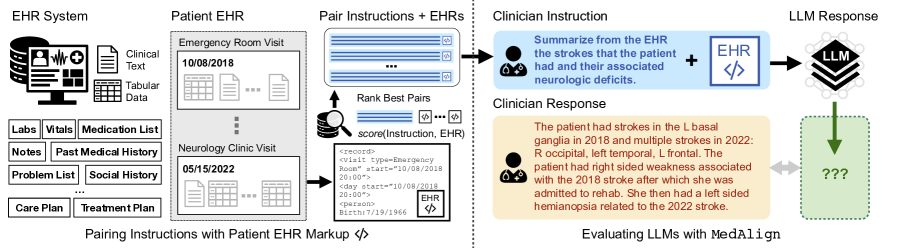
- 7つの専門分野にまたがる15人の臨床医から指示を収集し、983指示を形成。
- 情報検索ベースの BM25 マッチングアプローチを介して指示と EHR を対にし、関連する指示–EHR ペアを取得。
- 臨床医がEHRに基づく303指示に金回答を作成し、6つのLLMを評価。
- モデルの識別をブラインドにした臨床医判断によって、正確さと品質を評価。
- 自動 NLG 指標(例: COMET、BERTScore)と人間のランキングとの相関を分析。
実験結果
リサーチクエスチョン
- RQ1臨床医生成の EHR 指示を長期の EHR データと効果的に対にして、現実的な指示遵守ベンチマークを形成できるか。
- RQ2最新の LLM は、医療現場の判断と比較して長く EHR に根ざした指示でどの程度の性能を示すか。
- RQ3自動 NLG 指標は、EHR 指示遵守設定で臨床医のランキングと相関するか。
主な発見
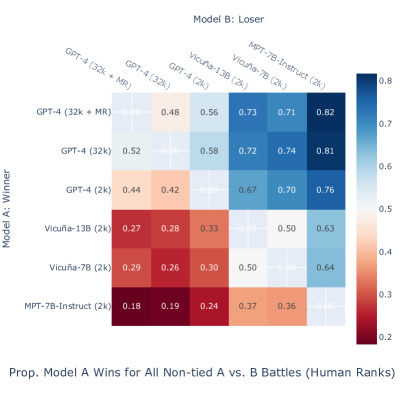
- GPT-4 の派生はオープンモデルより高い正確性を達成、例: 65.0% (GPT-4 32k + MR) および 60.1% (GPT-4 32k) に対し、35.0% (Vicuña-13B)、33.3% (Vicuña-7B)、31.7% (MPT-7B-Instruct)。
- GPT-4 の 32k コンテキストと多段階精製は、他モデルに対する対戦勝率の最も高い値を生み出した(0.676)。
- 文脈長は正確性に大きな影響を与え、GPT-4 のコンテキストを 2k から 32k トークンへ増やすと正解の応答が 8.3% 増加した。
- 自動指標 COMET は臨床医のランキングと最も強い相関を示し(0.37、評価者間信頼性 0.44 に近い)。
- モデル出力を評価する臨床医間の平均信頼性は 0.44( Kendall の Tau)。
- BERTScore(0.34)や METEOR(0.32)などの自動指標は人間のランキングと中程度の相関を示した。一部の指標は相関が弱かった。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。