[論文レビュー] Medical diffusion on a budget: Textual Inversion for medical image generation
著者らは、事前学習済みの Stable Diffusion モデルを、100件の例だけを消費者向けGPU上でのテキスト逆推定を通じて小さなテキスト埋め込みを訓練することで、複数の医用画像モダリティに適用可能であることを示しており、現実的な医用画像生成、データ拡張、柔軟な病気操作を実現する。
Diffusion models for text-to-image generation, known for their efficiency, accessibility, and quality, have gained popularity. While inference with these systems on consumer-grade GPUs is increasingly feasible, training from scratch requires large captioned datasets and significant computational resources. In medical image generation, the limited availability of large, publicly accessible datasets with text reports poses challenges due to legal and ethical concerns. This work shows that adapting pre-trained Stable Diffusion models to medical imaging modalities is achievable by training text embeddings using Textual Inversion. In this study, we experimented with small medical datasets (100 samples each from three modalities) and trained within hours to generate diagnostically accurate images, as judged by an expert radiologist. Experiments with Textual Inversion training and inference parameters reveal the necessity of larger embeddings and more examples in the medical domain. Classification experiments show an increase in diagnostic accuracy (AUC) for detecting prostate cancer on MRI, from 0.78 to 0.80. Further experiments demonstrate embedding flexibility through disease interpolation, combining pathologies, and inpainting for precise disease appearance control. The trained embeddings are compact (less than 1 MB), enabling easy data sharing with reduced privacy concerns.
研究の動機と目的
- 自然画像で訓練された拡散モデルを、テキスト反転を介して複数の医用画像モダリティへ適用できることを実証する。
- 埋め込みサイズ、訓練ケース数、推論設定が医療分野の生成品質にどう影響するかを評価する。
- 実用的な適用例を示す:分類のための合成データ拡張、病気進行の補間、病変を特定の場所に出すインペインティング。
- 医療データの共有に適したプライバシーに優しい小型埋め込みを強調する。
提案手法
- テンプレートなしで埋め込み名のみを用いて医療概念ごとに新しいトークン埋め込みをテキスト逆推定で訓練する。
- 学習率を一定に保ち (0.005)、各クラス100件、ステップ数50,000、バッチサイズ1で埋め込みを訓練する。
- 訓練時のプロンプトは埋め込み名のみを使用(テンプレートなし)、評価は設定ごとに100個の生成サンプルと現実サンプル100個を比較する Fréchet Inception Distance (FID) を適用。
- 推論パラメータ(サンプリングステップ、CFGスケール)と埋め込みベクトルサイズ(8–64)を評価して最適な生成品質を決定する。
- 複数の埋め込みをプロンプトで組み合わせて、複数の病理を含む画像や病気進行の異なる組成を生成することで、構成可能な拡散を実演する。
- マスク領域を用いてインペインティングを行い、病気の埋め込みで拡散モデルを条件付けて病変を特定の場所に配置する。

実験結果
リサーチクエスチョン
- RQ1テキスト逆推定は、100件の訓練ケースだけで事前学習済みの自然画像拡散モデルを多様な医用画像モダリティに適用できるか?
- RQ2埋め込みサイズ、訓練ケース数、推論設定は医用画像の生成品質にどう影響するか?
- RQ3埋め込みは医用画像での構成プロンプト、病気進行の補間、特定のインペインティングをサポートできるか?
- RQ4埋め込みから生成された合成データは、低データ環境での下流の医療分類を改善するか?
主な発見
- クラスあたり100件、ベクトルサイズ64で訓練された埋め込みは、サイズが小さいものやケース数が少ない場合よりも生成のリアリズムが優れている。
- 訓練ケース数を増やすことは、ステップ数や CFG スケールの控えめな変更よりも埋め込みの品質を改善する。
- 2000件の合成ケースを追加した際、マルチモーダルMRIで訓練された前立腺がん分類器の AUROC が 0.78 から 0.80 に、絶対的な利得は 2% に上昇した。
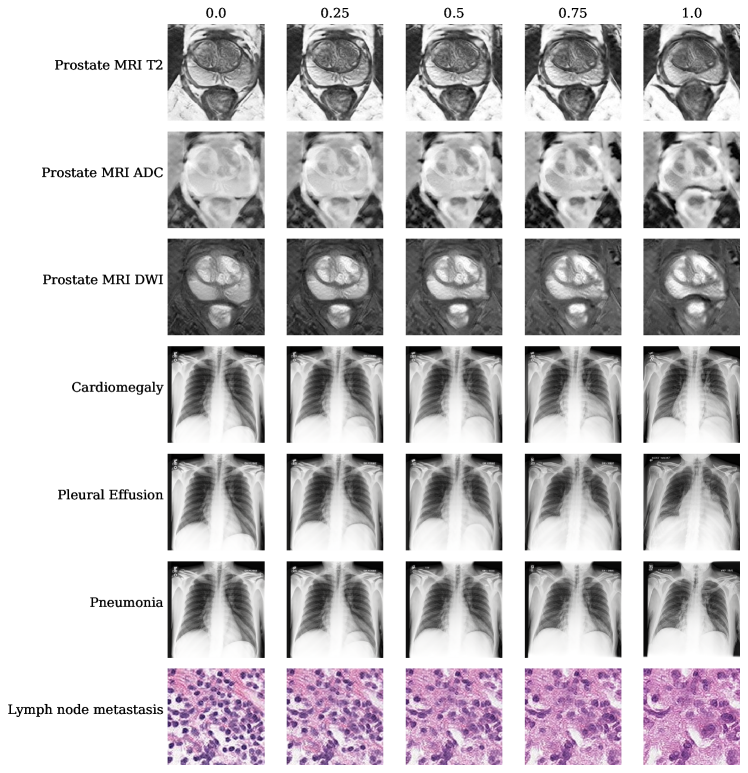
- 埋め込みは健康状態と病的状態の間を補間し、単一画像で複数の病理を組み合わせることを可能にする。
- インペインティングは病変を特定の画像領域に正確に配置でき、病変の場所と程度を制御できる。
- 訓練済み埋め込みは小さく(1 MB未満)プライバシーの懸念を低減して共有できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。