[論文レビュー] Medical Graph RAG: Towards Safe Medical Large Language Model via Graph Retrieval-Augmented Generation
MedGraphRAGは医療用LLMのためのグラフベースの Retrieval-Augmented Generation(RAG)パイプラインを導入し、階層的な医療知識グラフと U-retrieve に基づく検索戦略を構築することで、出典を根拠づけた安全性の高い回答を実現します。
We introduce a novel graph-based Retrieval-Augmented Generation (RAG) framework specifically designed for the medical domain, called extbf{MedGraphRAG}, aimed at enhancing Large Language Model (LLM) capabilities for generating evidence-based medical responses, thereby improving safety and reliability when handling private medical data. Graph-based RAG (GraphRAG) leverages LLMs to organize RAG data into graphs, showing strong potential for gaining holistic insights from long-form documents. However, its standard implementation is overly complex for general use and lacks the ability to generate evidence-based responses, limiting its effectiveness in the medical field. To extend the capabilities of GraphRAG to the medical domain, we propose unique Triple Graph Construction and U-Retrieval techniques over it. In our graph construction, we create a triple-linked structure that connects user documents to credible medical sources and controlled vocabularies. In the retrieval process, we propose U-Retrieval which combines Top-down Precise Retrieval with Bottom-up Response Refinement to balance global context awareness with precise indexing. These effort enable both source information retrieval and comprehensive response generation. Our approach is validated on 9 medical Q\&A benchmarks, 2 health fact-checking benchmarks, and one collected dataset testing long-form generation. The results show that MedGraphRAG consistently outperforms state-of-the-art models across all benchmarks, while also ensuring that responses include credible source documentation and definitions. Our code is released at: https://github.com/MedicineToken/Medical-Graph-RAG.
研究の動機と目的
- 検証可能な医療情報源に回答を根拠づけることにより、医療用LLMにおける幻覚のリスクに対処する。
- ユーザデータ、医療文献、UMLS語彙を統合する3層階層グラフを開発する。
- グローバルな文脈と関連グラフセグメントへの効率的なアクセスを両立させる検索機構(U-retrieve)を実装する。
- 追加のモデルファインチューニングなしで医療QAベンチマークを改善することを実証する。
- 臨床的問いに対してエビデンスに基づく出典根拠の説明を提供する能力を示す。
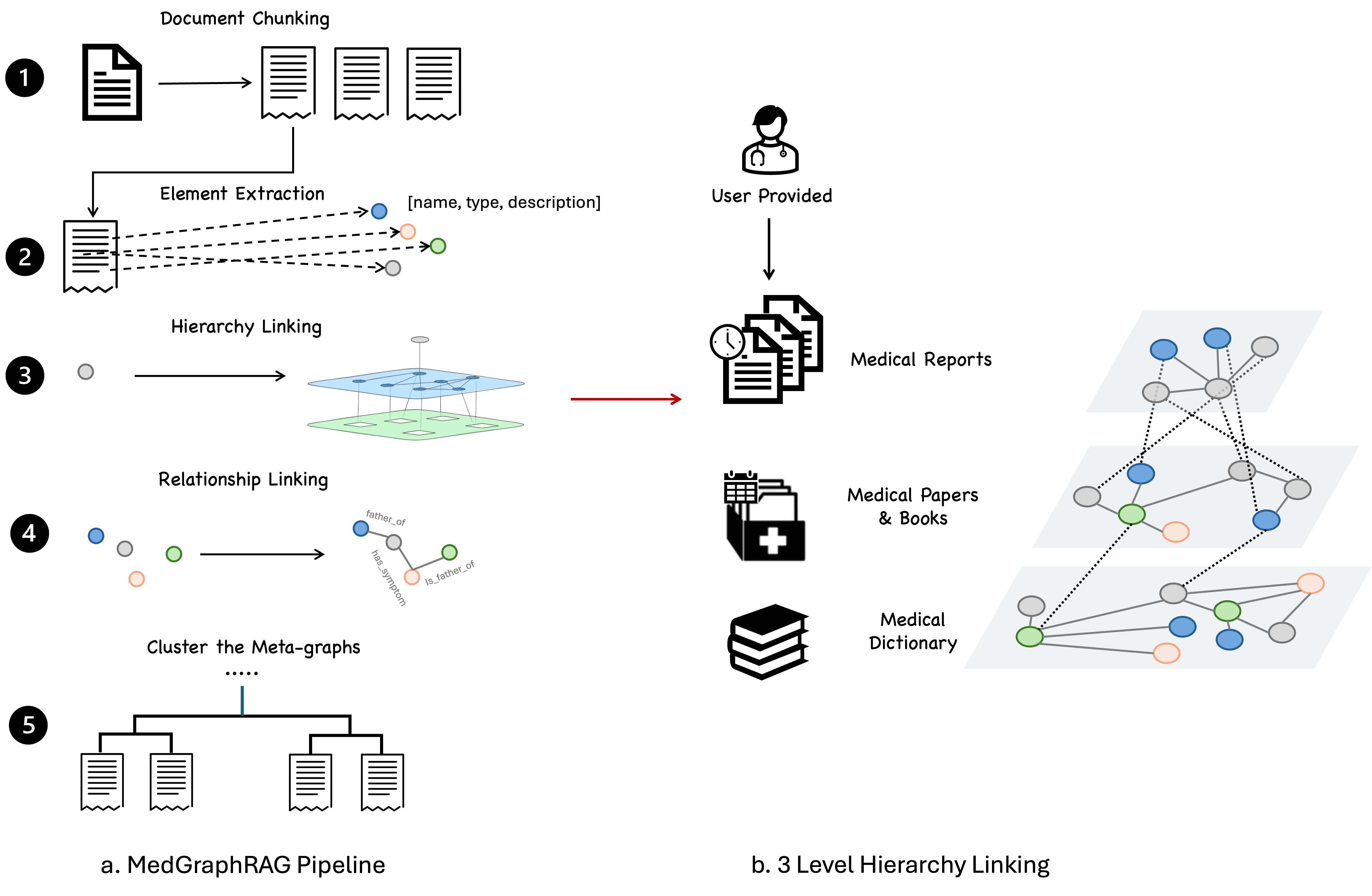
提案手法
- 文脈を捉えるためにハイブリッドな静的-意味的チャンク化アプローチを用いて医療文書をセグメント化する。
- チャンクからエンティティを抽出し、3レベルのグラフを構築する:ユーザ文書、基礎的な医療書籍・論文、およびUMLSベースの用語。
- エンティティをメタグラフへリンクし、意味的類似性に基づいてグローバルグラフに統合する。
- データチャンクごとにメタグラフを構築し、U-retrieveを用いて上位-下位両方の生成を行い、出典引用付きの回答を作成する。
実験結果
リサーチクエスチョン
- RQ1ファインチューニングなしで3層階層の医療グラフは、LLM生成の医療回答の正確性と信頼性を向上させられるか?
- RQ2ユーザデータ、医療文献、およびUMLS根拠語を統合することは幻覚を減らし、医療主張の根拠づけを改善するか?
- RQ3検索精度と回答品質の観点から、U-retrieveは他の検索戦略とどう比較されるか?
- RQ4階層型グラフ構築と高度なチャンク化が医療QAベンチマークに与える影響は?
- RQ5MedGraphRAGの出力は臨床利用に適した検証可能な出典ベースの説明を提供するか?
主な発見
| モデル | サイズ | オープンソース | MedQA | MedMCQA | PubMedQA |
|---|---|---|---|---|---|
| LLaMA2 | 13B | yes | 42.7 | 37.4 | 68.0 |
| LLaMA2-MedGraphRAG | 13B | yes | 65.5 | 51.4 | 73.2 |
| LLaMA2 | 70B | yes | 43.7 | 35.0 | 74.3 |
| LLaMA2-MedGraphRAG | 70B | yes | 69.2 | 58.7 | 76.0 |
| LLaMA3 | 8B | yes | 59.8 | 57.3 | 75.2 |
| LLaMA3-MedGraphRAG | 8B | yes | 74.2 | 61.6 | 77.8 |
| LLaMA3 | 70B | yes | 72.1 | 65.5 | 77.5 |
| LLaMA3-MedGraphRAG | 70B | yes | 88.4 | 79.1 | 83.8 |
| Gemini-pro | - | no | 59.0 | 54.8 | 69.8 |
| Gemini-MedGraphRAG | - | no | 72.6 | 62.0 | 76.2 |
| GPT-4 | - | no | 81.7 | 72.4 | 75.2 |
| GPT-4 MedGraphRAG | - | no | 91.3 | 81.5 | 83.3 |
| Human (expert) | - | - | 87.0 | 90.0 | 78.0 |
- MedGraphRAGは、さまざまなモデル(例:MedQA、MedMCQA、PubMedQA)で複数の医療QAベンチマークを著しく向上させる。
- 小型LLM(例:LLaMA2-13B、LLaMA3-8B)は顕著な向上を得て、適用範囲を大規模モデル以外にも拡げる。
- GPT-4では、MedGraphRAGがMedQAで最先端の結果を達成し、いくつかのファインチューニング済みベースラインを凌駕する。
- 回答には根拠ある引用と医療用語の説明が含まれ、信頼性と解釈性を高める。
- アブレーション研究は、ハイブリッド意味的チャンク化、階層的グラフ構築、およびU-retrieveが性能向上に寄与することを示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。