[論文レビュー] Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusaは LLM の推論を拡張し、複数のデコーディングヘッドを追加して連続する複数のトークンを並列に予測し、ツリーアテンション機構を用いて候補処理を並列化し、2つのファインチューニングモード(Medusa-1 frozen backbone、Medusa-2 joint training)で2.2x〜3.6xの速度向上を達成します。
Large Language Models (LLMs) employ auto-regressive decoding that requires sequential computation, with each step reliant on the previous one's output. This creates a bottleneck as each step necessitates moving the full model parameters from High-Bandwidth Memory (HBM) to the accelerator's cache. While methods such as speculative decoding have been suggested to address this issue, their implementation is impeded by the challenges associated with acquiring and maintaining a separate draft model. In this paper, we present Medusa, an efficient method that augments LLM inference by adding extra decoding heads to predict multiple subsequent tokens in parallel. Using a tree-based attention mechanism, Medusa constructs multiple candidate continuations and verifies them simultaneously in each decoding step. By leveraging parallel processing, Medusa substantially reduces the number of decoding steps required. We present two levels of fine-tuning procedures for Medusa to meet the needs of different use cases: Medusa-1: Medusa is directly fine-tuned on top of a frozen backbone LLM, enabling lossless inference acceleration. Medusa-2: Medusa is fine-tuned together with the backbone LLM, enabling better prediction accuracy of Medusa heads and higher speedup but needing a special training recipe that preserves the backbone model's capabilities. Moreover, we propose several extensions that improve or expand the utility of Medusa, including a self-distillation to handle situations where no training data is available and a typical acceptance scheme to boost the acceptance rate while maintaining generation quality. We evaluate Medusa on models of various sizes and training procedures. Our experiments demonstrate that Medusa-1 can achieve over 2.2x speedup without compromising generation quality, while Medusa-2 further improves the speedup to 2.3-3.6x.
研究の動機と目的
- 大規模言語モデルの推論スループットを、品質を犠牲にせずデコードステップを削減して向上させる。
- バックボーンモデルに追加デコードヘッドを活用することで、ドラフトモデルを別途用意する必要を排除する。
- リソースとデータの利用状況に合わせた柔軟な訓練手順を提供する。
- データが乏しい設定に対処し効率を改善する拡張(典型的適合、自己蒸留など)を提供する。
提案手法
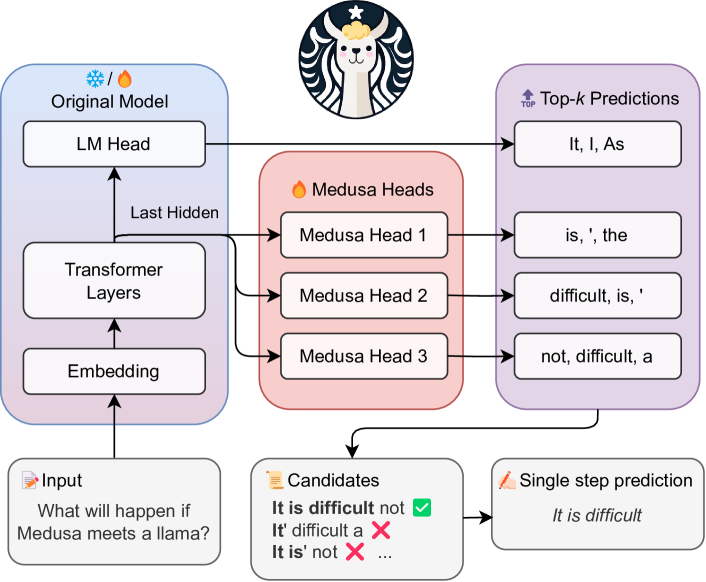
- バックボーンの最終隠れ状態にK個のデコードヘッドを接続して、後続トークンを予測する。
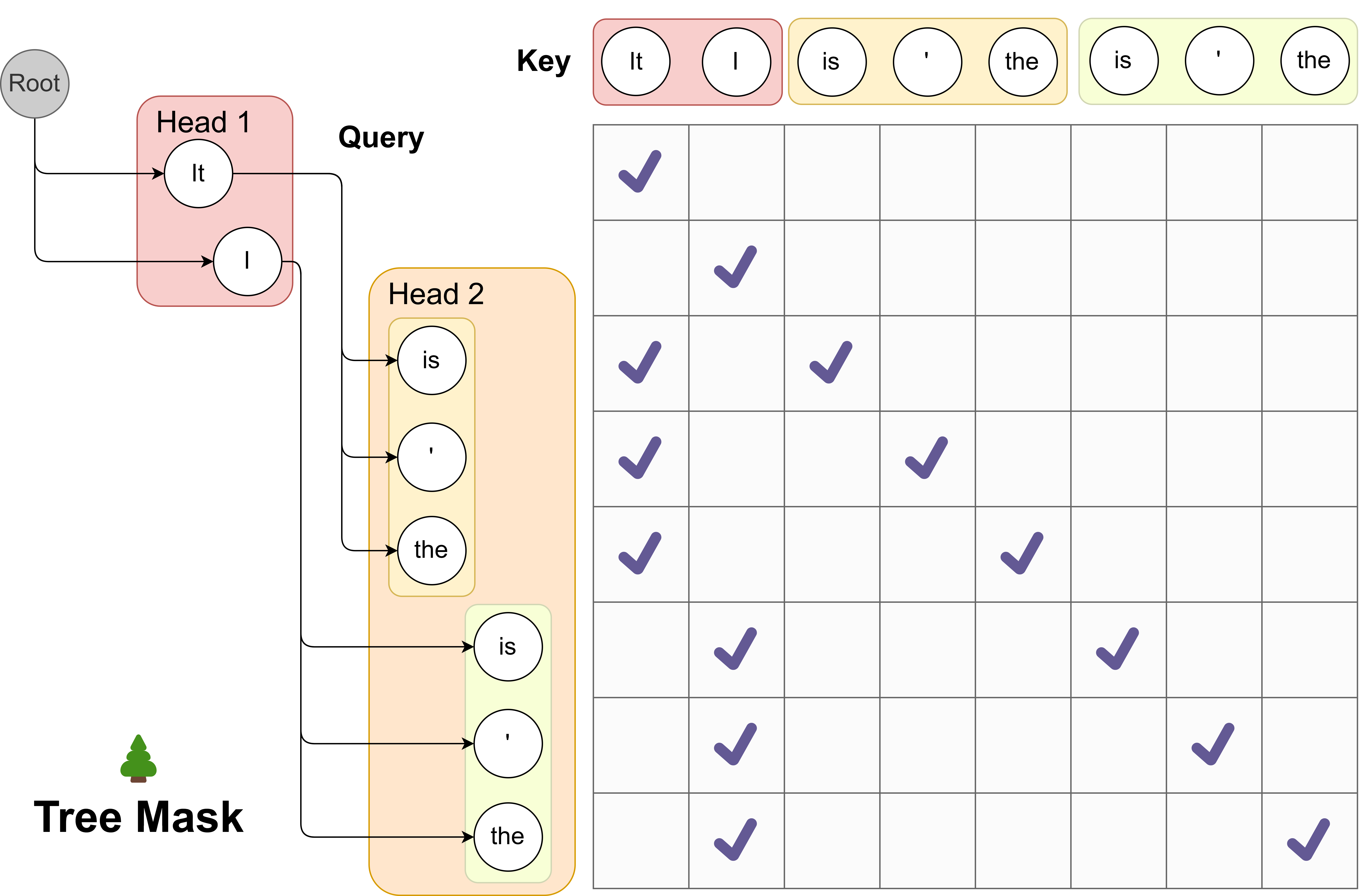
- 木構造のアテンションマスクを使用して、複数の候補継続を並列に処理する。
- 2つの方式でヘッドを微調整する:Medusa-1(凍結バックボーン)またはMedusa-2(バックボーン+ヘッドの共同訓練)。
- 拒絶サンプリングに頼るのではなく、妥当な候補を選択する通常の受け入れ方式を提供する。
- 訓練データが利用できない場合に自己蒸留を提供して訓練データを生成し、木の構築に関するデータ/キャリブレーション手法を検討する。
実験結果
リサーチクエスチョン
- RQ1複数のデコードヘッドは、バックボーンモデルを変更せずに、いくつかの未来トークンを並列に予測することを可能にするのか。
- RQ2推論を加速しつつバックボーンの性能を保持または向上させるための効果的な訓練戦略(Medusa-1対Medusa-2)は何か。
- RQ3提案された通常の受け入れ方式は、生成品質を維持しつつデコード効率を改善できるのか。
- RQ4Medusaヘッドを用いて、モデルサイズと訓練 regime にわたる速度向上はどれくらい達成可能か。
- RQ5自己蒸留や最適化された木の構築といった拡張は、データ不足の条件下でどのように性能に影響するか。
主な発見
- Medusa-1は生成品質を犠牲にすることなく2.2xを超える速度向上を達成する。
- Medusa-2はさらなる速度向上を2.3x〜3.6xに高めることができる。
- このアプローチは、様々なサイズと訓練手順のモデル(例:Vicuna 7B、13B、33B、Zephyr-7B)で機能する。
- 2つの訓練モード(凍結バックボーン vs 共同訓練)は、制限されたハードウェアでの柔軟なデプロイや完全なファインチューニングを可能にする。
- 自己蒸留や通常の受け入れなどの拡張は、データ欠如を扱い効率を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。