[論文レビュー] Mental-LLM: Leveraging Large Language Models for Mental Health Prediction via Online Text Data
本論文は、オンラインテキストデータを用いたメンタルヘルス予測タスクにおいて、ゼロショット、少数ショット、および指示微調整設定にわたる複数の指示調整済みLLMを評価し、指示微調整が性能を大幅に向上させること、Mental-AlpacaとMental-FLAN-T5が最先端に近い能力を達成することを示している。
Advances in large language models (LLMs) have empowered a variety of applications. However, there is still a significant gap in research when it comes to understanding and enhancing the capabilities of LLMs in the field of mental health. In this work, we present a comprehensive evaluation of multiple LLMs on various mental health prediction tasks via online text data, including Alpaca, Alpaca-LoRA, FLAN-T5, GPT-3.5, and GPT-4. We conduct a broad range of experiments, covering zero-shot prompting, few-shot prompting, and instruction fine-tuning. The results indicate a promising yet limited performance of LLMs with zero-shot and few-shot prompt designs for mental health tasks. More importantly, our experiments show that instruction finetuning can significantly boost the performance of LLMs for all tasks simultaneously. Our best-finetuned models, Mental-Alpaca and Mental-FLAN-T5, outperform the best prompt design of GPT-3.5 (25 and 15 times bigger) by 10.9% on balanced accuracy and the best of GPT-4 (250 and 150 times bigger) by 4.8%. They further perform on par with the state-of-the-art task-specific language model. We also conduct an exploratory case study on LLMs' capability on mental health reasoning tasks, illustrating the promising capability of certain models such as GPT-4. We summarize our findings into a set of action guidelines for potential methods to enhance LLMs' capability for mental health tasks. Meanwhile, we also emphasize the important limitations before achieving deployability in real-world mental health settings, such as known racial and gender bias. We highlight the important ethical risks accompanying this line of research.
研究の動機と目的
- オンラインテキストデータを用いたメンタルヘルス課題に対して、ゼロショット、少数ショット、および指示微調整がLLMsにどのような影響を与えるかを評価する。
- 多様なデータセットで、Alpaca、Alpaca-LoRA、FLAN-T5、LLaMA2、GPT-3.5、GPT-4 を含む幅広いLLMを比較する。
- 指示微調整がタスクやデータセット全体で性能向上をもたらすことを示す。
- 今後の研究のためのオープンソースのメンタルヘルス対応モデルとガイドラインを提供する。
提案手法
- 4部構成のゼロショットプロンプトと4つのプロンプト戦略を設計する(Basic、Context Enhancement、Mental Health Enhancement、Context & Mental Health Enhancement)。
- ゼロショットプロンプトにプロンプトとラベルのデモンストレーションのセットを追加して少数ショット promptingを実装する。
- 複数データセットを用いたトレーニングで指示微調整を実行し、異なるメンタルヘルス課題を跨ぐマルチタスク処理を可能にする。
- Redditおよび非Redditデータセット7件から抽出した6つのタスクを、訓練/テスト分割および外部評価で評価する。
- メンタルヘルス予測タスクのために、Mental-AlpacaとMental-FLAN-T5をオープンソースの微調整済みモデルとして開発・公開する。
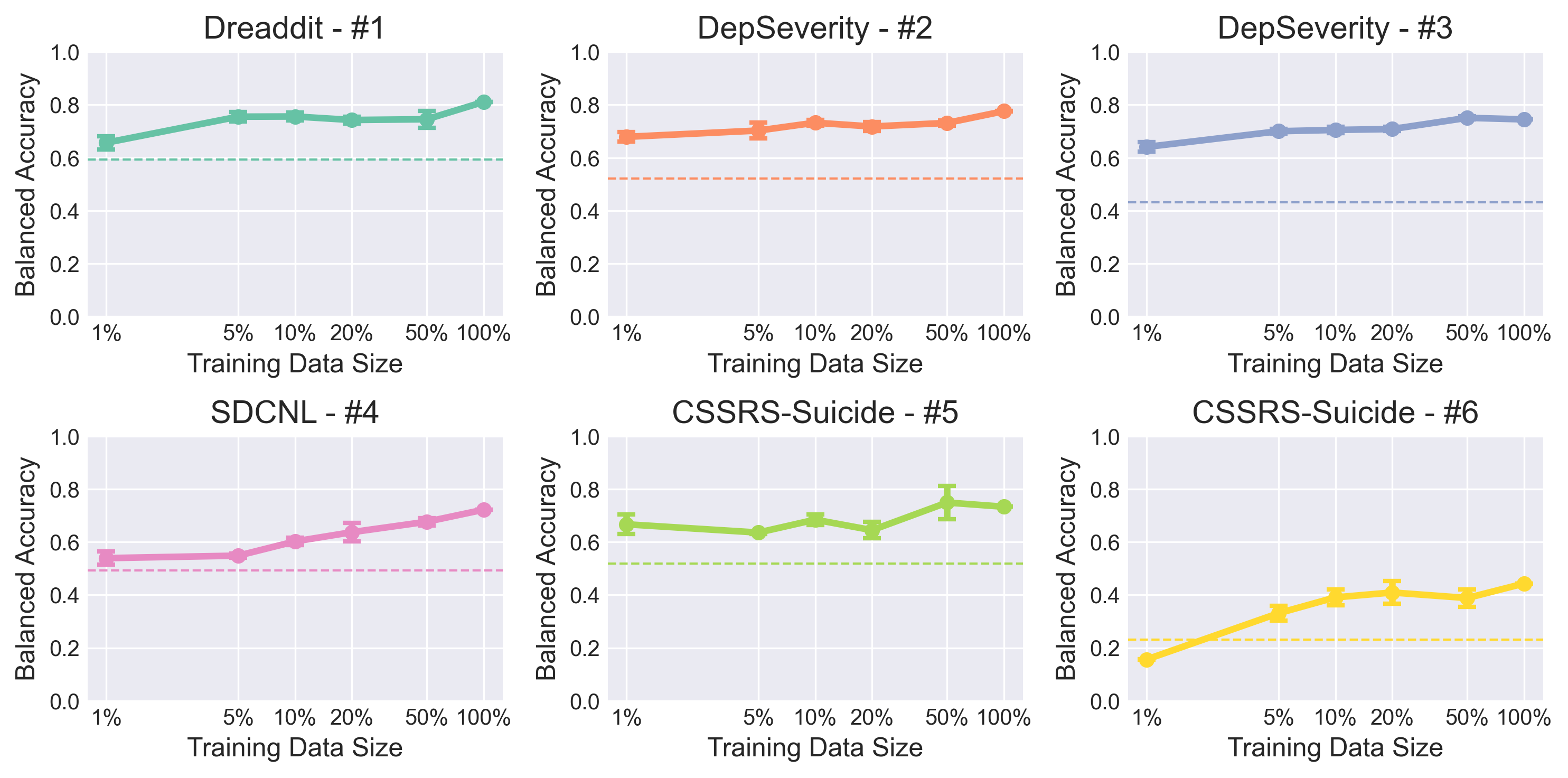
実験結果
リサーチクエスチョン
- RQ1複数のLLMにおけるメンタルヘルス予測タスクで、ゼロショットおよび少数ショット prompting はどう比較されるのか?
- RQ2指示微調整は多様なメンタルヘルス課題とデータセット全体でどの程度性能を向上させることができるのか?
- RQ3微調整済みモデルはメンタルヘルス予測においてタスク特化モデルと同等またはそれを上回ることができるか?
- RQ4LLMをメンタルヘルス分析に展開する際の倫理的配慮とバイアスは何か?
主な発見
- 指示微調整は複数のメンタルヘルス課題とデータセットに跨ってモデルの性能を大幅に向上させる。
- Mental-AlpacaとMental-FLAN-T5は、最良のGPT-3.5プロンプト設計を平均バランス精度で10.9%上回り(サイズははるかに小さいにもかかわらず)、平均で最良のGPT-4プロンプトを4.8%上回る。
- 微調整済みモデルは、いくつかのタスクで最先端のタスク特化モデルMental-RoBERTaと同等の性能に到達する。
- ゼロショットおよび少数ショットプロンプトは有望だが限定的な性能を示し、少数ショットは平均約4.1%の改善をもたらす。
- ケーススタディは、GPT-4などのモデルに微妙な推論能力を示す一方で、今後の研究を要する失敗ケースを浮き彫りにしている。
- メンタルヘルスのマルチタスク予測研究を促進するため、Mental-AlpacaとMental-FLAN-T5のオープンソース公開。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。