[論文レビュー] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
MetaGPTは、SOP駆動の構造化出力と実行可能なフィードバックを使用してマルチエージェントLLM協調を調整するメタプログラミングフレームワークを導入し、ベンチマークにおいて最先端のコード生成と堅牢なソフトウェア開発を達成します。
Remarkable progress has been made on automated problem solving through societies of agents based on large language models (LLMs). Existing LLM-based multi-agent systems can already solve simple dialogue tasks. Solutions to more complex tasks, however, are complicated through logic inconsistencies due to cascading hallucinations caused by naively chaining LLMs. Here we introduce MetaGPT, an innovative meta-programming framework incorporating efficient human workflows into LLM-based multi-agent collaborations. MetaGPT encodes Standardized Operating Procedures (SOPs) into prompt sequences for more streamlined workflows, thus allowing agents with human-like domain expertise to verify intermediate results and reduce errors. MetaGPT utilizes an assembly line paradigm to assign diverse roles to various agents, efficiently breaking down complex tasks into subtasks involving many agents working together. On collaborative software engineering benchmarks, MetaGPT generates more coherent solutions than previous chat-based multi-agent systems. Our project can be found at https://github.com/geekan/MetaGPT
研究の動機と目的
- LLMベースのマルチエージェント問題解決における一貫性と正確性の向上を、標準化された運用手順(SOP)を組み込むことで動機づける。
- 複雑なソフトウェアタスクを役割とワークフローに分解し、エージェント間のカスケード的な幻覚を削減する。
- 構造化された出力(ドキュメント/図)と購読-出版情報フローを実現して、コミュニケーションの効率を向上させる。
- 実行時にデバッグとコード実行を可能にする実行可能なフィードバック機構を導入し、より高品質のコード生成を実現する。
提案手法
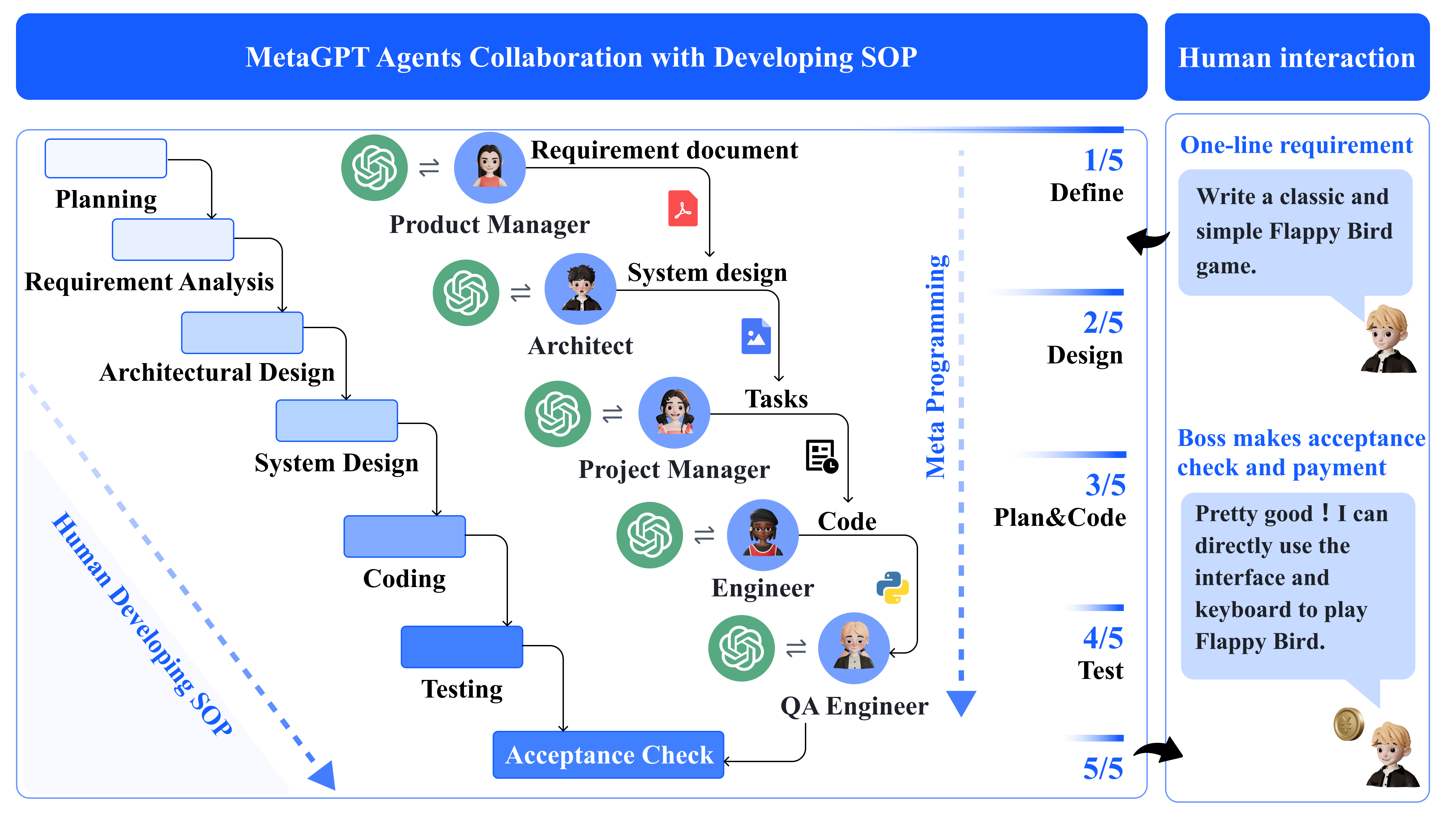
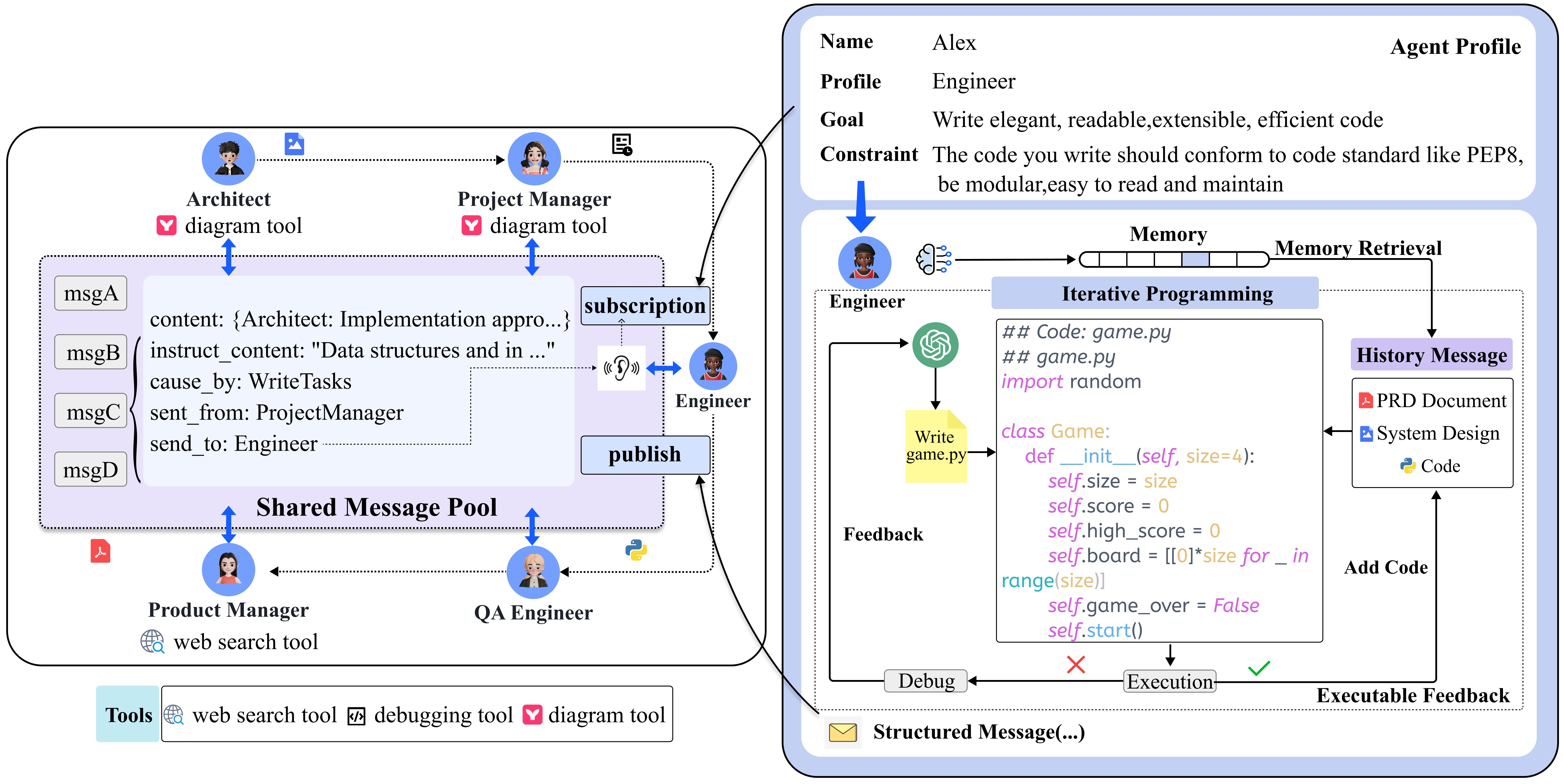
- 5つの専門的なエージェント役割(Product Manager、Architect、Project Manager、Engineer、QA Engineer)を、タスク固有のプロファイルと制約とともに定義する。
- 情報過負荷を減らすための共有メッセージプールと購読機構を備えた、構造化されたドキュメントベースの通信プロトコルを実装する。
- 要件から設計、実装、テストまでを逐次化するSOP駆動のソフトウェア開発ワークフローを採用する。
- Engineerがユニットテストを実行し、制限付きリトライ回数(最大3回まで)でコードを反復的にデバッグする実行可能なフィードバックを導入する。
- Pass@k指標と人間/システムレベルの評価を用いて、AutoGPT、LangChain、AgentVerse、ChatDevと比較し、HumanEval、MBPP、そして新しいSoftwareDevベンチマークで評価する。
実験結果
リサーチクエスチョン
- RQ1SOPと役割の専門化を取り入れることで、マルチエージェントのコード生成における一貫性とエラー率にどのような影響があるか?
- RQ2購読-出版の構造化出力通信プロトコルは、タスクの効率を改善し、LLMベースの協調で幻覚を減らすことができるか?
- RQ3実行時における実行可能なフィードバックは、標準的なベンチマークでコード品質と実行可能性を大幅に改善するか?
- RQ4MetaGPTは既存のマルチエージェントフレームワークや汎用LLMと比較して標準的なコード生成ベンチマークでどのように性能を示すか?
主な発見
- MetaGPTはHumanEvalとMBPPでPass@1の最先端スコアを達成し、それぞれ85.9%と87.7%に達した。
- MetaGPTは実験でタスク完了率100%を達成した。
- SoftwareDevベンチマークでは、MetaGPTはほとんどの指標でChatDevを上回り、実行可能性スコアが3.75、実行時間が短い(503s)。
- MetaGPTは総トークン数がより多い(24,613または31,255)一方、人間の修正コストを低く抑え(0.83)、SOPを構造化して実行可能性を高めている。
- 実行可能なフィードバックにより、HumanEvalとMBPPでそれぞれPass@1が絶対値で4.2%と5.4%の改善を得られた。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。