[論文レビュー] MGTBench: Benchmarking Machine-Generated Text Detection
MGTBench は、強力な LLM に対して機械生成テキスト検出手法を評価するためのモジュラーなベンチマークフレームワークを提案し、指標ベースとモデルベースのアプローチを比較し、転移性・頑健性・テキスト属性付与を評価します。
Nowadays, powerful large language models (LLMs) such as ChatGPT have demonstrated revolutionary power in a variety of tasks. Consequently, the detection of machine-generated texts (MGTs) is becoming increasingly crucial as LLMs become more advanced and prevalent. These models have the ability to generate human-like language, making it challenging to discern whether a text is authored by a human or a machine. This raises concerns regarding authenticity, accountability, and potential bias. However, existing methods for detecting MGTs are evaluated using different model architectures, datasets, and experimental settings, resulting in a lack of a comprehensive evaluation framework that encompasses various methodologies. Furthermore, it remains unclear how existing detection methods would perform against powerful LLMs. In this paper, we fill this gap by proposing the first benchmark framework for MGT detection against powerful LLMs, named MGTBench. Extensive evaluations on public datasets with curated texts generated by various powerful LLMs such as ChatGPT-turbo and Claude demonstrate the effectiveness of different detection methods. Our ablation study shows that a larger number of words in general leads to better performance and most detection methods can achieve similar performance with much fewer training samples. Moreover, we delve into a more challenging task: text attribution. Our findings indicate that the model-based detection methods still perform well in the text attribution task. To investigate the robustness of different detection methods, we consider three adversarial attacks, namely paraphrasing, random spacing, and adversarial perturbations. We discover that these attacks can significantly diminish detection effectiveness, underscoring the critical need for the development of more robust detection methods.
研究の動機と目的
- 強力な LLM に対する MGT 検出および属性付与のための、総合的でモジュラーなベンチマークフレームワークを作成する。
- 複数のデータセットと LLM に対して、広範な指標ベースおよびモデルベースの検出手法を評価する。
- データセット間およびLLM間の転移性、敵対的摂動下での頑健性、および実用的な検出効率を分析する。
- テキスト長と学習データサイズが検出性能に与える影響について洞察を提供する。
提案手法
- 入力、検出、評価モジュールを備えたモジュラー設計。
- 十の検出手法(八つの指標ベース、五つのモデルベース統合が利用可能)。
- 人手で書かれたテキストから MGT を生成するために、Public LLM(例:ChatGPT-turbo、Claude、ChatGLM、Dolly、GPT4All、StableLM)を使用する。
- サンプルレベルのログを伴う、Accuracy、Precision、Recall、F1 スコア、AUC などの評価指標。
- テキスト長、トレーニングセットサイズ、データセット間およびLLM間の転移、敵対的攻撃に対する頑健性の分析。
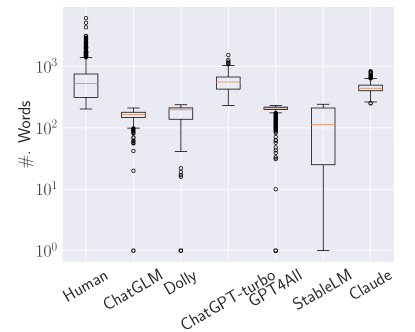
実験結果
リサーチクエスチョン
- RQ1指標ベースとモデルベースの MGT 検出手法は、さまざまなデータセットや LLM でどのように性能を発揮するか?
- RQ2あるデータセットやある LLM で訓練され、別のデータセットや別の LLM でテストされた場合の検出手法の転移性特性は何か?
- RQ3言い換え、ランダムな間隔、敵対的摂動などの攻撃に対して検出手法はどの程度頑健か?
- RQ4テキストの長さは検出性能にどう影響し、信頼性の高い検出にはどれくらいの訓練サンプルが必要か?
- RQ5検出手法をテキスト属性付与、すなわちテキストの発信モデルを識別することに拡張できるか?
主な発見
- LM Detector は、データセットと LLM の全般にわたって最良の検出性能を一般に示す。たとえば、タスク全体で高い F1 スコアを達成しており(例:Essay vs ChatGPT-turbo で 0.993)。
- 指標ベースの手法(例:Log-Likelihood、Log-Rank、GLTR、LRR)は堅実な性能を提供し、しばしばいくつかのモデルベースの手法よりも LLM 間の転移性が高い。
- 長いテキストは一般に検出性能を向上させ、200語程度でほぼ最適な結果が得られることが多い。
- テキスト属性付与タスクでは、モデルベースの検出器が指標ベースの手法よりも強い性能を示す。
- すべての手法は、言い換え、間隔の変更、摂動攻撃に対して大きな脆弱性を示し、より頑健なアプローチの必要性を強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。