[論文レビュー] MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
MindEye2は複数の被験者に跨る単一モデルを事前学習し、held-out-subjectのfMRIデータのわずか1時間で微調整することで、共有-subject潜在空間と微調整済みの unCLIP/SDXL パイプラインを用いて、最先端の fMRIから画像への再構成と検索を実現する。
Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
研究の動機と目的
- 実務的な fMRI-to-image 再構成を最小限の被験者固有データで動機づける。
- 多様な脳を共通の潜在空間へマッピングする共有サブジェクト機能的アライメントを開発する。
- fMRIをCLIP空間へマッピングし、fine-tuned unCLIP/SDXLモデルで画像を再構成する統一パイプラインを統合する。
- 高忠実度の再構成と並行して強力な検索・キャプション生成能力を示す。
提案手法
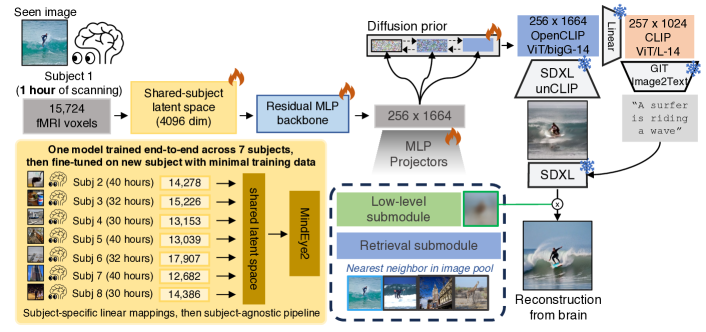
- 7人の被験者からのfMRIデータで単一モデルを事前学習し、その後、held-out 8th被験者で微調整する。
- voxel応答を4096-dの共有サブジェクト潜在空間へマッピングする線形リッジマッピングを用い、残差MLPバックボーンをOpenCLIP ViT-bigG/14 embeddingsへ適用する。
- diffusion priorsを訓練してfMRI潜在表現をOpenCLIP画像空間へマッピングし、検索サブモジュールを対比学習で訓練する。
- 低レベルのサブモジュールを導入して細かな構造を保持し、SDXL再構築を支援する。
- Stable Diffusion XL unCLIPを、テキストの代わりに画像埋め込みを受け付けるよう微調整し、キャプションガイダンスを用いてベースSDXLで出力を洗練させる。
実験結果
リサーチクエスチョン
- RQ1共有サブジェクト潜在空間は、新しい被験者の非常に限られたデータでも高品質な fMRI-to-image 再構成を可能にするか。
- RQ2マルチサブジェクト事前学習は、スクラッチから学習した単一被験者モデルと比較して held-out 被験者への一般化を改善するか。
- RQ3アライメント、拡散 priors、サブモジュールは再構成と検索性能にどのように寄与するか。
- RQ4画像キャプション生成を補助ガイダンスとして含めた場合、再構成にどのような影響があるか。
- RQ5洗練された再構成は未洗練のものと比べて人間の評価で優れているか、客観指標との整合性はどうか。
主な発見
- 7名の被験者を跨る事前学習と新規被験者データ1時間での微調整は、再構成と検索指標で最先端を達成する。
- 4096-d潜在空間への共有サブジェクト線形アライメントと統一パイプラインは、データが限られている場合の一般化を改善する。
- CLIP画像埋め込みを受け付けるようにSDXL unCLIPを微調整することで、真の画像とほぼ一致する高忠実度の再構成を実現する。
- 予測された画像キャプションは最終的な洗練フェーズで有用な条件付けガイドとなり、意味的忠実度を向上させる。
- 洗練された再構成は人間の評価者に未洗練の結果より好評である一方で、一部の指標は未洗練の出力を Favorする。
- MindEye2は1時間のデータで、特定の指標で約40倍のデータを用いて学習した単一被験者モデルと同等の性能を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。