[論文レビュー] Mine yOur owN Anatomy: Revisiting Medical Image Segmentation with Extremely Limited Labels
MONA は、極めて限られたラベルの下で多様でありながら一貫した解剖学的特徴を学習する半教師ありの2D医用画像分割フレームワークであり、複数のベンチマークで最先端の結果を達成します。
Recent studies on contrastive learning have achieved remarkable performance solely by leveraging few labels in the context of medical image segmentation. Existing methods mainly focus on instance discrimination and invariant mapping. However, they face three common pitfalls: (1) tailness: medical image data usually follows an implicit long-tail class distribution. Blindly leveraging all pixels in training hence can lead to the data imbalance issues, and cause deteriorated performance; (2) consistency: it remains unclear whether a segmentation model has learned meaningful and yet consistent anatomical features due to the intra-class variations between different anatomical features; and (3) diversity: the intra-slice correlations within the entire dataset have received significantly less attention. This motivates us to seek a principled approach for strategically making use of the dataset itself to discover similar yet distinct samples from different anatomical views. In this paper, we introduce a novel semi-supervised 2D medical image segmentation framework termed Mine yOur owN Anatomy (MONA), and make three contributions. First, prior work argues that every pixel equally matters to the model training; we observe empirically that this alone is unlikely to define meaningful anatomical features, mainly due to lacking the supervision signal. We show two simple solutions towards learning invariances - through the use of stronger data augmentations and nearest neighbors. Second, we construct a set of objectives that encourage the model to be capable of decomposing medical images into a collection of anatomical features in an unsupervised manner. Lastly, we both empirically and theoretically, demonstrate the efficacy of our MONA on three benchmark datasets with different labeled settings, achieving new state-of-the-art under different labeled semi-supervised settings.
研究の動機と目的
- 非常に少ないラベルと豊富な未ラベルデータを伴う医用画像分割の課題に対処する。
- 長尾クラス分布の下で、コントラスト学習が意味のある一貫した解剖学的特徴を学習できるか検証する。
- 尾部対応のサンプリング、解剖学的一貫性、ビューの多様性を促進して分割を改善するフレームワークを開発する。
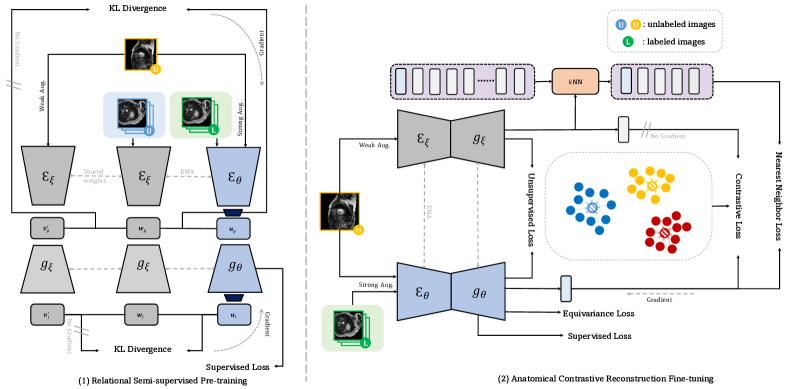
提案手法
- リレーショナル半教師付き事前学習と解剖学的コントラスト再構成微調整の2段階で MONA を導入する。
- 長尾クラス分布(tailness)を扱うためにピクセルレベルのアンカーとクラス平均ポジティブをメモリーバンクとともに使用する。
- 画像変換に対する頑健性を強制する等価性(一貫性)損失を組み込む。
- 出力空間で最近傍損失を採用して、過度なメモリ使用なしに意味的多様性を促進する。
- 事前学習中にグローバル/ローカルのインスタンス識別と疑似ラベルおよび教師付き分割損失を組み合わせる。
- ラベル効率と他のCLフレームワークとの補完性を示す理論的・実証的分析を提供する。

実験結果
リサーチクエスチョン
- RQ1極めて限定的なラベルの下で、コントラスト学習を医用画像分割に効果的に適用できるか。
- RQ2ピクセルレベルの解剖学認識フレームワークで、長尾クラス分布、クラス内変動、およびクラス間多様性をどのように対処できるか。
- RQ3尾部性、一貫性、多様性はデータセットとラベル regime にわたって分割性能を共同で向上させるか。
主な発見
| Dataset | Labeled_Ratio | Method | DSC(%) | ASD(mm) |
|---|---|---|---|---|
| ACDC | 1% | MONA | 82.6 | 2.03 |
| ACDC | 5% | MONA | 88.8 | 0.622 |
| ACDC | 10% | MONA | 90.7 | 0.864 |
| LiTS | 1% | MONA | 64.1 | 20.9 |
| LiTS | 5% | MONA | 67.3 | 16.4 |
| LiTS | 10% | MONA | 69.3 | 18.0 |
- MONA は ACDC、LiTS、MMWHS のベンチマークで、1%、5%、10% のラベル regime において最先端の SSL 手法を上回る。
- ACDC の 1% ラベルで、MONA は 82.6% DSC と 2.03 mm ASD を達成し、従来法より著しく改善。
- LiTS の 1% ラベルで、MONA は 64.1% DSC と 20.9 mm ASD を達成し、他のラベル比率でも優位性を維持。
- MONA は定性的な可視化で一貫してより鋭い解剖境界と境界適合をもたらす。
- アブレーション研究は、尾部性、一貫性、多様性を組み合わせると最高の性能を発揮し、データ拡張戦略が頑健性をさらに高めることを示す。
- 著者らは、ラベル効率の良い学習における MONA の有効性に対する理論的正当化を提供し、複数のコントラスト学習フレームワークとの適合性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。