[論文レビュー] MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
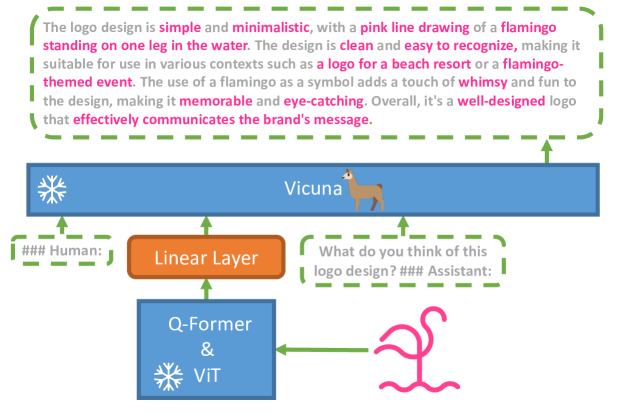
MiniGPT-4 は、凍結された視覚エンコーダを凍結された高度な LLM(Vicuna)と、単一の射影層を介して整合させることにより、2 段階の訓練と高品質データのキュレーションを通じて、GPT-4 相当の視覚と言語の能力を実現します。
The recent GPT-4 has demonstrated extraordinary multi-modal abilities, such as directly generating websites from handwritten text and identifying humorous elements within images. These features are rarely observed in previous vision-language models. However, the technical details behind GPT-4 continue to remain undisclosed. We believe that the enhanced multi-modal generation capabilities of GPT-4 stem from the utilization of sophisticated large language models (LLM). To examine this phenomenon, we present MiniGPT-4, which aligns a frozen visual encoder with a frozen advanced LLM, Vicuna, using one projection layer. Our work, for the first time, uncovers that properly aligning the visual features with an advanced large language model can possess numerous advanced multi-modal abilities demonstrated by GPT-4, such as detailed image description generation and website creation from hand-drawn drafts. Furthermore, we also observe other emerging capabilities in MiniGPT-4, including writing stories and poems inspired by given images, teaching users how to cook based on food photos, and so on. In our experiment, we found that the model trained on short image caption pairs could produce unnatural language outputs (e.g., repetition and fragmentation). To address this problem, we curate a detailed image description dataset in the second stage to finetune the model, which consequently improves the model's generation reliability and overall usability. Our code, pre-trained model, and collected dataset are available at https://minigpt-4.github.io/.
研究の動機と目的
- 視覚特徴を高度な LLM に整合させることが、GPT-4 レベルの視覚と言語機能を実現するかを調査する。
- 単一の射影層を訓練するだけで、視覚と言語モデルを効果的に融合できることを示す。
- 高品質な画像説明を対象とした第2 段階のファインチューニングが生成の信頼性と実用性を向上させる。
提案手法
- 凍結された BLIP-2 スタイルの視覚エンコーダ(ViT-G/14 with Q-Former)と凍結された Vicuna LLM を言語デコーダとして使用する。
- 視覚特徴を Vicuna の埋め込みと整合させるための単一の線形射影層を追加する。
- 2 段階の訓練:(i)凍結コンポーネントを用いた大規模な画像とキャプションの組で事前訓練;(ii)設計された対話テンプレートを用いた高品質な画像説明データセットでファインチューニング。
- モデルを Vicuna 風の対話形式で指示して詳細な画像説明を生成し、品質管理のために ChatGPT で後処理する。
- 高度な視覚と言語タスクと COCO キャプション評価で、定性的なデモと定量的なベンチマークで評価する。
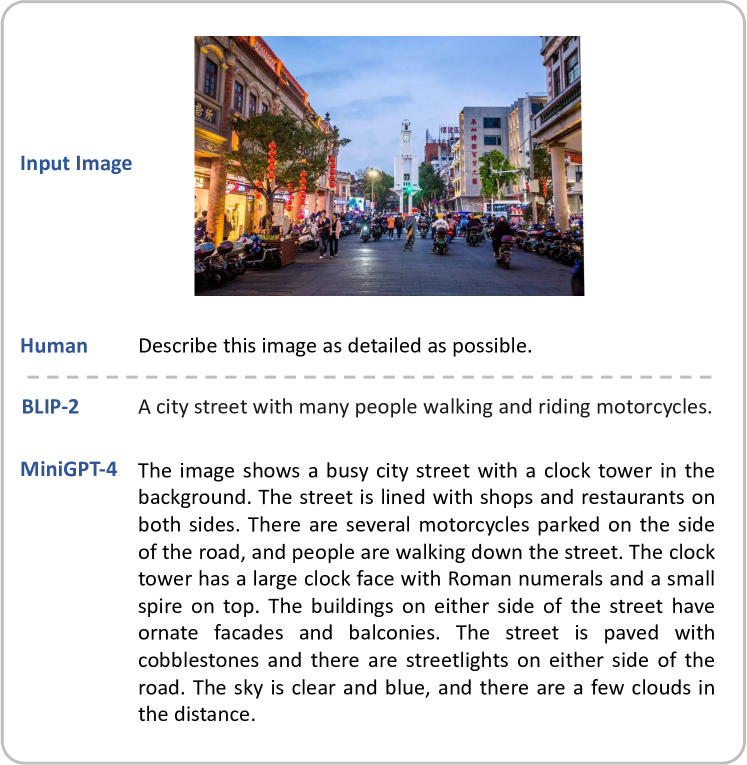
実験結果
リサーチクエスチョン
- RQ1視覚特徴を高度な LLM に整合させることは、全体のアーキテクチャを更新せずに GPT-4 相当の視覚と言語機能を実現できるか。
- RQ2限られたデータの下で、単一の射影層は視覚と言語モデルを効果的に整合させるのに十分か。
- RQ3第2 段階の詳細な画像説明によるファインチューニングは生成の信頼性と実用性を改善するか。
- RQ4MiniGPT-4 はベースラインの視覚と言語モデルと比較して、どんな新たな能力を示すか。
主な発見
- MiniGPT-4 は、詳細な画像説明、ミームの解釈、手書き原稿からのウェブサイト作成などの高度な能力を実現する。
- 凍結された視覚エンコーダを Vicuna に整合させるのに単一の線形射影層が十分であり、約 10 時間の 4 A100 GPU での訓練で GPT-4 相当の能力を達成する。
- 第2 段階の、厳選された高品質な画像説明データセットを用いたファインチューニングは、生成エラー(詳細なキャプションや詩など)を大きく減少させ、言語の自然さを向上させる。
- 高度なタスクでは、ミニGPT-4 は Meme、レシピ、広告、詩におけるユーザー評価ベースの応答で BLIP-2 を著しく上回る(彼らの定性的テストで約 65% の総合成功)。
- COCO キャプション付けでは、ChatGPT を用いた評価で、BLIP-2 の 27.5% に対し MiniGPT-4 は 66.2% の正解率を達成し、グラウンドトゥルースのカバレッジ判定を改善。
- アブレーションとアーキテクチャの変 variations は、Q-Former を削除することや層を追加することが、限定データ下で単一射影設計を超える改善にはつながらないことを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。