[論文レビュー] MIS-FM: 3D Medical Image Segmentation using Foundation Models Pretrained on a Large-Scale Unannotated Dataset
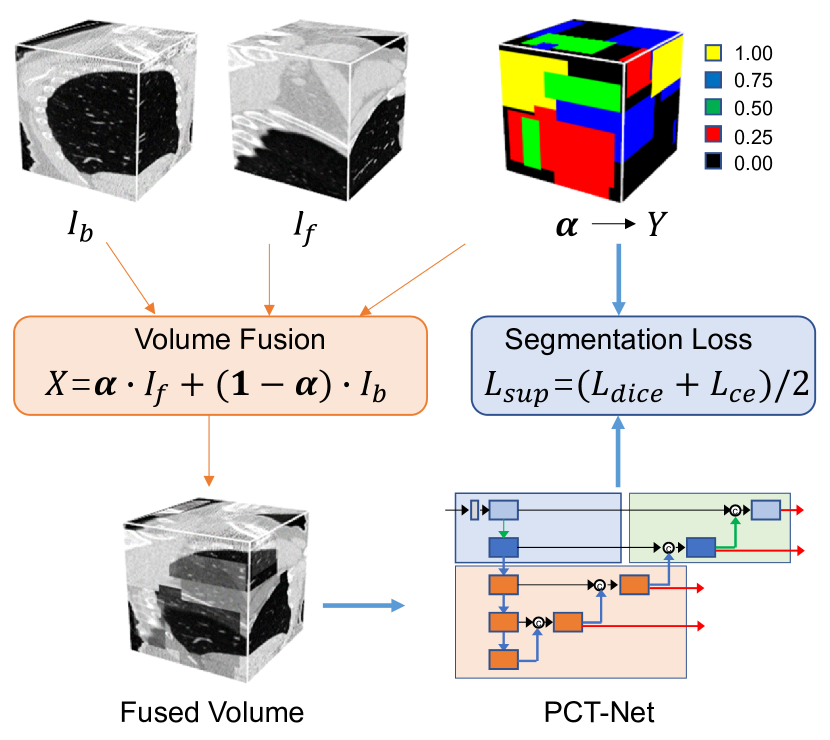
MIS-FMはVolume Fusionを導入し、注釈なしデータを用いて完全な分割モデルを事前学習する3D医用画像分割の自己教師付き事前学習戦略で、下流タスクへの効果的な転移のためのParallel Convolution and Transformer Network(PCT-Net)を提案します。
Pretraining with large-scale 3D volumes has a potential for improving the segmentation performance on a target medical image dataset where the training images and annotations are limited. Due to the high cost of acquiring pixel-level segmentation annotations on the large-scale pretraining dataset, pretraining with unannotated images is highly desirable. In this work, we propose a novel self-supervised learning strategy named Volume Fusion (VF) for pretraining 3D segmentation models. It fuses several random patches from a foreground sub-volume to a background sub-volume based on a predefined set of discrete fusion coefficients, and forces the model to predict the fusion coefficient of each voxel, which is formulated as a self-supervised segmentation task without manual annotations. Additionally, we propose a novel network architecture based on parallel convolution and transformer blocks that is suitable to be transferred to different downstream segmentation tasks with various scales of organs and lesions. The proposed model was pretrained with 110k unannotated 3D CT volumes, and experiments with different downstream segmentation targets including head and neck organs, thoracic/abdominal organs showed that our pretrained model largely outperformed training from scratch and several state-of-the-art self-supervised training methods and segmentation models. The code and pretrained model are available at https://github.com/openmedlab/MIS-FM.
研究の動機と目的
- 大規模な未注釈3D医用画像で分割モデルの事前学習を行い、注釈データが限られている場合の性能を向上させることを動機付ける。
- 手動注釈なしでペア入力と分割ラベルを生む自己教師付き疑似分割前処理タスクとしてVolume Fusionを提案する。
- マルチスケール分割タスクへ効率的に転移するためのParallel ConvolutionとTransformerブロックを組み合わせたPCT-Netを導入する。
- 大規模な事前学習を通じてHead-and-Neck、Thoracic、腹部の臓器分割にわたり有効性を示す。
- 110kのCTスキャンで事前学習モデルを公開し、より広範な臨床への転移性を可能にする。
提案手法
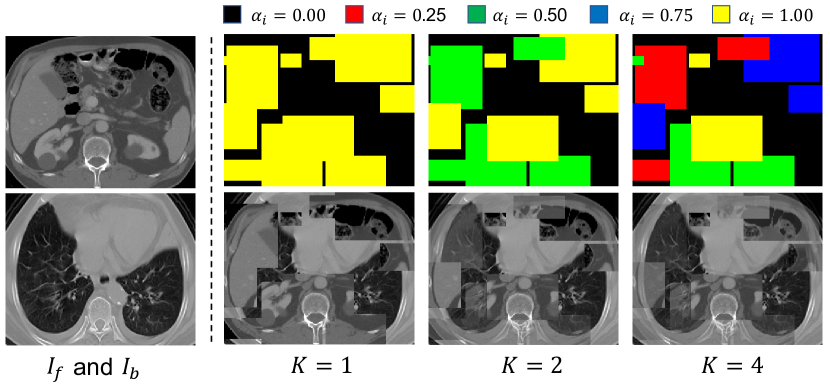
- Volume Fusion(VF):あるスキャンの前景サブボリュームと別のスキャンの背景サブボリュームを離散融合係数マップで融合し、ボクセル単位の融合カテゴリを分割前処理タスクに変換する。
- 融合係数alpha_iは離散集合{0, 1/K, ..., 1}から取り、ボクセルにはC = K+1クラスを作成する;モデルはalpha_iに対応するボクセルクラスYを予測する。
- 事前学習目的L_supはディス Dice損失とクロスエントロピー損失を組み合わせ、疑似分割タスク上で全分割モデルをエンドツーエンドで訓練する。
- PCT-Net:ローカルCNN特徴と長距離のTransformerベースの文脈を二重ブランチのPCTブロックで融合する3レベルのピラミッド型アーキテクチャ(ローカルConvブランチとグローバル自己注意ブランチ)を有する。
- 埋め込みモジュールは高解像度では2D畳み込みを、低解像度では3D畳み込みを用い、異方性の3DCTデータに対処する;予測は複数スケールでディープ監督付きで生成される。
- 訓練設定は110kの注釈なしCT体積(PData-110k)を事前学習に使用し、下流分割データセットで標準的なDiceとASSD指標を用いてファインチューニングする。
実験結果
リサーチクエスチョン
- RQ1Volume Fusionの事前学習は、スクラッチからの訓練や他のSSL手法と比較して下流の3D CTタスクの分割性能を改善するか?
- RQ2融合パラメータKはVF事前学習の転移性能と文脈学習にどのように影響するか?
- RQ3事前学習データ規模(1k、10k、110k体積)が下流の分割性能に与える影響はどの程度か?
- RQ4PCT-Netは異なるスケール(頭頸部、胸部、腹部)の臓器間でVF事前学習特徴を効率的に活用できるか?
主な発見
- VF事前学習は、胸部臓器のSegTHORでスクラッチおよび他のSSL手法より一貫して優れており、Diceは88.30%、ASSDは1.78 mmで達成している。
- MICCAI 2015 Head-Neckデータでは、VFを用いたPCT-Netは平均Diceが82.74、ASSDが0.77 mmと、nnU-Net、TransUNet、UNETR++などのベースラインより高い。
- K=4のVFが最良のトレードオフを生み、最低のASSD(1.78 mm)と競争力のDiceを達成したが、大きなK値が必ずしも性能向上に繋がるわけではない。
- 事前学習データ規模を増やす(1k→10k→110k)と、3D U-NetとPCT-Netの下流Diceは一般に改善され、PCT-Netアーキテクチャでより大きな利得が観察された。
- Patch Swapping、Model Genesis、MIMと比較して、VFはSegTHORで最高の平均Dice(88.30%)と最も低いASSD(1.78 mm)を達成した。
- VF+PCT-Netは、VF単独またはベースラインアーキテクチャより下流成績を改善し、転移と文脈学習が有益であることを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。