[論文レビュー] Mistral 7B
Mistral 7B は 7B の言語モデルで、grouped-query attention および sliding window attention を搭載し、複数のベンチマークで open/open-weights ベースラインを上回り、instruct-finetuned バリアントを含む。
We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
研究の動機と目的
- 小型で効率的に設計された 7B モデルが広範なベンチマークで大規模なオープンモデルを上回ることを実証する。
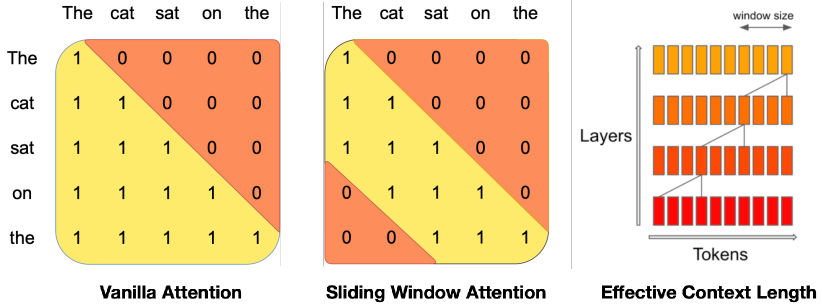
- アーキテクチャ的革新(grouped-query attention と sliding window attention)を導入し、推論速度と長いシーケンスの処理を改善する。
- インストラクション調整済みバリアントを提供し、より大規模なチャットモデルに対する競争力を示す。
- 実用的なデプロイツールと現実世界でのガードレール・コンテンツモデレーション機能を紹介する。
提案手法
- 推論を加速しデコード時のメモリを削減するために grouped-query attention (GQA) を採用する。
- 有効なコンテキスト長を低コストで拡張するために sliding window attention (SWA) を用いる。
- デコード時のメモリ使用量を制限するローリングバッファキャッシュを実装する。
- 生成中の注意とキャッシュを管理するために長いプロンプトを事前充填・分割する。
- instruction データセットでモデルのバージョンをファインチューニングして Mistral 7B – Instruct を作成する。
- 参照実装と vLLM、Skypilot、Hugging Face との統合を公開する。
実験結果
リサーチクエスチョン
- RQ1推論、数学、コード生成を含む多様なベンチマークで、7B モデルがより大きなオープンモデル(7B/13B/34B)を打ち負かせるか?
- RQ2アーキテクチャ革新(GQA + SWA)は性能を犠牲にせず実用的な速度向上とメモリ節約を提供するか?
- RQ3チャット風ベンチマークにおけるベースの 7B モデルと instruction ファインチューニング版の性能格差はどれくらいか?
- RQ4軽量モデルとデプロイした場合のガードレールおよびコンテンツモデレーション機能はどのように機能するか?
- RQ5Mistral 7B はチャットおよび指示追従設定で既存のオープンモデルとどう比較されるか?
主な発見
| モデル | モダリティ | MMLU | Hellaswag | WinoG | PIQA | Arc-e | Arc-c | NQ | TriviaQA | HumanEval | MBPP | MATH | GSM8K |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA 2 7B | Pretrained | 44.4% | 77.1% | 69.5% | 77.9% | 68.7% | 43.2% | 24.7% | 63.8% | 11.6% | 26.1% | 3.9% | 16.0% |
| LLaMA 2 13B | Pretrained | 55.6% | 80.7% | 72.9% | 80.8% | 75.2% | 48.8% | 29.0% | 69.6% | 18.9% | 35.4% | 6.0% | 34.3% |
| Code-Llama 7B | Finetuned | 36.9% | 62.9% | 62.3% | 72.8% | 59.4% | 34.5% | 11.0% | 34.9% | 31.1% | 52.5% | 5.2% | 20.8% |
| Mistral 7B | Pretrained | 60.1% | 81.3% | 75.3% | 83.0% | 80.0% | 55.5% | 28.8% | 69.9% | 30.5% | 47.5% | 13.1% | 52.2% |
- Mistral 7B はすべての評価ベンチマークで Llama 2 13B を上回る。
- 数学とコード生成ベンチマークでも Llama 1 34B を上回る。
- Mistral 7B – Instruct のチャットモデルは Llama 2 13B – Chat を上回り、13B チャットの性能に近づく。
- 効率的なアテンション機構(GQA と SWA)は推論を速くし、長い有効コンテキストを低メモリで実現する。
- ガードレールとシステムプロンプトは出力を誘導でき、システムプロンプトは安全性を向上させつつ有用性を維持する。
- Self-reflection コンテンツモデレーションは高い精度(99.4%)と堅牢なリコール(95.6%)を実現する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。