[論文レビュー] Mixed Precision Quantization of ConvNets via Differentiable Neural Architecture Search
この論文は混合精度量子化をニューラルアーキテクチャ探索問題として定式化し、層ごとにビット幅を割り当てる微分可能ニューラルアーキテクチャ探索(DNAS)を導入し、ResNetモデルで精度を維持しつつ大幅な圧縮を実現します。従来のNASより著しく高速で、さまざまなハードウェアコスト指標に適用可能です。
Recent work in network quantization has substantially reduced the time and space complexity of neural network inference, enabling their deployment on embedded and mobile devices with limited computational and memory resources. However, existing quantization methods often represent all weights and activations with the same precision (bit-width). In this paper, we explore a new dimension of the design space: quantizing different layers with different bit-widths. We formulate this problem as a neural architecture search problem and propose a novel differentiable neural architecture search (DNAS) framework to efficiently explore its exponential search space with gradient-based optimization. Experiments show we surpass the state-of-the-art compression of ResNet on CIFAR-10 and ImageNet. Our quantized models with 21.1x smaller model size or 103.9x lower computational cost can still outperform baseline quantized or even full precision models.
研究の動機と目的
- 推論コストとメモリフットプリントを低減する動機づけとして、 uniform quantization ではなく層ごとに異なるビット幅を許容する。
- 層ごとの精度を探索する効率的な NAS ベースのフレームワーク(DNAS)を提案する。
- 混合精度量子化が最先端の圧縮を上回りつつ、精度を維持または向上させられることを示す。
- DNAS アプローチが ResNet のような大規模ネットワーク(ImageNet の場合)に対して高速で拡張性があることを示す。
提案手法
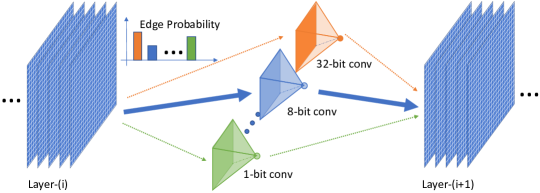
- アーキテクチャ空間を、エッジが異なる量子化ビット幅を持つ畳み込み演算子で構成される確率的スーパーネットとして表現する。
- アーキテクチャパラメータで離散的なエッジ選択を緩和し、Gumbel SoftMax を用いて微分可能な勾配ベースの最適化を可能にする。
- 重みとアーキテクチャパラメータを SGD で同時に訓練し、学習した分布から候補アーキテクチャをサンプリングする。
- Accuracy (cross-entropy) とモデルサイズまたは計算コストを、設定可能な Cost(a) 関数を介してバランスさせるコスト認識型目的関数を定義する。
- DNAS フレームワークを CIFAR-10 および ImageNet の ResNet に適用し、層ごとの精度割り当てを見つける。
- DoReFa-Net および PACT に従って重みと活性化を量子化し、ブロックレベルの混合精度探索と温度退火付き Gumbel サンプリングを行う。

実験結果
リサーチクエスチョン
- RQ1微分可能 NAS で最適化された混合精度量子化は、精度と圧縮の点で一様精度量子化を上回ることができるか?
- RQ2計算コストを過度にかけずに、層間の指数関数的なビット幅構成をどのように効率的に探索できるか?
- RQ3ImageNet での ResNet のような大規模アーキテクチャにおける層ごとのビット幅選択が、モデルサイズと FLOP削減へ与える影響は何か?
- RQ4実世界のモデル圧縮タスクに実用的な速さをDNAS フレームワークは確保できるか?
主な発見
- 量子化されたモデルは最大で 21.1x のモデルサイズ削減または 103.9x の計算コスト削減を達成し、場合によっては基準となる量子化モデルやフル精度モデルを上回る。
- CIFAR-10 では、混合精度の ResNet バリアントが最大で 0.37% の精度向上を実現しつつ 11.6–16.6x の圧縮; いくつかの構成は 16.6–20.3x の圧縮で 0.39% 未満の精度低下を達成。
- ImageNet で、ResNet-18/34 の最良アーキテクチャは約 10.6–11.2x のモデルサイズ削減(MA)で 0.18–0.49% の精度向上を達成するか、競争力のある精度で 19.0–21.1x の削減に到達する(ME)。
- Compared to TTQ and ADMM baselines, DNAS architectures maintain higher accuracy at similar or greater compression levels for both model size and computational cost experiments.
- The DNAS pipeline completes a search on ResNet-18 for ImageNet in under 5 hours on 8 V100 GPUs, demonstrating practical efficiency over prior NAS approaches.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。