[論文レビュー] Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
TabSyn は学習済み潜在空間(VAE with Transformers and adaptive loss を介して)に拡散モデルを適用して混合タイプの表データを合成し、従来法よりサンプリングが速くデータ品質が高い。
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces Tabsyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed Tabsyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that Tabsyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
研究の動機と目的
- 複雑な列間関係を持つ混合タイプ表データの生成モデルを改善する動機付け。
- 数値特徴とカテゴリ特徴を共同でモデル化できる統一潜在空間を開発する。
- 既存の拡散ベースの表データ手法と比較してサンプル品質と生成速度を向上させる。
- 低次・高次統計量および下流タスクを含む複数のデータセットと評価指標における頑健性を示す。
提案手法
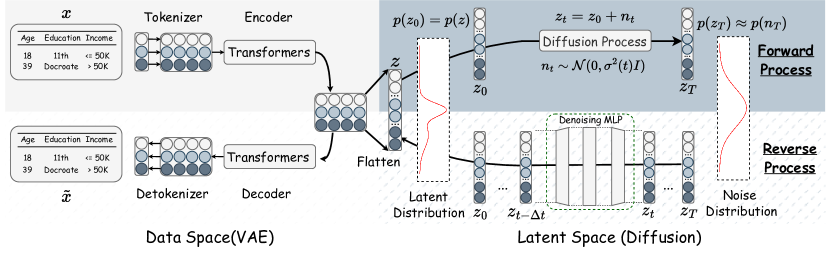
- 列ごとのトークン化と Transformer エンコーダを介して生データを連続埋め込み空間に変換する。
- 適応的な損失重み付けを備えた変分オートエンコーダを用いて情報量の多い滑らかな潜在埋め込みを学習する。
- 線形ノイズスケジュール(sigma(t)=t)を用いた去噪スコアマッチングにより潜在空間でスコアベース拡散モデルを訓練する。
- 潜在表現から元の列値を再構成するデトークナイザを適用してデータ生成を行う。
- 線形ノイズスケジュールが逆過程の誤差を低減しサンプリングを加速するという理論的根拠と実証的証拠を提供する(20NFEs未満)。
- 列ごとの密度、ペアワイズ相関、MLE、および欠損値補完タスクを用いて、6つの混合タイプデータセットで TabSyn を7つのベースラインと比較評価する。
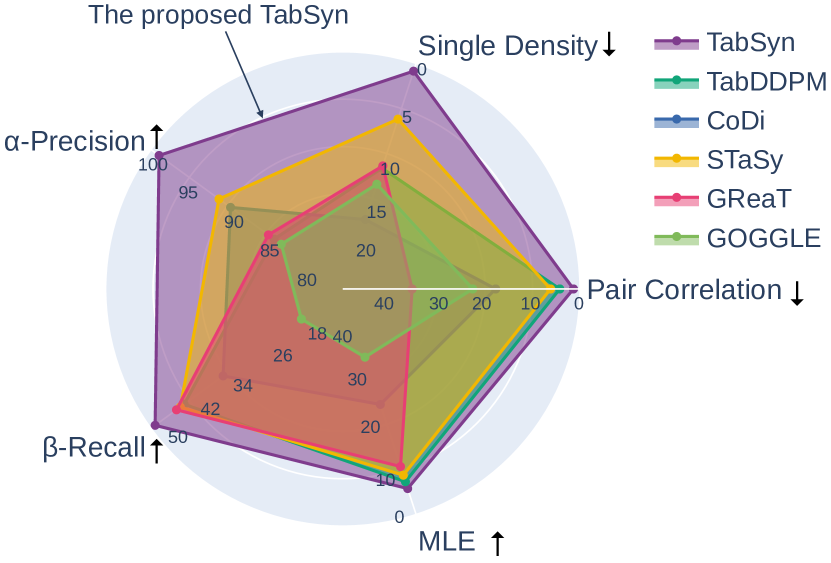
実験結果
リサーチクエスチョン
- RQ1混合タイプの表データから学習された潜在空間で拡散モデルは効果的に作動できるか。
- RQ2列対応トークナイザと Transformer ベースの VAE は既存手法より列間の関係をよりよく保持するか。
- RQ3線形ノイズスケジュールは高速で高品質な拡散ベースの表データ合成を実現するか。
- RQ4TabSyn は低次(密度、相関)および高次(精度/再現率)指標と下流タスクでどのように性能を示すか。
- RQ5適応的な beta-VAE トレーニングは潜在空間の正則化と再構成品質に有益か。
主な発見
- TabSyn は列ごとの密度推定と列間相関において一貫してベースライン法を上回り、誤差をそれぞれ平均86.0%、67.6%削減する。
- TabSyn は6つのデータセットにおいて機械学習効率(分類/回帰)と欠損値補完性能において優れた成果を達成する。
- 線形拡散ノイズスケジュール(sigma(t)=t)は20ステップ未満の逆ステップで高品質なサンプルを生成することを可能にし、サンプリングを加速する。
- 潜在空間拡散(TabSyn-DDPM)は一般にデータ空間での拡散より優れており、表データの潜在埋め込みを学ぶ利点を浮き彫りにする。
- 予定された beta-VAE は潜在空間を過度に正則化することなく再構成を改善し、下流の合成データ品質を高める。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。