[論文レビュー] MixFormerV2: Efficient Fully Transformer Tracking
MixFormerV2は、予測トークンを用い、蒸留を基盤としたモデル削減を取り入れた完全なトランスフォーマー追跡フレームワークを導入し、GPUおよびCPU上でリアルタイム速度と高い精度を実現します。
Transformer-based trackers have achieved strong accuracy on the standard benchmarks. However, their efficiency remains an obstacle to practical deployment on both GPU and CPU platforms. In this paper, to overcome this issue, we propose a fully transformer tracking framework, coined as \emph{MixFormerV2}, without any dense convolutional operation and complex score prediction module. Our key design is to introduce four special prediction tokens and concatenate them with the tokens from target template and search areas. Then, we apply the unified transformer backbone on these mixed token sequence. These prediction tokens are able to capture the complex correlation between target template and search area via mixed attentions. Based on them, we can easily predict the tracking box and estimate its confidence score through simple MLP heads. To further improve the efficiency of MixFormerV2, we present a new distillation-based model reduction paradigm, including dense-to-sparse distillation and deep-to-shallow distillation. The former one aims to transfer knowledge from the dense-head based MixViT to our fully transformer tracker, while the latter one is used to prune some layers of the backbone. We instantiate two types of MixForemrV2, where the MixFormerV2-B achieves an AUC of 70.6\% on LaSOT and an AUC of 57.4\% on TNL2k with a high GPU speed of 165 FPS, and the MixFormerV2-S surpasses FEAR-L by 2.7\% AUC on LaSOT with a real-time CPU speed.
研究の動機と目的
- 実時間デプロイに適したトランスフォーマーベース手法を用いた効率的な視覚オブジェクト追跡の動機付け。
- 密集畳み込みや複雑なスコアヘッドを用いない完全なトランスフォーマー追跡フレームワークを提案。
- 対象テンプレートと探索領域の相関を捉える予測トークンを導入。
- 効率を高めるための蒸留ベースのモデル削減(密集→疎、深層→浅層)を開発。
- 標準追跡ベンチマークで強力な精度と速度のトレードオフを実証。
提案手法
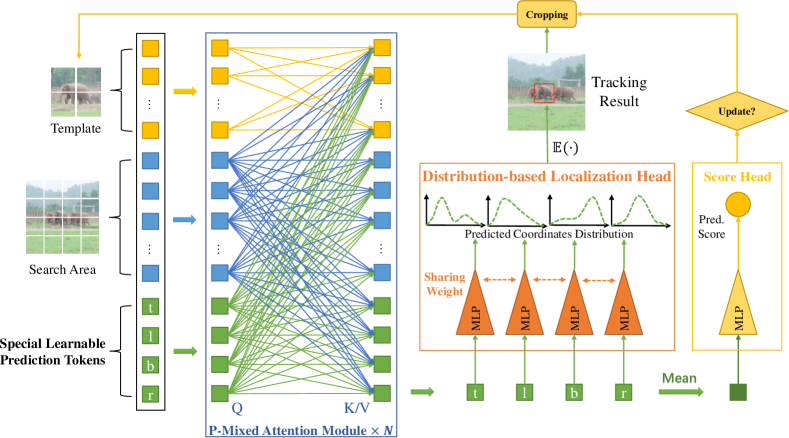
- テンプレートトークンと探索トークンを結合して混合トークン列を形成するよう、4つの学習可能な予測トークンを使用。
- 対象-探索の相関をエンコードするために、予測トークンを含む混合アテンション(P-MAM)を適用。
- 予測トークン上の共通MLPヘッドを介して4つのボックス座標を直接回帰する(分布ベースの回帰)。
- 予測トークンを平均化して簡単なMLPヘッドでターゲット品質スコアを予測。
- MixViTのdense-headからMixFormerV2への密集→疎の蒸留を実施し、局在化知識を伝達。
- 進行的な深さプルーニングと中間教師を用いた深さ→浅さの蒸留を適用し、転送性を維持しつつバックボーンを剪定。
- CPU/GPU待機時間を削減するMLP次元削減(MLP-r)を含む。
- ボックス回帰、CIoU、ロジット蒸留、特徴模倣を組み合わせた蒸留損失で訓練。
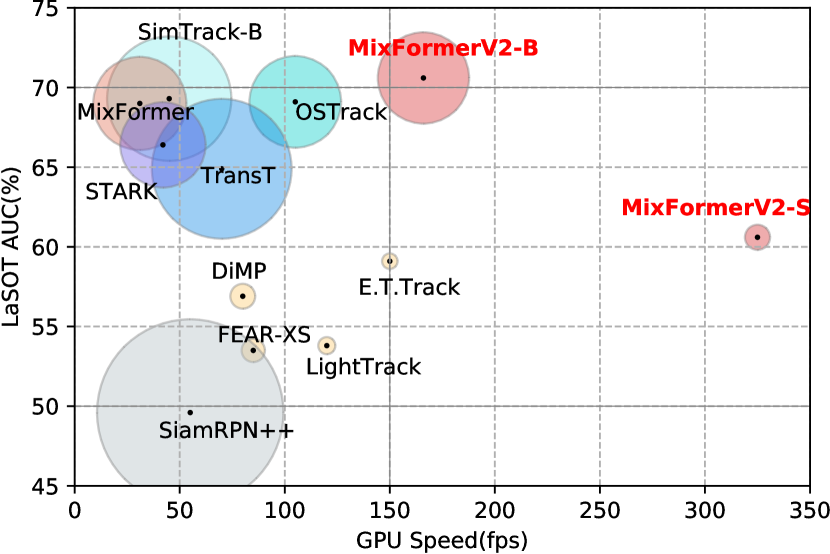
実験結果
リサーチクエスチョン
- RQ1dense畳み込みを用いない完全なトランスフォーマー追跡モデルは、競争力のある精度とより高い効率を達成できるか。
- RQ2予測トークンとトークンベースの回帰は局所化精度と推論速度にどう影響するか。
- RQ3知識蒸留(密集→疎および深さ→浅さ)は、軽量なMixFormerV2の性能を向上させるか。
- RQ4中間教師とMLP削減がCPUリアルタイム性能に与える影響は何か。
主な発見
- MixFormerV2-BはLaSOTで70.6%のAUCをGPUで165 FPSで達成。
- MixFormerV2-SはLaSOTの競争力ある性能を維持しつつCPUリアルタイム速度を達成。
- 四つのトークンを用いた予測トークンベースの分布回帰は、直接の単一トークン回帰を上回り、密集コーナーヘッドと同等またはそれ以上の速度と精度のトレードオフを達成。
- MixViTからのDense-to-Sparse蒸留は、教師によって1.4–2.2%のAUC向上をもたらす。
- 進行的な深さプルーニングを伴うDeep-to-Shallow蒸留は、バックボーンの深さを削減しつつほとんどの精度を維持(例:12層→8層→4層のワークフロー)。
- 中間教師は非常に浅いモデル(例:4層)の蒸留を助け、追加の利得を提供。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。