[論文レビュー] MixSpeech: Cross-Modality Self-Learning with Audio-Visual Stream Mixup for Visual Speech Translation and Recognition
MixSpeechを提案する。混合音声視覚(mixed audio-visual speech)を用いたマルチモーダル自己学習フレームワークで、視覚的スピーチ翻訳とリップリーディングを正則化し、AVMuST-TEDおよびLRS/LRS2/CMLRデータセットで最先端の結果を達成する。
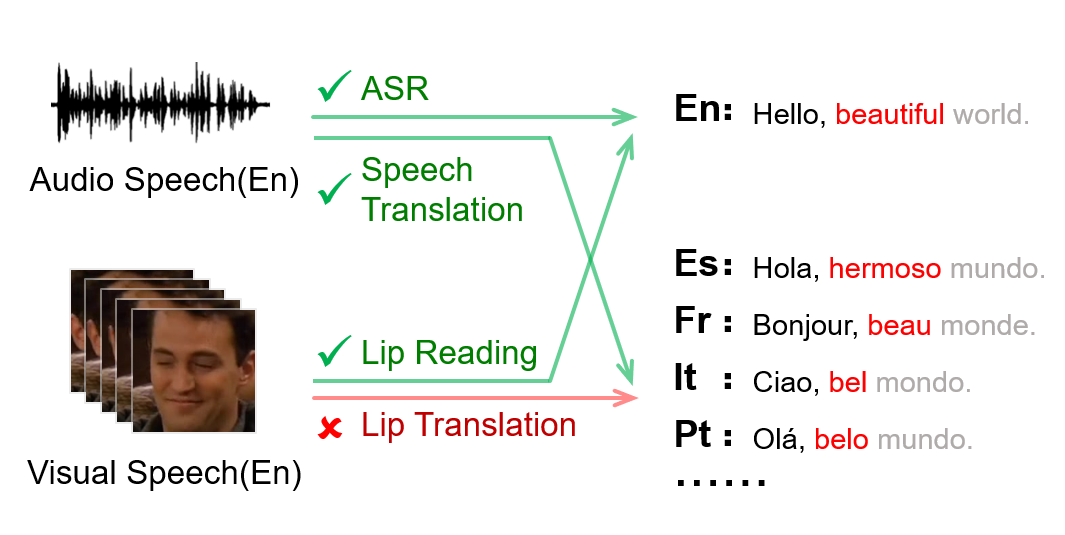
Multi-media communications facilitate global interaction among people. However, despite researchers exploring cross-lingual translation techniques such as machine translation and audio speech translation to overcome language barriers, there is still a shortage of cross-lingual studies on visual speech. This lack of research is mainly due to the absence of datasets containing visual speech and translated text pairs. In this paper, we present extbf{AVMuST-TED}, the first dataset for extbf{A}udio- extbf{V}isual extbf{Mu}ltilingual extbf{S}peech extbf{T}ranslation, derived from extbf{TED} talks. Nonetheless, visual speech is not as distinguishable as audio speech, making it difficult to develop a mapping from source speech phonemes to the target language text. To address this issue, we propose MixSpeech, a cross-modality self-learning framework that utilizes audio speech to regularize the training of visual speech tasks. To further minimize the cross-modality gap and its impact on knowledge transfer, we suggest adopting mixed speech, which is created by interpolating audio and visual streams, along with a curriculum learning strategy to adjust the mixing ratio as needed. MixSpeech enhances speech translation in noisy environments, improving BLEU scores for four languages on AVMuST-TED by +1.4 to +4.2. Moreover, it achieves state-of-the-art performance in lip reading on CMLR (11.1\%), LRS2 (25.5\%), and LRS3 (28.0\%).
研究の動機と目的
- 視覚スピーチ翻訳の言語横断研究を、翻訳付きの視覚スピーチが不足しているため動機づける。
- 四言語に対する最初の音声-視覚マルチリンガル視覚スピーチ翻訳データセット『AVMuST-TED』を導入する。
- 高い識別力を持つ音声スピーチを用いて視覚スピーチ翻訳を正則化するクロスモダリティ自己学習フレームワークを開発する。
- 混合スピーチを用いてモダリティ間のギャップを埋め、ノイズ環境での知識転移と頑健性を向上させる。
- 複数データセットにおける最先端のリップ翻訳とリップリーディングを示す。
- クロスリンガル視覚スピーチ翻訳と潜在的な応用への洞察を提供する。
提案手法
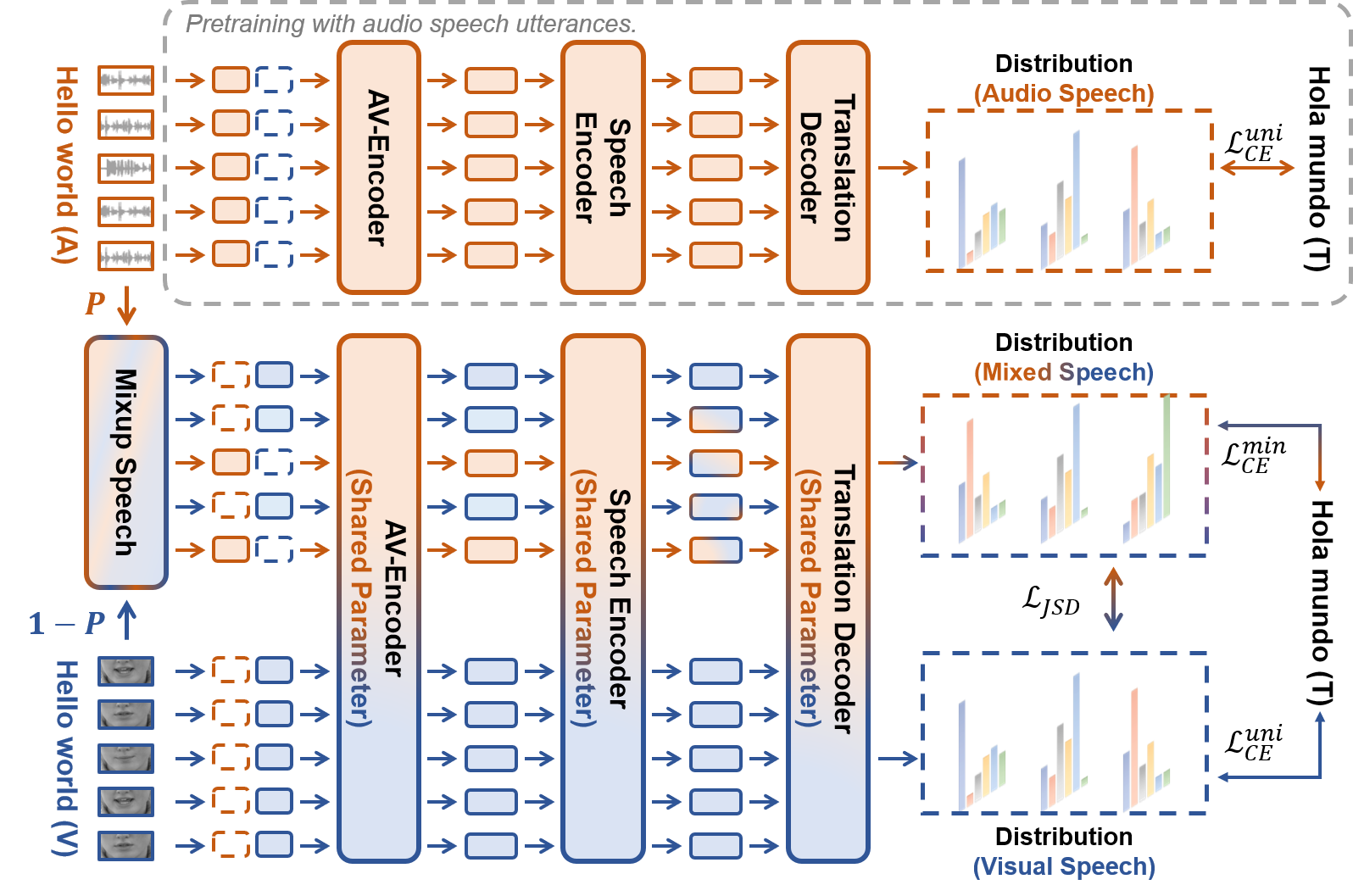
- 高識別音声スピーチで翻訳デコーダを事前訓練し、出発音からターゲット言語テキストへの言語間マッピングを学習する。
- 視覚スピーチを音声スピーチと整合させ、クロスモダリティ自己学習を通じて音声由来のマッピングを視覚スピーチへ転移する。
- フレームレベルで音声と視覚スピーチを内挿してモダリティ間ギャップを埋める混合スピーチを合成する(MixSpeech)。
- 予測不確実性に基づいて訓練中の混合比をカリキュラム学習で適応させる。
- Jensen-Shannonダイバージェンスを用いて視覚・混合スピーチ翻訳の出力分布を整合させつつ、混合目的関数損失で音声-視覚知識を維持する。
実験結果
リサーチクエスチョン
- RQ1音声スピーチの事前訓練は視覚スピーチ翻訳を改善し、クロスモダリティ転送ギャップを縮小できるか。
- RQ2音声と視覚ストリームを混合する混合スピーチはモダリティギャップをさらに減らし、視覚スピーチ翻訳の性能を向上させるか。
- RQ3カリキュラムベースの混合戦略は訓練中のクロスモダリティ知識転送を適応的に最適化できるか。
- RQ4MixSpeechはAVMuST-TEDのリップ翻訳と標準リップリーディング指標(LRS2、LRS3、CMLR)で、資源条件の変動下でどのように性能を示すか。
主な発見
| Method | BLEU En-Es | BLEU En-Fr | BLEU En-It | BLEU En-Pt |
|---|---|---|---|---|
| Cascaded V | 12.7 | 11.3 | 11.5 | 13.2 |
| AV-Hubert V | 14.2 | 12.6 | 12.9 | 14.8 |
| Cascaded A(+Noise) | 16.0 | 12.9 | 12.6 | 15.5 |
| AV-Hubert A(+Noise) | 17.6 | 14.5 | 14.1 | 17.1 |
| MixSpeech(V) | 18.5 | 15.1 | 14.3 | 17.2 |
- MixSpeechはAVMuST-TEDにおいて基準モデルと比較して4言語でBLEUを+1.4〜+4.2改善した。
- End-to-end MixSpeechはAVMuST-TEDで最先端のリップ翻訳、LRS2で25.5%、LRS3で28.0%、CMLRで11.1%のリップリーディングを達成。
- 混合スピーチを用いることでモダリティギャップを埋め、混合比の適切な設定時に顕著な利得を得られる(例:En-Es)。
- カリキュラム学習ベースの混合比は訓練中に適応的に変化し、翻訳性能をさらに向上させる。
- ノイズのある音声条件下でもMixSpeechは頑健性を維持し、音声オンリーベースラインを上回る視覚スピーチ翻訳を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。