[論文レビュー] Mixtral of Experts
Mixtral 8x7B は、各層に 8 個のエキスパートを持ち、トークンごとに 2 個を選択する sparse mixture-of-experts 言語モデルで、47B のスパースパラメータと 13B のアクティブパラメータを持ち、Llama 2 70B と GPT-3.5 を多くのベンチマークで上回り、命令調整型の変種がいくつかのチャットモデルを上回る。
We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. We also provide a model fine-tuned to follow instructions, Mixtral 8x7B - Instruct, that surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B - chat model on human benchmarks. Both the base and instruct models are released under the Apache 2.0 license.
研究の動機と目的
- オープンで高性能なオープンウェイト SMoE 言語モデルの開発を動機づける。
- Mixtral 8x7B をオープンで多言語対応の長文脈デコーダー専用 SMoE として、効率的な推論を備えた提案。
- 1トークンあたりの計算が小さく保たれることを示す(K=2、アクティブパラメータ = 13B)一方で全体のパラメータ数は大きい(47B)。
- Mixtral が数学、コード、 multilingual tasks(多言語タスク)、および指示追従シナリオで最先端または競争力のある結果を達成することを示す。
提案手法
- Mixtral 8x7B アーキテクチャを説明する:32 層、MoE 層あたり 8 エキスパート、各トークンにつきルーターによって 2 つのエキスパートを選択。
- ゲーティングを説明する:K=2 の Softmax(TopK(x · W_g)) を用いて各トークンのエキスパートを選択。
- FFN ブロックを MoE ブロックに置換;エキスパート関数として SwiGLU を使用。
- コンテキスト長を 32768 トークンに拡張;Apache 2.0 の下でオープンソースの重み。
- 多言語データとコンテキストウィンドウを用いた訓練の詳細、さらに Mixtral 8x7B – Instruct の命令調整型バリアント。
- 展開上の考慮事項を概説:Megablocks カーネル、vLLM との統合、EP ロードバランシングの検討事項。

実験結果
リサーチクエスチョン
- RQ1Mixtral 8x7B は、標準ベンチマーク全般で、より大きな密形式モデル(例:Llama 2 70B)と競合・優位な性能を発揮できるか?
- RQ2固定の1トークンあたりアクティブパラメータ予算を使用した場合の、スパースMixture-of-Experts の効率性とスケーラビリティの利点は何か?
- RQ3命令調整(Mixtral Instruct)は、オープンウェイトのライバルと比較してヒトによる評価性能を上回るか?
- RQ4長文脈タスクおよび多言語ベンチマークでの Mixtral の性能はどうか?
- RQ5比較可能なオープンモデルと比較して Mixtral はどのようなバイアスと安全性の特性を示すか?
主な発見
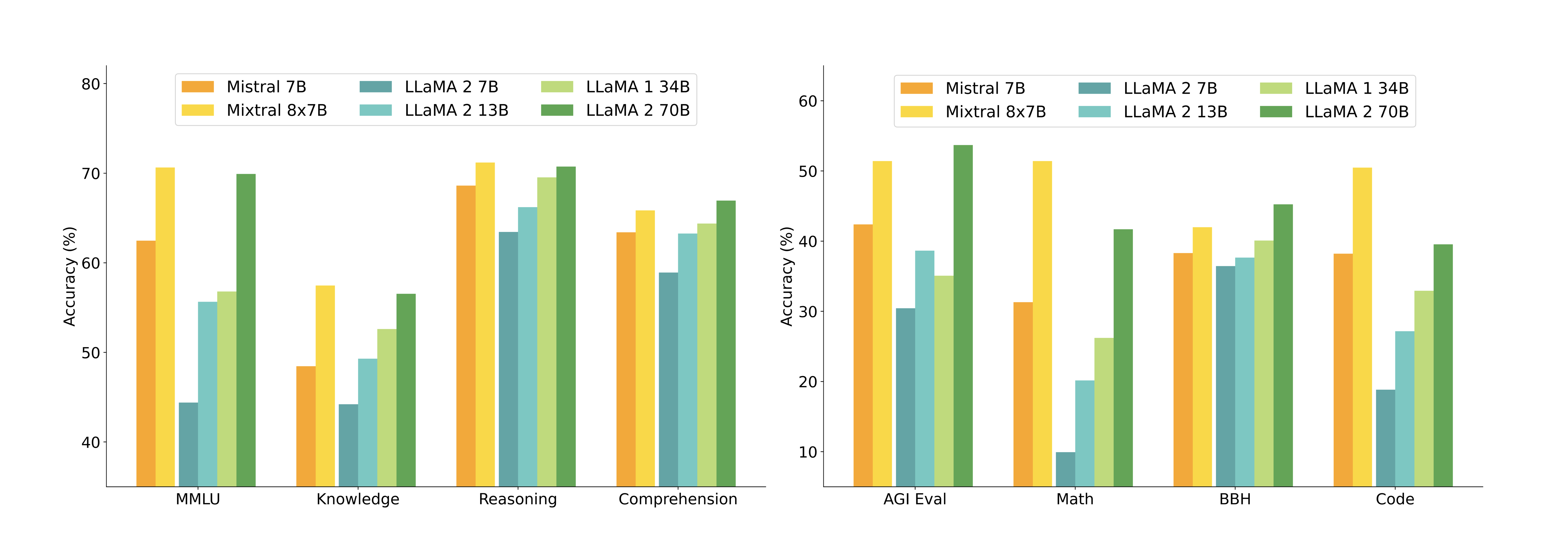
| モデル | アクティブパラメータ | MMLU | HellaS | WinoG | PIQA | Arc-e | Arc-c | NQ | TriQA | HumanE | MBPP | Math | GSM8K |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA 2 7B | 7B | 44.4% | 77.1% | 69.5% | 77.9% | 68.7% | 43.2% | 17.5% | 56.6% | 11.6% | 26.1% | 3.9% | 16.0% |
| LLaMA 2 13B | 13B | 55.6% | 80.7% | 72.9% | 80.8% | 75.2% | 48.8% | 16.7% | 64.0% | 18.9% | 35.4% | 6.0% | 34.3% |
| LLaMA 1 33B | 33B | 56.8% | 83.7% | 76.2% | 82.2% | 79.6% | 54.4% | 24.1% | 68.5% | 25.0% | 40.9% | 8.4% | 44.1% |
| LLaMA 2 70B | 70B | 69.9% | 85.4% | 80.4% | 82.6% | 79.9% | 56.5% | 25.4% | 73.0% | 29.3% | 49.8% | 13.8% | 69.6% |
| Mistral 7B | 7B | 62.5% | 81.0% | 74.2% | 82.2% | 80.5% | 54.9% | 23.2% | 62.5% | 26.2% | 50.2% | 12.7% | 50.0% |
| Mixtral 8x7B | 13B | 70.6% | 84.4% | 77.2% | 83.6% | 83.1% | 59.7% | 30.6% | 71.5% | 40.2% | 60.7% | 28.4% | 74.4% |
- Mixtral 8x7B はほとんどのベンチマークで Llama 2 70B を上回るか同等、特に数学とコード生成で。
- 1トークンあたりのアクティブパラメータは 13B、総スパースパラメータ数は 47B。
- Mixtral–Instruct はヒトベンチマークで GPT-3.5 Turbo、Claude-2.1、Gemini Pro、Llama 2 70B–chat を上回る。
- フランス語、ドイツ語、スペイン語、イタリア語で Llama 2 70B より顕著な多言語の利得。
- 長文脈テストではコンテキスト長を超えて 100% のパスキー取得精度を示し、長いコンテキストでパープレキシティが改善。
- BBQ/BOLD ベンチマークで、Llama 2 70B と比較してバイアスの低減とより前向きな感情表現を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。