[論文レビュー] Mixture-of-Agents Enhances Large Language Model Capabilities
本論文はMixture-of-Agents (MoA) フレームワークを紹介します。層状に配置された複数のLLMを用いて協調的に応答を生成・洗練させ、オープンソースモデルを用いてAlpacaEval 2.0、MT-Bench、FLASKで最先端の結果を達成します。
Recent advances in large language models (LLMs) demonstrate substantial capabilities in natural language understanding and generation tasks. With the growing number of LLMs, how to harness the collective expertise of multiple LLMs is an exciting open direction. Toward this goal, we propose a new approach that leverages the collective strengths of multiple LLMs through a Mixture-of-Agents (MoA) methodology. In our approach, we construct a layered MoA architecture wherein each layer comprises multiple LLM agents. Each agent takes all the outputs from agents in the previous layer as auxiliary information in generating its response. MoA models achieves state-of-art performance on AlpacaEval 2.0, MT-Bench and FLASK, surpassing GPT-4 Omni. For example, our MoA using only open-source LLMs is the leader of AlpacaEval 2.0 by a substantial gap, achieving a score of 65.1% compared to 57.5% by GPT-4 Omni.
研究の動機と目的
- 複数の LLM の協調が、単一モデル生成を超える応答品質の向上につながることを示す。
- 他のモデルの出力から恩恵を受ける協調現象を特徴づける。
- ファインチューニングせずに prompting ベースの MoA フレームワークを開発し、独自モデルと競合できるようにする。
- 標準ベンチマーク(AlpacaEval 2.0、MT-Bench、FLASK)で MoA を評価し、コストとスケーラビリティを分析する。
提案手法
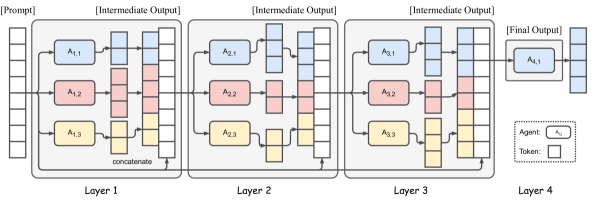
- 各レイヤーに複数の LLM エージェントを含む層状 MoA アーキテクチャを提案し、各エージェントは前のレイヤーから補助情報を受け取る。
- レイヤー内の出力を組み合わせる Aggregate-and-Synthesize prompts を定義する。
- レイヤー間でモデルを再利用し、最終的な出力を生成する Aggregator(例:Qwen1.5-110B-Chat)を用いる。
- 単一提案者配置と複数提案者配置を比較し、提案の多様性が役割に与える影響を調べる。
- MoA を Mixture-of-Experts (MoE) に関連付け、ファインチューニングなしの prompting ベースのモデルレベルのアンサンブル手法を正当化する。
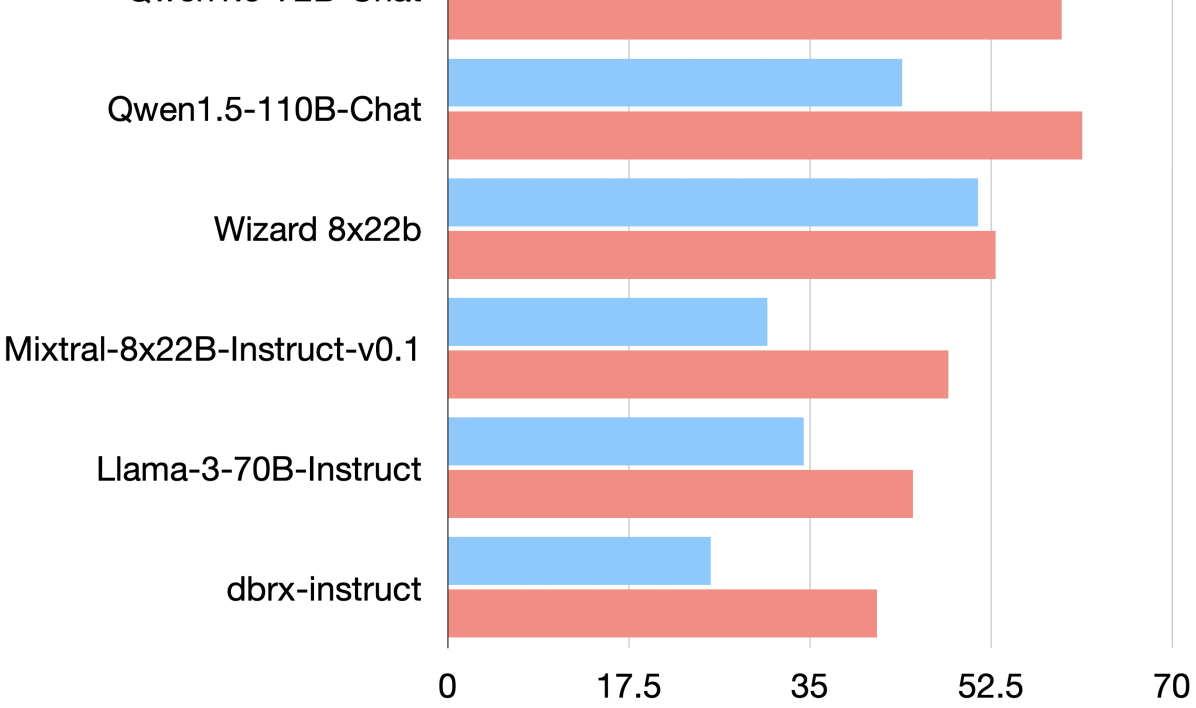
実験結果
リサーチクエスチョン
- RQ1階層化された段階で多様な LLM の混成は、標準ベンチマークで単一モデルのプロンプトを上回るか。
- RQ2MoA における提案者と集約者の役割は何で、どのモデルがこれらの役割に最も適しているか。
- RQ3提案者数とモデルの多様性は性能とコストにどう影響するか。
- RQ4MoA は LLM ベースのリランキングや他のアンサンブル手法と比較して品質と効率性においてどうか。
主な発見
- MoA はオープンソースモデルで AlpacaEval 2.0 の 65.1% LC ウィン率を達成し、GPT-4 Omni の 57.5% を上回る。
- MoA が最終集約者として GPT-4o を採用すると、65.7% LC ウィン率と 78.7% ウィンを AlpacaEval 2.0 の指標で達成する。
- MoA-Lite(層数が少ない)は AlpacaEval 2.0 で GPT-4o よりも 1.8 ポイント高く依然として上回る。
- MT-Bench では MoA がトップのリーダーボード性能を達成し、全体的な改善と初回/2回目ターンのスコアが高い。
- FLASK において MoA は アグリゲータ単独および GPT-4 Omni に比べ、頑健性、正確性、効率、事実性、メタ認知のいくつかの指標で向上。
- MoA は LLM ベースのランカー基準よりも改善を示しており、複数の提案を aggregation する方が単一提案を選択するより良い結果を生むことを示している。
- 提案者数を増やし、多様性(異なるモデル)を確保することは一貫して性能を向上させ、スケーリングの幅が有益であることを示唆する。
- 特別なモデルの役割が現れる:GPT-4o、Qwen、LLaMA-3 は提案者と集約者の両方として多用途であり、WizardLM は提案者として優れるが集約者としては効果が低い。
- 予算分析では MoA がGPT-4 Turbo の性能に近づく可能性があり、MoA-Lite は質とコストの良好なトレードオフを達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。