[論文レビュー] Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models
要約: 本論文は疎な MoE モデルが指示チューニングによって大きく恩恵を受け、より低い計算量で最先端の結果を達成していることを示す。特に Flan-MoE-32B は約1/3 の FLOPs で Flan-PaLM-62B を上回る。
Sparse Mixture-of-Experts (MoE) is a neural architecture design that can be utilized to add learnable parameters to Large Language Models (LLMs) without increasing inference cost. Instruction tuning is a technique for training LLMs to follow instructions. We advocate combining these two approaches, as we find that MoE models benefit more from instruction tuning than dense models. In particular, we conduct empirical studies across three experimental setups: (i) Direct finetuning on individual downstream tasks devoid of instruction tuning; (ii) Instructiontuning followed by in-context few-shot or zero-shot generalization on downstream tasks; and (iii) Instruction tuning supplemented by further finetuning on individual downstream tasks. In the first scenario, MoE models overall underperform dense models of identical computational capacity. This narrative, however, dramatically changes with the introduction of instruction tuning (second and third scenario), used independently or in conjunction with task-specific finetuning. Our most powerful model, FLAN-MOE-32B, surpasses the performance of FLAN-PALM-62B on four benchmark tasks, while using only a third of the FLOPs. The advancements embodied byFLAN-MOE inspire a reevaluation of the design principles of large-scale, high-performance language models in the framework of task-agnostic learning.
研究の動機と目的
- 指示チューニングが同程度の容量を持つ dense モデルと比較して MoE モデルの性能を顕著に向上させることを実証する。
- MoE モデルが指示チューニングにどのように反応するかを、直接ファインチューニング、インコンテキスト一般化、及び後続のタスク特化ファインチューニングを横断して定量化する。
- Flan-MoE のルーティング戦略、エキスパート数、補助損失を分析し、Flan-MoE のベストプラクティスを特定する。
- Flan-MoE のスケーリング挙動を dense ベースラインおよび PaLM スタイルモデルと比較し、精度と計算効iciency の観点で評価する。
- multilingual/generalization の課題と MoE 設計原理への示唆など、制約を議論する。
提案手法
- Transformer アーキテクチャでフィードフォワードネットワークを交互の層で MoE 層と置換して疎な MoE 層を採用する。
- FLAN データセット混合の prefix-LM 目的関数を用いて Flan-MoE をファインチューニングし、指定されたハイパーパラメータで全パラメータを更新する。
- MMLU、BBH、推論、QA ベンチマークをゼロショットおよび Few-shot プロンプトで評価し、正規化平均指標を含めて評価する。
- Flan-MoE を同等の dense encoder-decoder(T5)モデルとモデルサイズおよび FLOPs の観点で比較する。
- Flan-ST-32B(32B パラメータ)へスケールアップし、Flan-PaLM-62B および他のベースラインと比較して計算効率を強調する。
- アブレーションを通じてルーティング戦略(トークン選択 vs エキスパート選択)と補助損失(バランシング vs Z-loss)を調査する。

実験結果
リサーチクエスチョン
- RQ1指示チューニングは MoE モデルに対して dense モデルより大きな影響を与えるか。
- RQ2ルーティング戦略とエキスパート数は多様なベンチマークで指示チューニングされた MoE の性能にどのように影響するか。
- RQ3Flan-MoE は FLOPs を減らしつつ最先端の dense モデルと競合する性能を達成できるか。
- RQ4補助損失とパラメータ凍結が MoE 指示チューニングに及ぼす影響は何か。
- RQ5多言語シナリオにおける MoE モデルの制約とそれを緩和する方策は何か。
主な発見
- 指示チューニングは下流タスクや保持データに対する MoE の利得を dense モデルより劇的に高める。
- Flan-MoE モデルは第二・第三の実験設定で比較対象の dense に勝り、MMLU、BBH、推論、QA のベンチマークで顕著な利得を示す。
- 最大の Flan-ST-32B モデルは少数ショット性能が高く、Flan-PaLM-62B を上回りつつ、トークンあたりの FLOPs は 30% 未満で済む。
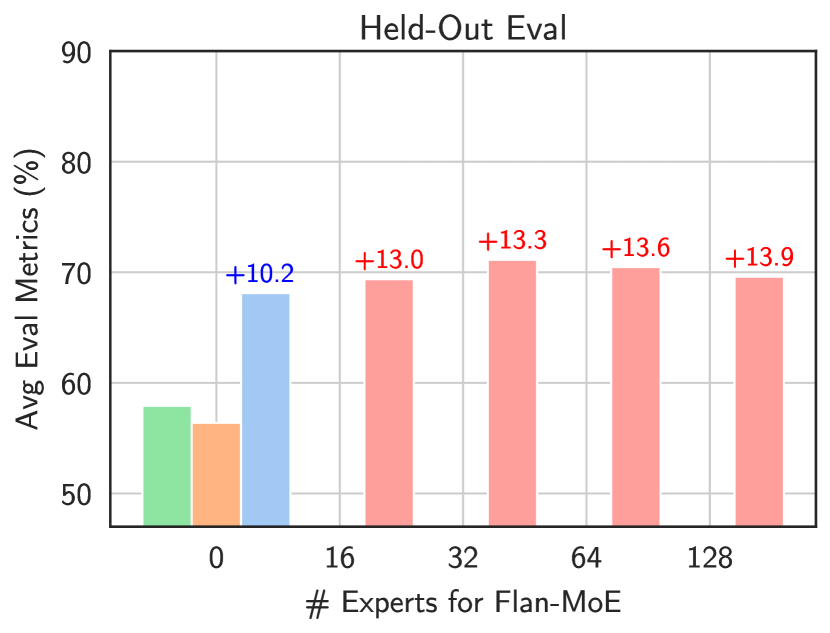
- MoE の性能はエキスパートの数とともにある程度までスケールするが、それ以降は利得が飽和し、ルーティング戦略(エキスパート選択 vs トークン選択)が結果に影響を与える。
- 指示チューニングは大規模なスケールで MoE モデルにとってより大きな恩恵をもたらし、Flan-EC(エキスパート競合)ルーティングは多くのタスクで Flan-GS(ゲートルーティング)を上回る傾向がある。
- Flan-MoE は substantial な利得を示す一方、TyDiQA、MGSM などの多言語ベンチマークは依然として弱点を露呈しており、多言語カバレッジには多様な訓練データが必要であることを示唆している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。